 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What VQA Does Not: Pointing to Error-Inducing Regions to Improve Explanation Helpfulness
Mar 31, 2021
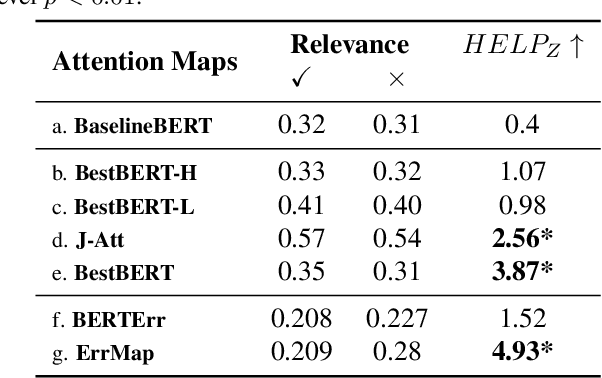

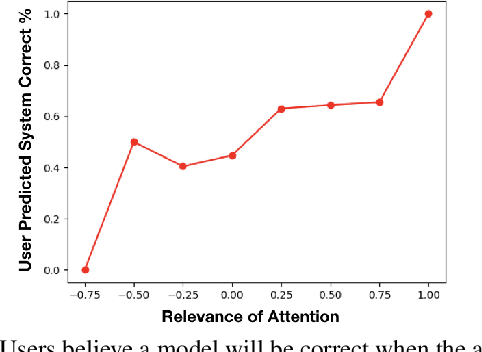
Attention maps, a popular heatmap-based explanation method for Visual Question Answering (VQA), are supposed to help users understand the model by highlighting portions of the image/question used by the model to infer answers. However, we see that users are often misled by current attention map visualizations that point to relevant regions despite the model producing an incorrect answer. Hence, we propose Error Maps that clarify the error by highlighting image regions where the model is prone to err. Error maps can indicate when a correctly attended region may be processed incorrectly leading to an incorrect answer, and hence, improve users' understanding of those cases. To evaluate our new explanations, we further introduce a metric that simulates users' interpretation of explanations to evaluate their potential helpfulness to understand model correctness. We finally conduct user studies to see that our new explanations help users understand model correctness better than baselines by an expected 30% and that our proxy helpfulness metrics correlate strongly ($\rho$>0.97) with how well users can predict model correctness.
Hybrid Consistency Training with Prototype Adaptation for Few-Shot Learning
Nov 19, 2020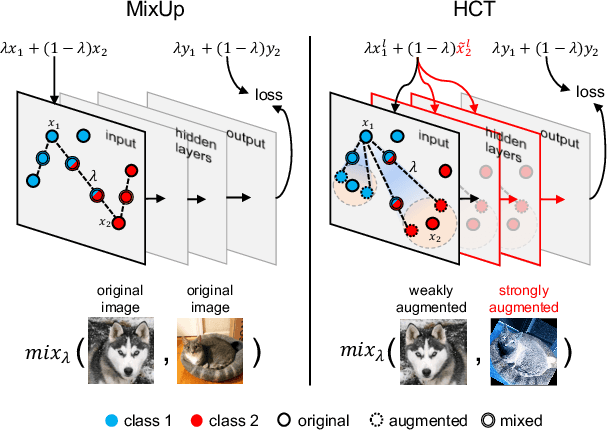
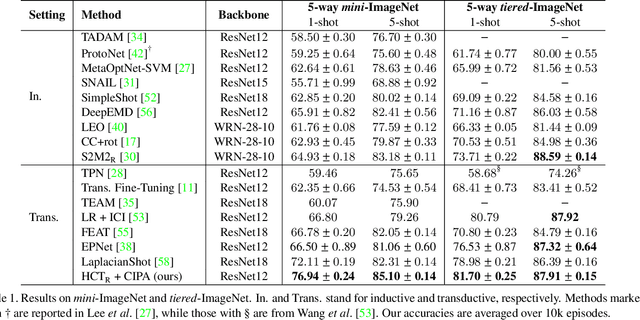
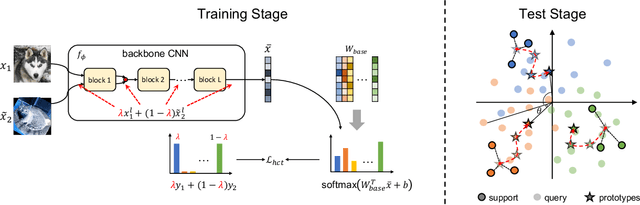
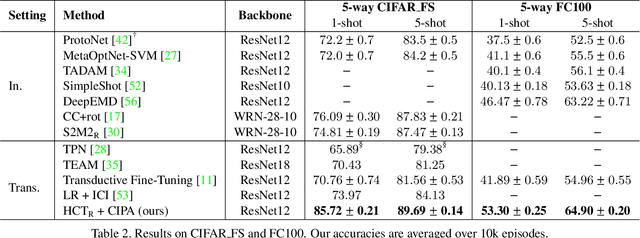
Few-Shot Learning (FSL) aims to improve a model's generalization capability in low data regimes. Recent FSL works have made steady progress via metric learning, meta learning, representation learning, etc. However, FSL remains challenging due to the following longstanding difficulties. 1) The seen and unseen classes are disjoint, resulting in a distribution shift between training and testing. 2) During testing, labeled data of previously unseen classes is sparse, making it difficult to reliably extrapolate from labeled support examples to unlabeled query examples. To tackle the first challenge, we introduce Hybrid Consistency Training to jointly leverage interpolation consistency, including interpolating hidden features, that imposes linear behavior locally and data augmentation consistency that learns robust embeddings against sample variations. As for the second challenge, we use unlabeled examples to iteratively normalize features and adapt prototypes, as opposed to commonly used one-time update, for more reliable prototype-based transductive inference. We show that our method generates a 2% to 5% improvement over the state-of-the-art methods with similar backbones on five FSL datasets and, more notably, a 7% to 8% improvement for more challenging cross-domain FSL.
A Study on Multimodal and Interactive Explanations for Visual Question Answering
Mar 01, 2020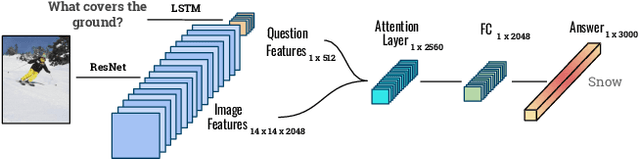
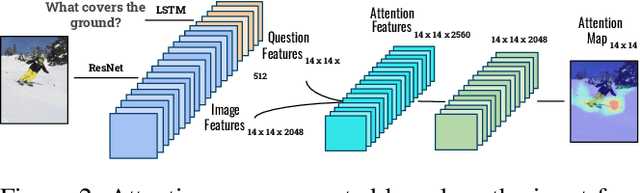

Explainability and interpretability of AI models is an essential factor affecting the safety of AI. While various explainable AI (XAI) approaches aim at mitigating the lack of transparency in deep networks, the evidence of the effectiveness of these approaches in improving usability, trust, and understanding of AI systems are still missing. We evaluate multimodal explanations in the setting of a Visual Question Answering (VQA) task, by asking users to predict the response accuracy of a VQA agent with and without explanations. We use between-subjects and within-subjects experiments to probe explanation effectiveness in terms of improving user prediction accuracy, confidence, and reliance, among other factors. The results indicate that the explanations help improve human prediction accuracy, especially in trials when the VQA system's answer is inaccurate. Furthermore, we introduce active attention, a novel method for evaluating causal attentional effects through intervention by editing attention maps. User explanation ratings are strongly correlated with human prediction accuracy and suggest the efficacy of these explanations in human-machine AI collaboration tasks.
* http://ceur-ws.org/Vol-2560/paper44.pdf
Sunny and Dark Outside?! Improving Answer Consistency in VQA through Entailed Question Generation
Sep 10, 2019

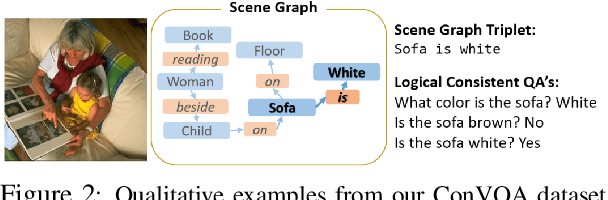

While models for Visual Question Answering (VQA) have steadily improved over the years, interacting with one quickly reveals that these models lack consistency. For instance, if a model answers "red" to "What color is the balloon?", it might answer "no" if asked, "Is the balloon red?". These responses violate simple notions of entailment and raise questions about how effectively VQA models ground language. In this work, we introduce a dataset, ConVQA, and metrics that enable quantitative evaluation of consistency in VQA. For a given observable fact in an image (e.g. the balloon's color), we generate a set of logically consistent question-answer (QA) pairs (e.g. Is the balloon red?) and also collect a human-annotated set of common-sense based consistent QA pairs (e.g. Is the balloon the same color as tomato sauce?). Further, we propose a consistency-improving data augmentation module, a Consistency Teacher Module (CTM). CTM automatically generates entailed (or similar-intent) questions for a source QA pair and fine-tunes the VQA model if the VQA's answer to the entailed question is consistent with the source QA pair. We demonstrate that our CTM-based training improves the consistency of VQA models on the ConVQA datasets and is a strong baseline for further research.
Lucid Explanations Help: Using a Human-AI Image-Guessing Game to Evaluate Machine Explanation Helpfulness
Apr 09, 2019



While there have been many proposals on how to make AI algorithms more transparent, few have attempted to evaluate the impact of AI explanations on human performance on a task using AI. We propose a Twenty-Questions style collaborative image guessing game, Explanation-assisted Guess Which (ExAG) as a method of evaluating the efficacy of explanations in the context of Visual Question Answering (VQA) - the task of answering natural language questions on images. We study the effect of VQA agent explanations on the game performance as a function of explanation type and quality. We observe that "helpful" explanations are conducive to game performance (by almost 22% for "excellent" rated explanation games), and having at least one "correct" explanation is significantly helpful when VQA system answers are mostly noisy (by almost 30% compared to no explanation games). We also see that players develop a preference for explanations even when penalized and that the explanations are mostly rated as "helpful".
Generating Natural Language Explanations for Visual Question Answering using Scene Graphs and Visual Attention
Feb 15, 2019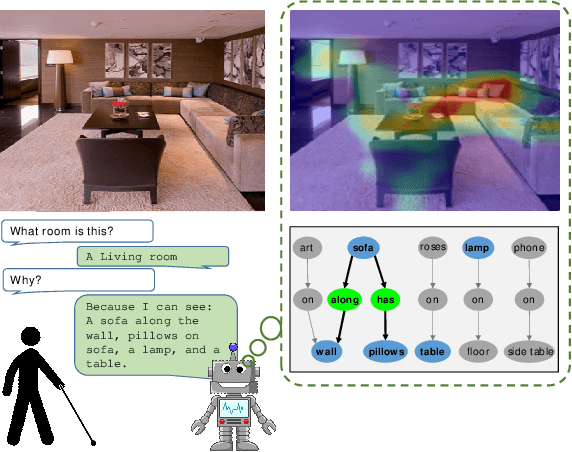

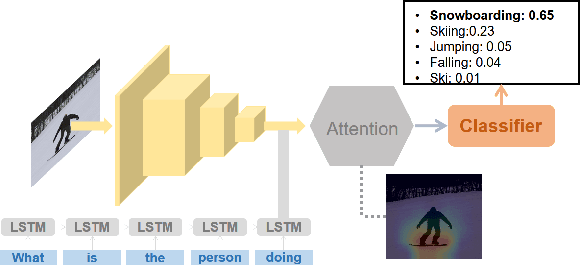
In this paper, we present a novel approach for the task of eXplainable Question Answering (XQA), i.e., generating natural language (NL) explanations for the Visual Question Answering (VQA) problem. We generate NL explanations comprising of the evidence to support the answer to a question asked to an image using two sources of information: (a) annotations of entities in an image (e.g., object labels, region descriptions, relation phrases) generated from the scene graph of the image, and (b) the attention map generated by a VQA model when answering the question. We show how combining the visual attention map with the NL representation of relevant scene graph entities, carefully selected using a language model, can give reasonable textual explanations without the need of any additional collected data (explanation captions, etc). We run our algorithms on the Visual Genome (VG) dataset and conduct internal user-studies to demonstrate the efficacy of our approach over a strong baseline. We have also released a live web demo showcasing our VQA and textual explanation generation using scene graphs and visual attention.