 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Quantized Deep Neural Networks to White-Box Attacks using Stochastic Quantization and Information-Theoretic Ensemble Training
Nov 30, 2023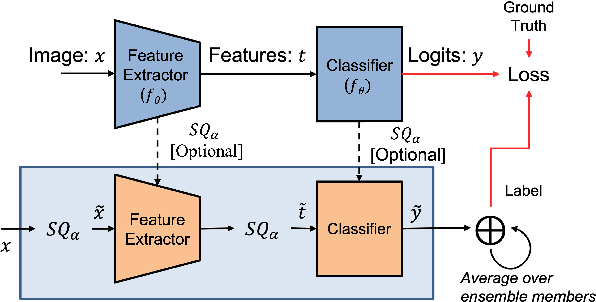



Most real-world applications that employ deep neural networks (DNNs) quantize them to low precision to reduce the compute needs. We present a method to improve the robustness of quantized DNNs to white-box adversarial attacks. We first tackle the limitation of deterministic quantization to fixed ``bins'' by introducing a differentiable Stochastic Quantizer (SQ). We explore the hypothesis that different quantizations may collectively be more robust than each quantized DNN. We formulate a training objective to encourage different quantized DNNs to learn different representations of the input image. The training objective captures diversity and accuracy via mutual information between ensemble members. Through experimentation, we demonstrate substantial improvement in robustness against $L_\infty$ attacks even if the attacker is allowed to backpropagate through SQ (e.g., > 50\% accuracy to PGD(5/255) on CIFAR10 without adversarial training), compared to vanilla DNNs as well as existing ensembles of quantized DNNs. We extend the method to detect attacks and generate robustness profiles in the adversarial information plane (AIP), towards a unified analysis of different threat models by correlating the MI and accuracy.
Learning Invariant World State Representations with Predictive Coding
Jul 06, 2022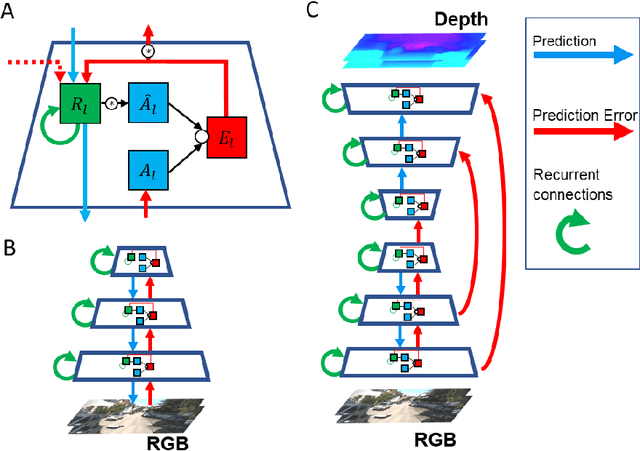


Self-supervised learning methods overcome the key bottleneck for building more capable AI: limited availability of labeled data. However, one of the drawbacks of self-supervised architectures is that the representations that they learn are implicit and it is hard to extract meaningful information about the encoded world states, such as 3D structure of the visual scene encoded in a depth map. Moreover, in the visual domain such representations only rarely undergo evaluations that may be critical for downstream tasks, such as vision for autonomous cars. Herein, we propose a framework for evaluating visual representations for illumination invariance in the context of depth perception. We develop a new predictive coding-based architecture and a hybrid fully-supervised/self-supervised learning method. We propose a novel architecture that extends the predictive coding approach: PRedictive Lateral bottom-Up and top-Down Encoder-decoder Network (PreludeNet), which explicitly learns to infer and predict depth from video frames. In PreludeNet, the encoder's stack of predictive coding layers is trained in a self-supervised manner, while the predictive decoder is trained in a supervised manner to infer or predict the depth. We evaluate the robustness of our model on a new synthetic dataset, in which lighting conditions (such as overall illumination, and effect of shadows) can be be parametrically adjusted while keeping all other aspects of the world constant. PreludeNet achieves both competitive depth inference performance and next frame prediction accuracy. We also show how this new network architecture, coupled with the hybrid fully-supervised/self-supervised learning method, achieves balance between the said performance and invariance to changes in lighting. The proposed framework for evaluating visual representations can be extended to diverse task domains and invariance tests.
A Study on Multimodal and Interactive Explanations for Visual Question Answering
Mar 01, 2020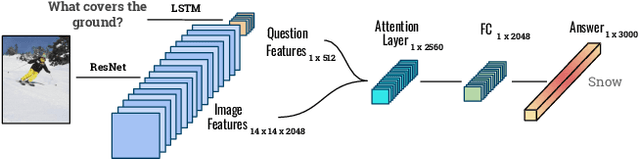
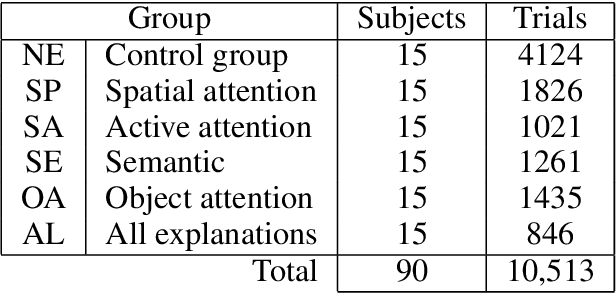

Explainability and interpretability of AI models is an essential factor affecting the safety of AI. While various explainable AI (XAI) approaches aim at mitigating the lack of transparency in deep networks, the evidence of the effectiveness of these approaches in improving usability, trust, and understanding of AI systems are still missing. We evaluate multimodal explanations in the setting of a Visual Question Answering (VQA) task, by asking users to predict the response accuracy of a VQA agent with and without explanations. We use between-subjects and within-subjects experiments to probe explanation effectiveness in terms of improving user prediction accuracy, confidence, and reliance, among other factors. The results indicate that the explanations help improve human prediction accuracy, especially in trials when the VQA system's answer is inaccurate. Furthermore, we introduce active attention, a novel method for evaluating causal attentional effects through intervention by editing attention maps. User explanation ratings are strongly correlated with human prediction accuracy and suggest the efficacy of these explanations in human-machine AI collaboration tasks.
* http://ceur-ws.org/Vol-2560/paper44.pdf
Generating Natural Language Explanations for Visual Question Answering using Scene Graphs and Visual Attention
Feb 15, 2019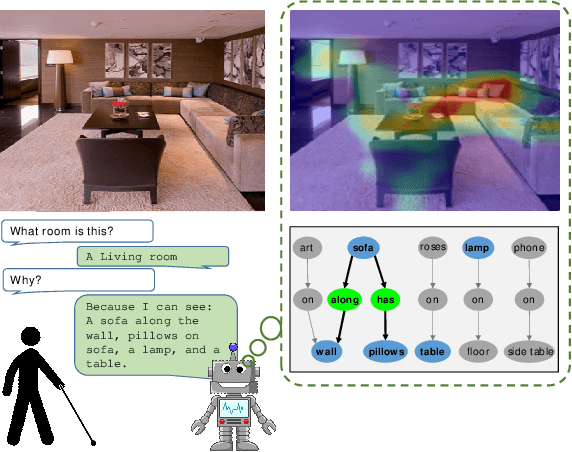
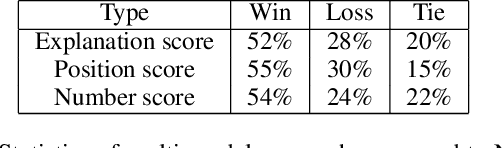

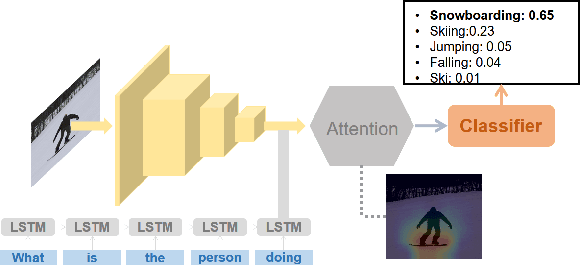
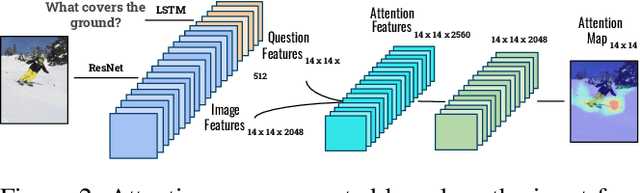
In this paper, we present a novel approach for the task of eXplainable Question Answering (XQA), i.e., generating natural language (NL) explanations for the Visual Question Answering (VQA) problem. We generate NL explanations comprising of the evidence to support the answer to a question asked to an image using two sources of information: (a) annotations of entities in an image (e.g., object labels, region descriptions, relation phrases) generated from the scene graph of the image, and (b) the attention map generated by a VQA model when answering the question. We show how combining the visual attention map with the NL representation of relevant scene graph entities, carefully selected using a language model, can give reasonable textual explanations without the need of any additional collected data (explanation captions, etc). We run our algorithms on the Visual Genome (VG) dataset and conduct internal user-studies to demonstrate the efficacy of our approach over a strong baseline. We have also released a live web demo showcasing our VQA and textual explanation generation using scene graphs and visual attention.