 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Consistency Training with Prototype Adaptation for Few-Shot Learning
Paper and Code
Nov 19, 2020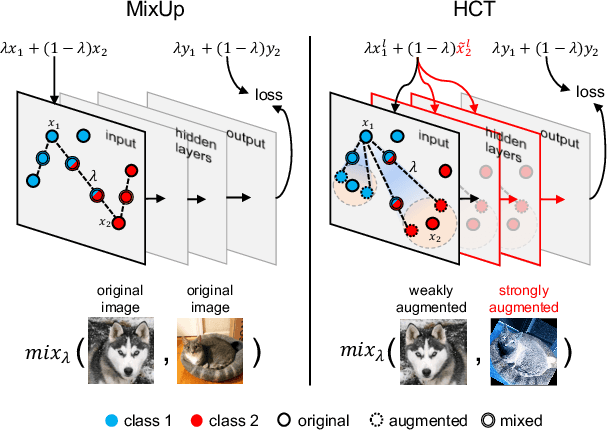
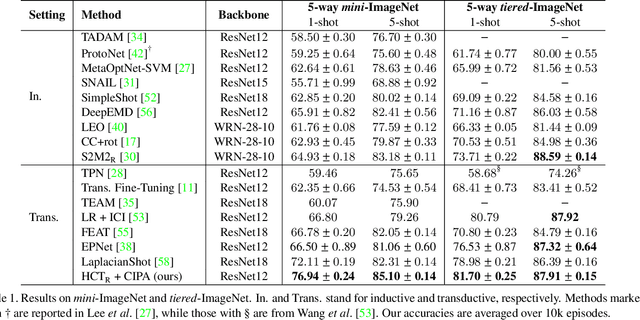
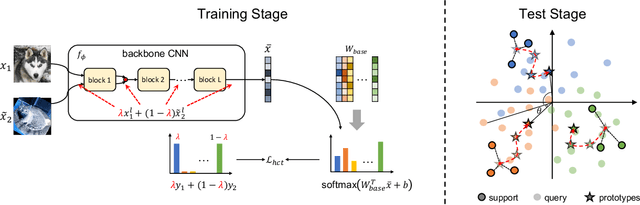
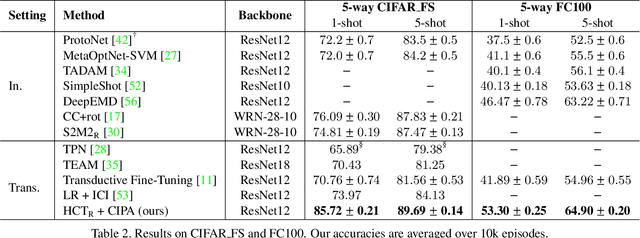
Few-Shot Learning (FSL) aims to improve a model's generalization capability in low data regimes. Recent FSL works have made steady progress via metric learning, meta learning, representation learning, etc. However, FSL remains challenging due to the following longstanding difficulties. 1) The seen and unseen classes are disjoint, resulting in a distribution shift between training and testing. 2) During testing, labeled data of previously unseen classes is sparse, making it difficult to reliably extrapolate from labeled support examples to unlabeled query examples. To tackle the first challenge, we introduce Hybrid Consistency Training to jointly leverage interpolation consistency, including interpolating hidden features, that imposes linear behavior locally and data augmentation consistency that learns robust embeddings against sample variations. As for the second challenge, we use unlabeled examples to iteratively normalize features and adapt prototypes, as opposed to commonly used one-time update, for more reliable prototype-based transductive inference. We show that our method generates a 2% to 5% improvement over the state-of-the-art methods with similar backbones on five FSL datasets and, more notably, a 7% to 8% improvement for more challenging cross-domain FSL.