 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Confusion and Affective States Under Communication Failures in Voice-Based Human-Machine Interaction
Jul 15, 2022



We present a series of two studies conducted to understand user's affective states during voice-based human-machine interactions. Emphasis is placed on the cases of communication errors or failures. In particular, we are interested in understanding "confusion" in relation with other affective states. The studies consist of two types of tasks: (1) related to communication with a voice-based virtual agent: speaking to the machine and understanding what the machine says, (2) non-communication related, problem-solving tasks where the participants solve puzzles and riddles but are asked to verbally explain the answers to the machine. We collected audio-visual data and self-reports of affective states of the participants. We report results of two studies and analysis of the collected data. The first study was analyzed based on the annotator's observation, and the second study was analyzed based on the self-report.
Integrating Text and Image: Determining Multimodal Document Intent in Instagram Posts
Apr 19, 2019
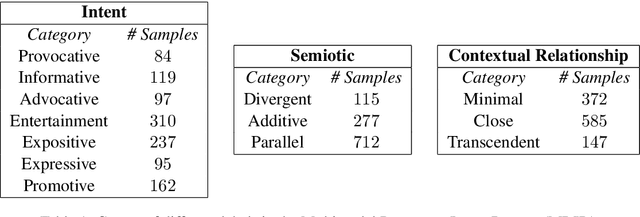

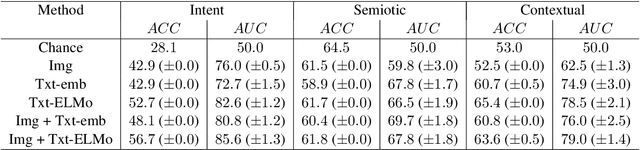
Computing author intent from multimodal data like Instagram posts requires modeling a complex relationship between text and image. For example a caption might reflect ironically on the image, so neither the caption nor the image is a mere transcript of the other. Instead they combine -- via what has been called meaning multiplication -- to create a new meaning that has a more complex relation to the literal meanings of text and image. Here we introduce a multimodal dataset of 1299 Instagram post labeled for three orthogonal taxonomies: the authorial intent behind the image-caption pair, the contextual relationship between the literal meanings of the image and caption, and the semiotic relationship between the signified meanings of the image and caption. We build a baseline deep multimodal classifier to validate the taxonomy, showing that employing both text and image improves intent detection by 8% compared to using only image modality, demonstrating the commonality of non-intersective meaning multiplication. Our dataset offers an important resource for the study of the rich meanings that results from pairing text and image.