 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Human Body Model based ID using Shape and Pose Parameters
Dec 06, 2023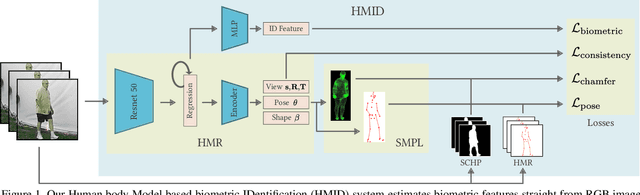
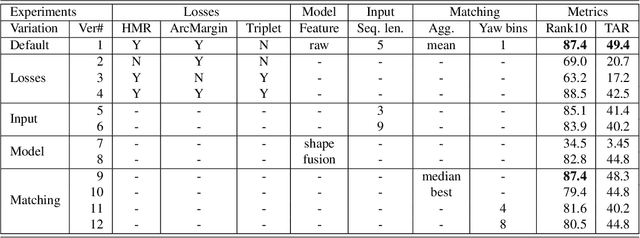


We present a Human Body model based IDentification system (HMID) system that is jointly trained for shape, pose and biometric identification. HMID is based on the Human Mesh Recovery (HMR) network and we propose additional losses to improve and stabilize shape estimation and biometric identification while maintaining the pose and shape output. We show that when our HMID network is trained using additional shape and pose losses, it shows a significant improvement in biometric identification performance when compared to an identical model that does not use such losses. The HMID model uses raw images instead of silhouettes and is able to perform robust recognition on images collected at range and altitude as many anthropometric properties are reasonably invariant to clothing, view and range. We show results on the USF dataset as well as the BRIAR dataset which includes probes with both clothing and view changes. Our approach (using body model losses) shows a significant improvement in Rank20 accuracy and True Accuracy Rate on the BRIAR evaluation dataset.
Towards Understanding Confusion and Affective States Under Communication Failures in Voice-Based Human-Machine Interaction
Jul 15, 2022



We present a series of two studies conducted to understand user's affective states during voice-based human-machine interactions. Emphasis is placed on the cases of communication errors or failures. In particular, we are interested in understanding "confusion" in relation with other affective states. The studies consist of two types of tasks: (1) related to communication with a voice-based virtual agent: speaking to the machine and understanding what the machine says, (2) non-communication related, problem-solving tasks where the participants solve puzzles and riddles but are asked to verbally explain the answers to the machine. We collected audio-visual data and self-reports of affective states of the participants. We report results of two studies and analysis of the collected data. The first study was analyzed based on the annotator's observation, and the second study was analyzed based on the self-report.
Learning Invariant World State Representations with Predictive Coding
Jul 06, 2022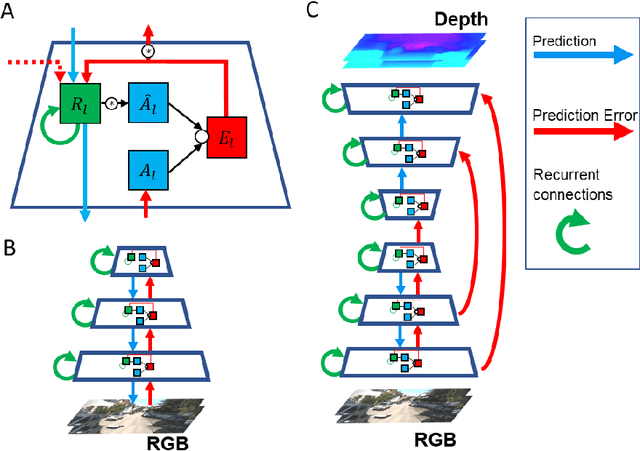


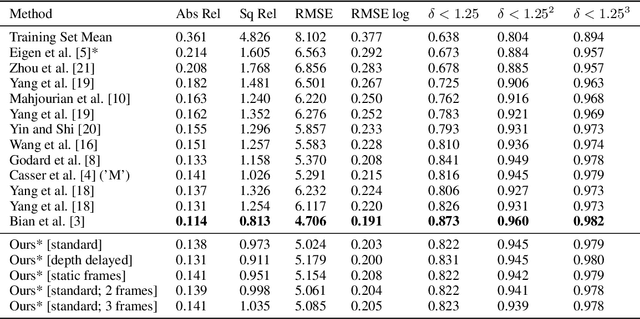
Self-supervised learning methods overcome the key bottleneck for building more capable AI: limited availability of labeled data. However, one of the drawbacks of self-supervised architectures is that the representations that they learn are implicit and it is hard to extract meaningful information about the encoded world states, such as 3D structure of the visual scene encoded in a depth map. Moreover, in the visual domain such representations only rarely undergo evaluations that may be critical for downstream tasks, such as vision for autonomous cars. Herein, we propose a framework for evaluating visual representations for illumination invariance in the context of depth perception. We develop a new predictive coding-based architecture and a hybrid fully-supervised/self-supervised learning method. We propose a novel architecture that extends the predictive coding approach: PRedictive Lateral bottom-Up and top-Down Encoder-decoder Network (PreludeNet), which explicitly learns to infer and predict depth from video frames. In PreludeNet, the encoder's stack of predictive coding layers is trained in a self-supervised manner, while the predictive decoder is trained in a supervised manner to infer or predict the depth. We evaluate the robustness of our model on a new synthetic dataset, in which lighting conditions (such as overall illumination, and effect of shadows) can be be parametrically adjusted while keeping all other aspects of the world constant. PreludeNet achieves both competitive depth inference performance and next frame prediction accuracy. We also show how this new network architecture, coupled with the hybrid fully-supervised/self-supervised learning method, achieves balance between the said performance and invariance to changes in lighting. The proposed framework for evaluating visual representations can be extended to diverse task domains and invariance tests.
"How to best say it?" : Translating Directives in Machine Language into Natural Language in the Blocks World
Jul 14, 2021



We propose a method to generate optimal natural language for block placement directives generated by a machine's planner during human-agent interactions in the blocks world. A non user-friendly machine directive, e.g., move(ObjId, toPos), is transformed into visually and contextually grounded referring expressions that are much easier for the user to comprehend. We describe an algorithm that progressively and generatively transforms the machine's directive in ECI (Elementary Composable Ideas)-space, generating many alternative versions of the directive. We then define a cost function to evaluate the ease of comprehension of these alternatives and select the best option. The parameters for this cost function were derived empirically from a user study that measured utterance-to-action timings.
Towards Explainable Student Group Collaboration Assessment Models Using Temporal Representations of Individual Student Roles
Jun 17, 2021
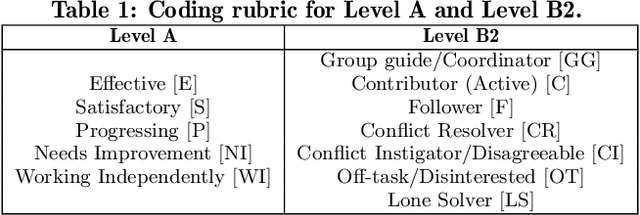

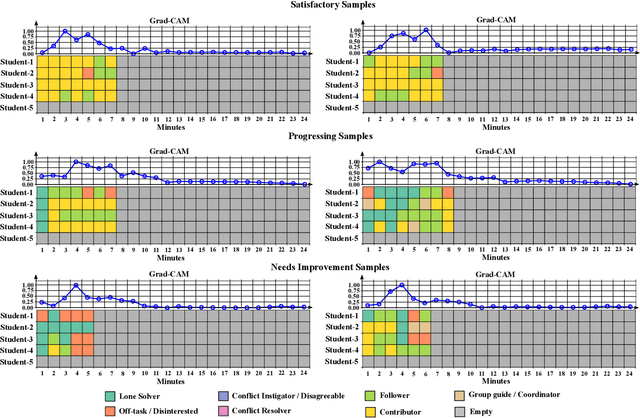
Collaboration is identified as a required and necessary skill for students to be successful in the fields of Science, Technology, Engineering and Mathematics (STEM). However, due to growing student population and limited teaching staff it is difficult for teachers to provide constructive feedback and instill collaborative skills using instructional methods. Development of simple and easily explainable machine-learning-based automated systems can help address this problem. Improving upon our previous work, in this paper we propose using simple temporal-CNN deep-learning models to assess student group collaboration that take in temporal representations of individual student roles as input. We check the applicability of dynamically changing feature representations for student group collaboration assessment and how they impact the overall performance. We also use Grad-CAM visualizations to better understand and interpret the important temporal indices that led to the deep-learning model's decision.
A Machine Learning Approach to Assess Student Group Collaboration Using Individual Level Behavioral Cues
Aug 05, 2020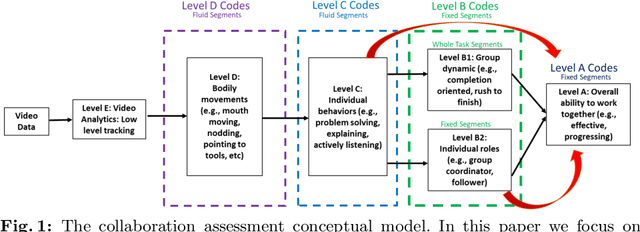


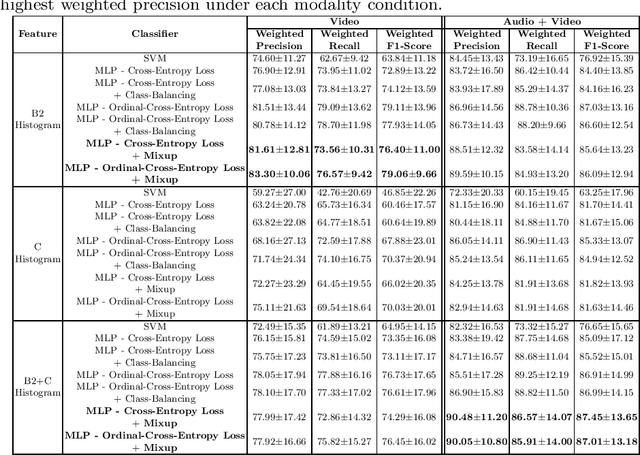
K-12 classrooms consistently integrate collaboration as part of their learning experiences. However, owing to large classroom sizes, teachers do not have the time to properly assess each student and give them feedback. In this paper we propose using simple deep-learning-based machine learning models to automatically determine the overall collaboration quality of a group based on annotations of individual roles and individual level behavior of all the students in the group. We come across the following challenges when building these models: 1) Limited training data, 2) Severe class label imbalance. We address these challenges by using a controlled variant of Mixup data augmentation, a method for generating additional data samples by linearly combining different pairs of data samples and their corresponding class labels. Additionally, the label space for our problem exhibits an ordered structure. We take advantage of this fact and also explore using an ordinal-cross-entropy loss function and study its effects with and without Mixup.