 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Personalized Agents from Human Feedback
Feb 18, 2026Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.
Semi-Truths: A Large-Scale Dataset of AI-Augmented Images for Evaluating Robustness of AI-Generated Image detectors
Nov 12, 2024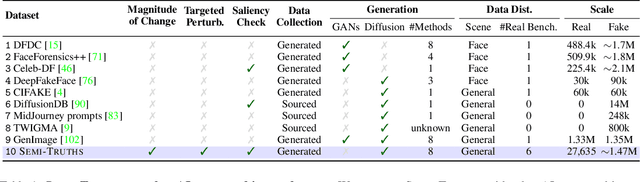
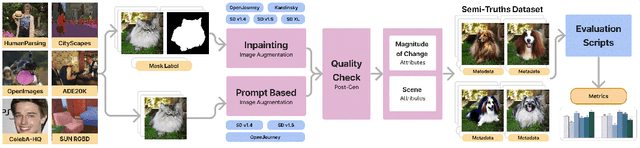

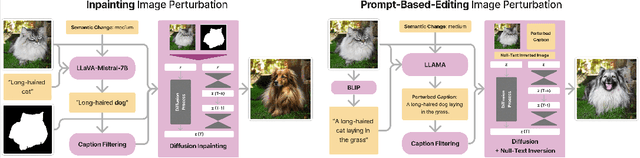
Text-to-image diffusion models have impactful applications in art, design, and entertainment, yet these technologies also pose significant risks by enabling the creation and dissemination of misinformation. Although recent advancements have produced AI-generated image detectors that claim robustness against various augmentations, their true effectiveness remains uncertain. Do these detectors reliably identify images with different levels of augmentation? Are they biased toward specific scenes or data distributions? To investigate, we introduce SEMI-TRUTHS, featuring 27,600 real images, 223,400 masks, and 1,472,700 AI-augmented images that feature targeted and localized perturbations produced using diverse augmentation techniques, diffusion models, and data distributions. Each augmented image is accompanied by metadata for standardized and targeted evaluation of detector robustness. Our findings suggest that state-of-the-art detectors exhibit varying sensitivities to the types and degrees of perturbations, data distributions, and augmentation methods used, offering new insights into their performance and limitations. The code for the augmentation and evaluation pipeline is available at https://github.com/J-Kruk/SemiTruths.
Silent Signals, Loud Impact: LLMs for Word-Sense Disambiguation of Coded Dog Whistles
Jun 10, 2024


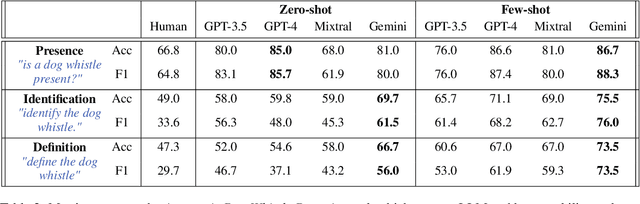
A dog whistle is a form of coded communication that carries a secondary meaning to specific audiences and is often weaponized for racial and socioeconomic discrimination. Dog whistling historically originated from United States politics, but in recent years has taken root in social media as a means of evading hate speech detection systems and maintaining plausible deniability. In this paper, we present an approach for word-sense disambiguation of dog whistles from standard speech using Large Language Models (LLMs), and leverage this technique to create a dataset of 16,550 high-confidence coded examples of dog whistles used in formal and informal communication. Silent Signals is the largest dataset of disambiguated dog whistle usage, created for applications in hate speech detection, neology, and political science. The dataset can be found at https://huggingface.co/datasets/SALT-NLP/silent_signals.
Impressions: Understanding Visual Semiotics and Aesthetic Impact
Oct 27, 2023



Is aesthetic impact different from beauty? Is visual salience a reflection of its capacity for effective communication? We present Impressions, a novel dataset through which to investigate the semiotics of images, and how specific visual features and design choices can elicit specific emotions, thoughts and beliefs. We posit that the impactfulness of an image extends beyond formal definitions of aesthetics, to its success as a communicative act, where style contributes as much to meaning formation as the subject matter. However, prior image captioning datasets are not designed to empower state-of-the-art architectures to model potential human impressions or interpretations of images. To fill this gap, we design an annotation task heavily inspired by image analysis techniques in the Visual Arts to collect 1,440 image-caption pairs and 4,320 unique annotations exploring impact, pragmatic image description, impressions, and aesthetic design choices. We show that existing multimodal image captioning and conditional generation models struggle to simulate plausible human responses to images. However, this dataset significantly improves their ability to model impressions and aesthetic evaluations of images through fine-tuning and few-shot adaptation.
Integrating Text and Image: Determining Multimodal Document Intent in Instagram Posts
Apr 19, 2019
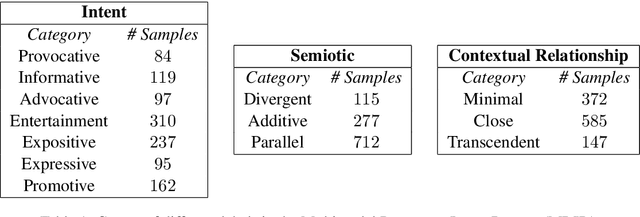

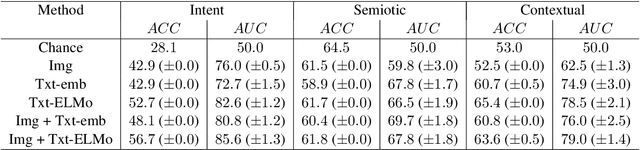
Computing author intent from multimodal data like Instagram posts requires modeling a complex relationship between text and image. For example a caption might reflect ironically on the image, so neither the caption nor the image is a mere transcript of the other. Instead they combine -- via what has been called meaning multiplication -- to create a new meaning that has a more complex relation to the literal meanings of text and image. Here we introduce a multimodal dataset of 1299 Instagram post labeled for three orthogonal taxonomies: the authorial intent behind the image-caption pair, the contextual relationship between the literal meanings of the image and caption, and the semiotic relationship between the signified meanings of the image and caption. We build a baseline deep multimodal classifier to validate the taxonomy, showing that employing both text and image improves intent detection by 8% compared to using only image modality, demonstrating the commonality of non-intersective meaning multiplication. Our dataset offers an important resource for the study of the rich meanings that results from pairing text and image.