 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISOR: Visual Input-based Steering for Output Redirection in Vision-Language Models
Aug 11, 2025Vision Language Models (VLMs) are increasingly being used in a broad range of applications, bringing their security and behavioral control to the forefront. While existing approaches for behavioral control or output redirection, like system prompting in VLMs, are easily detectable and often ineffective, activation-based steering vectors require invasive runtime access to model internals--incompatible with API-based services and closed-source deployments. We introduce VISOR (Visual Input-based Steering for Output Redirection), a novel method that achieves sophisticated behavioral control through optimized visual inputs alone. By crafting universal steering images that induce target activation patterns, VISOR enables practical deployment across all VLM serving modalities while remaining imperceptible compared to explicit textual instructions. We validate VISOR on LLaVA-1.5-7B across three critical alignment tasks: refusal, sycophancy and survival instinct. A single 150KB steering image matches steering vector performance within 1-2% for positive behavioral shifts while dramatically exceeding it for negative steering--achieving up to 25% shifts from baseline compared to steering vectors' modest changes. Unlike system prompting (3-4% shifts), VISOR provides robust bidirectional control while maintaining 99.9% performance on 14,000 unrelated MMLU tasks. Beyond eliminating runtime overhead and model access requirements, VISOR exposes a critical security vulnerability: adversaries can achieve sophisticated behavioral manipulation through visual channels alone, bypassing text-based defenses. Our work fundamentally re-imagines multimodal model control and highlights the urgent need for defenses against visual steering attacks.
Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety
Jun 05, 2025As large language models (LLMs) see wider real-world use, understanding and mitigating their unsafe behaviors is critical. Interpretation techniques can reveal causes of unsafe outputs and guide safety, but such connections with safety are often overlooked in prior surveys. We present the first survey that bridges this gap, introducing a unified framework that connects safety-focused interpretation methods, the safety enhancements they inform, and the tools that operationalize them. Our novel taxonomy, organized by LLM workflow stages, summarizes nearly 70 works at their intersections. We conclude with open challenges and future directions. This timely survey helps researchers and practitioners navigate key advancements for safer, more interpretable LLMs.
Semi-Truths: A Large-Scale Dataset of AI-Augmented Images for Evaluating Robustness of AI-Generated Image detectors
Nov 12, 2024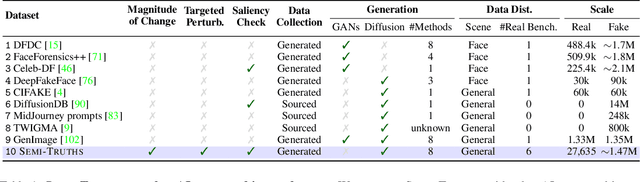
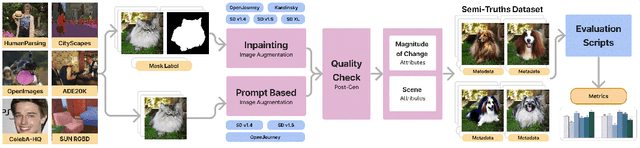

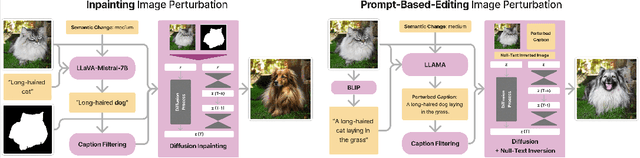
Text-to-image diffusion models have impactful applications in art, design, and entertainment, yet these technologies also pose significant risks by enabling the creation and dissemination of misinformation. Although recent advancements have produced AI-generated image detectors that claim robustness against various augmentations, their true effectiveness remains uncertain. Do these detectors reliably identify images with different levels of augmentation? Are they biased toward specific scenes or data distributions? To investigate, we introduce SEMI-TRUTHS, featuring 27,600 real images, 223,400 masks, and 1,472,700 AI-augmented images that feature targeted and localized perturbations produced using diverse augmentation techniques, diffusion models, and data distributions. Each augmented image is accompanied by metadata for standardized and targeted evaluation of detector robustness. Our findings suggest that state-of-the-art detectors exhibit varying sensitivities to the types and degrees of perturbations, data distributions, and augmentation methods used, offering new insights into their performance and limitations. The code for the augmentation and evaluation pipeline is available at https://github.com/J-Kruk/SemiTruths.
LLM Attributor: Interactive Visual Attribution for LLM Generation
Apr 01, 2024

While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023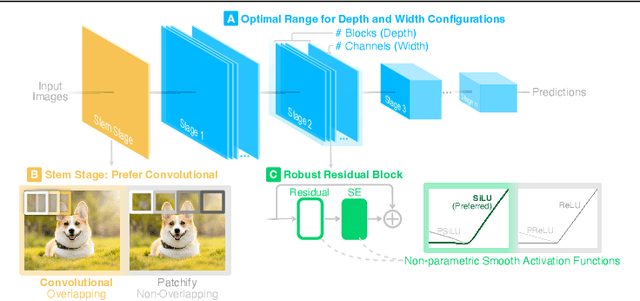
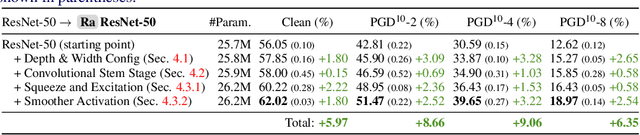
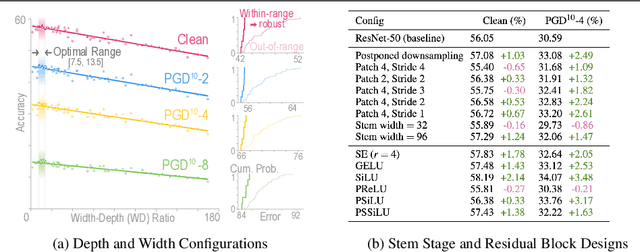

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.
LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked
Aug 15, 2023



Large language models (LLMs) have skyrocketed in popularity in recent years due to their ability to generate high-quality text in response to human prompting. However, these models have been shown to have the potential to generate harmful content in response to user prompting (e.g., giving users instructions on how to commit crimes). There has been a focus in the literature on mitigating these risks, through methods like aligning models with human values through reinforcement learning. However, it has been shown that even aligned language models are susceptible to adversarial attacks that bypass their restrictions on generating harmful text. We propose a simple approach to defending against these attacks by having a large language model filter its own responses. Our current results show that even if a model is not fine-tuned to be aligned with human values, it is possible to stop it from presenting harmful content to users by validating the content using a language model.