 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSunny and Dark Outside?! Improving Answer Consistency in VQA through Entailed Question Generation
Paper and Code
Sep 10, 2019

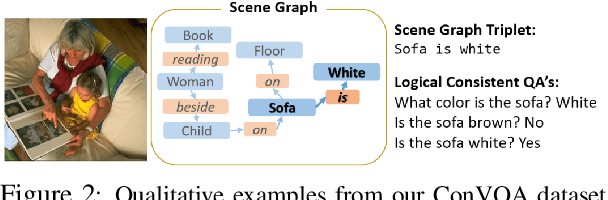

While models for Visual Question Answering (VQA) have steadily improved over the years, interacting with one quickly reveals that these models lack consistency. For instance, if a model answers "red" to "What color is the balloon?", it might answer "no" if asked, "Is the balloon red?". These responses violate simple notions of entailment and raise questions about how effectively VQA models ground language. In this work, we introduce a dataset, ConVQA, and metrics that enable quantitative evaluation of consistency in VQA. For a given observable fact in an image (e.g. the balloon's color), we generate a set of logically consistent question-answer (QA) pairs (e.g. Is the balloon red?) and also collect a human-annotated set of common-sense based consistent QA pairs (e.g. Is the balloon the same color as tomato sauce?). Further, we propose a consistency-improving data augmentation module, a Consistency Teacher Module (CTM). CTM automatically generates entailed (or similar-intent) questions for a source QA pair and fine-tunes the VQA model if the VQA's answer to the entailed question is consistent with the source QA pair. We demonstrate that our CTM-based training improves the consistency of VQA models on the ConVQA datasets and is a strong baseline for further research.