 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Natural Language Explanations for Visual Question Answering using Scene Graphs and Visual Attention
Paper and Code
Feb 15, 2019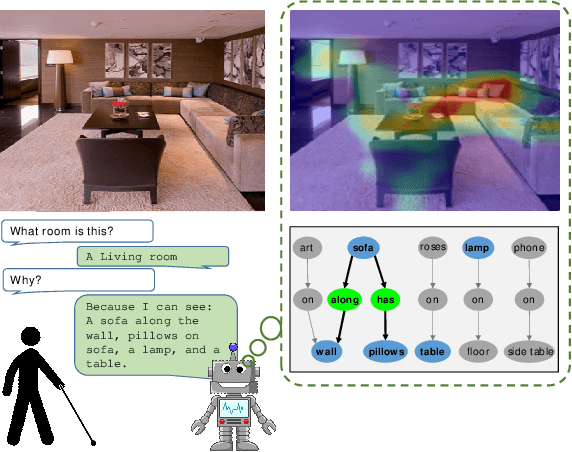
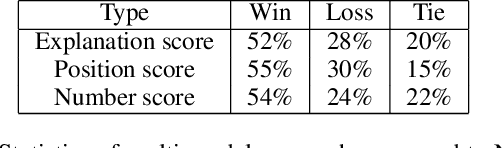

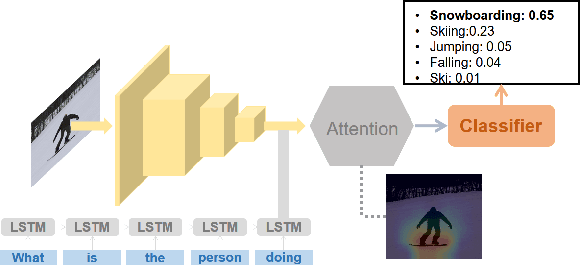
In this paper, we present a novel approach for the task of eXplainable Question Answering (XQA), i.e., generating natural language (NL) explanations for the Visual Question Answering (VQA) problem. We generate NL explanations comprising of the evidence to support the answer to a question asked to an image using two sources of information: (a) annotations of entities in an image (e.g., object labels, region descriptions, relation phrases) generated from the scene graph of the image, and (b) the attention map generated by a VQA model when answering the question. We show how combining the visual attention map with the NL representation of relevant scene graph entities, carefully selected using a language model, can give reasonable textual explanations without the need of any additional collected data (explanation captions, etc). We run our algorithms on the Visual Genome (VG) dataset and conduct internal user-studies to demonstrate the efficacy of our approach over a strong baseline. We have also released a live web demo showcasing our VQA and textual explanation generation using scene graphs and visual attention.