 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Counterfactuals With Shapley Values To Explain Image Models
Jun 14, 2022
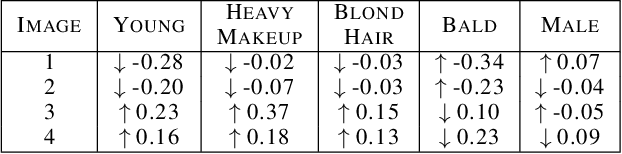
With the widespread use of sophisticated machine learning models in sensitive applications, understanding their decision-making has become an essential task. Models trained on tabular data have witnessed significant progress in explanations of their underlying decision making processes by virtue of having a small number of discrete features. However, applying these methods to high-dimensional inputs such as images is not a trivial task. Images are composed of pixels at an atomic level and do not carry any interpretability by themselves. In this work, we seek to use annotated high-level interpretable features of images to provide explanations. We leverage the Shapley value framework from Game Theory, which has garnered wide acceptance in general XAI problems. By developing a pipeline to generate counterfactuals and subsequently using it to estimate Shapley values, we obtain contrastive and interpretable explanations with strong axiomatic guarantees.
Explaining Image Classifiers Using Contrastive Counterfactuals in Generative Latent Spaces
Jun 10, 2022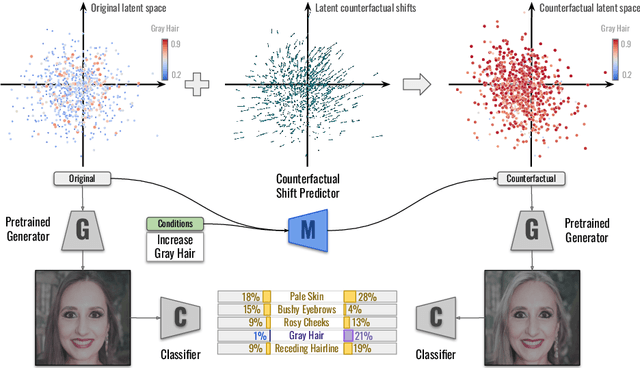


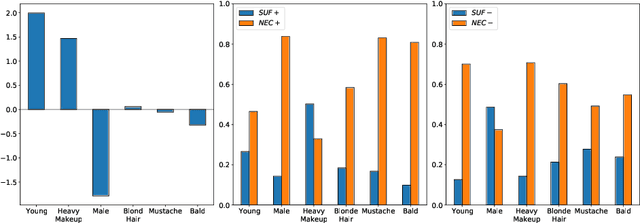
Despite their high accuracies, modern complex image classifiers cannot be trusted for sensitive tasks due to their unknown decision-making process and potential biases. Counterfactual explanations are very effective in providing transparency for these black-box algorithms. Nevertheless, generating counterfactuals that can have a consistent impact on classifier outputs and yet expose interpretable feature changes is a very challenging task. We introduce a novel method to generate causal and yet interpretable counterfactual explanations for image classifiers using pretrained generative models without any re-training or conditioning. The generative models in this technique are not bound to be trained on the same data as the target classifier. We use this framework to obtain contrastive and causal sufficiency and necessity scores as global explanations for black-box classifiers. On the task of face attribute classification, we show how different attributes influence the classifier output by providing both causal and contrastive feature attributions, and the corresponding counterfactual images.
Improving Users' Mental Model with Attention-directed Counterfactual Edits
Oct 15, 2021


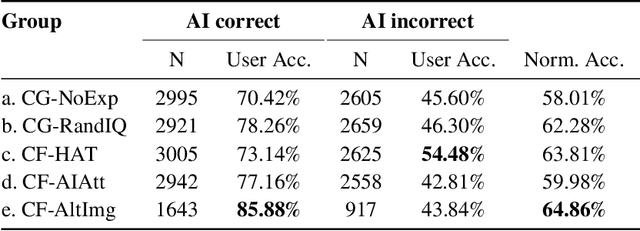
In the domain of Visual Question Answering (VQA), studies have shown improvement in users' mental model of the VQA system when they are exposed to examples of how these systems answer certain Image-Question (IQ) pairs. In this work, we show that showing controlled counterfactual image-question examples are more effective at improving the mental model of users as compared to simply showing random examples. We compare a generative approach and a retrieval-based approach to show counterfactual examples. We use recent advances in generative adversarial networks (GANs) to generate counterfactual images by deleting and inpainting certain regions of interest in the image. We then expose users to changes in the VQA system's answer on those altered images. To select the region of interest for inpainting, we experiment with using both human-annotated attention maps and a fully automatic method that uses the VQA system's attention values. Finally, we test the user's mental model by asking them to predict the model's performance on a test counterfactual image. We note an overall improvement in users' accuracy to predict answer change when shown counterfactual explanations. While realistic retrieved counterfactuals obviously are the most effective at improving the mental model, we show that a generative approach can also be equally effective.
Knowing What VQA Does Not: Pointing to Error-Inducing Regions to Improve Explanation Helpfulness
Mar 31, 2021
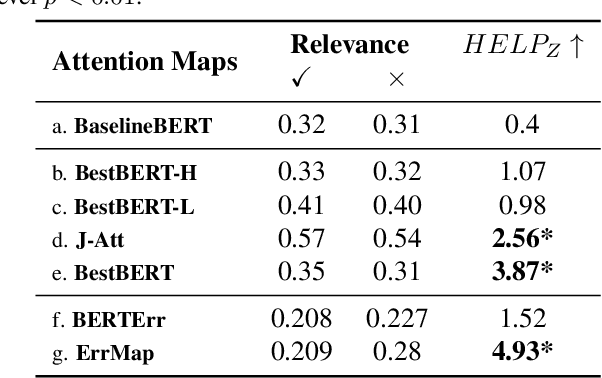

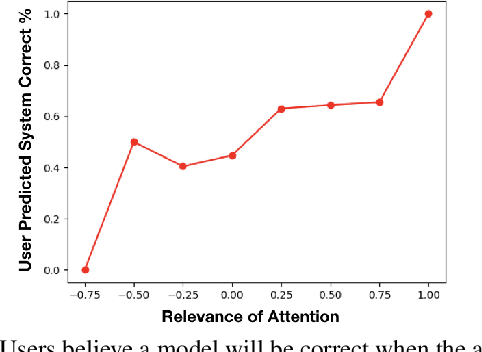
Attention maps, a popular heatmap-based explanation method for Visual Question Answering (VQA), are supposed to help users understand the model by highlighting portions of the image/question used by the model to infer answers. However, we see that users are often misled by current attention map visualizations that point to relevant regions despite the model producing an incorrect answer. Hence, we propose Error Maps that clarify the error by highlighting image regions where the model is prone to err. Error maps can indicate when a correctly attended region may be processed incorrectly leading to an incorrect answer, and hence, improve users' understanding of those cases. To evaluate our new explanations, we further introduce a metric that simulates users' interpretation of explanations to evaluate their potential helpfulness to understand model correctness. We finally conduct user studies to see that our new explanations help users understand model correctness better than baselines by an expected 30% and that our proxy helpfulness metrics correlate strongly ($\rho$>0.97) with how well users can predict model correctness.
The Impact of Explanations on AI Competency Prediction in VQA
Jul 02, 2020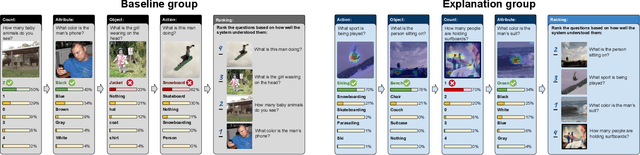
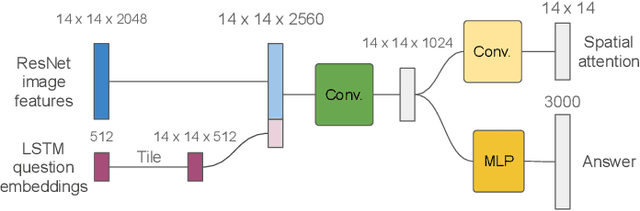
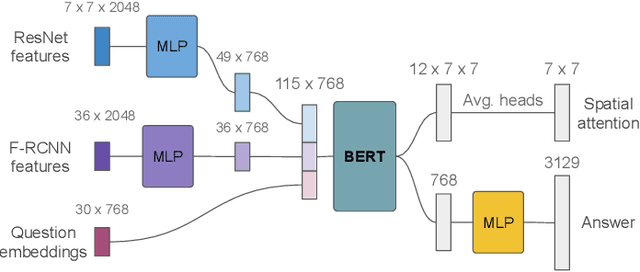

Explainability is one of the key elements for building trust in AI systems. Among numerous attempts to make AI explainable, quantifying the effect of explanations remains a challenge in conducting human-AI collaborative tasks. Aside from the ability to predict the overall behavior of AI, in many applications, users need to understand an AI agent's competency in different aspects of the task domain. In this paper, we evaluate the impact of explanations on the user's mental model of AI agent competency within the task of visual question answering (VQA). We quantify users' understanding of competency, based on the correlation between the actual system performance and user rankings. We introduce an explainable VQA system that uses spatial and object features and is powered by the BERT language model. Each group of users sees only one kind of explanation to rank the competencies of the VQA model. The proposed model is evaluated through between-subject experiments to probe explanations' impact on the user's perception of competency. The comparison between two VQA models shows BERT based explanations and the use of object features improve the user's prediction of the model's competencies.
Deep Learning Improves Contrast in Low-Fluence Photoacoustic Imaging
Apr 19, 2020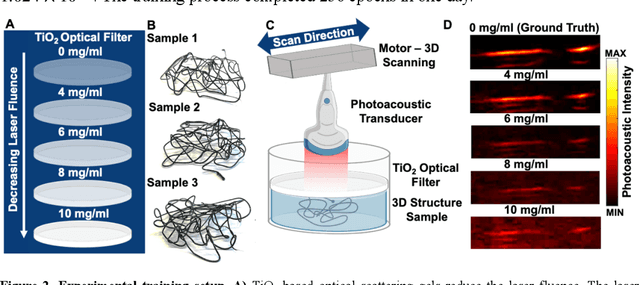
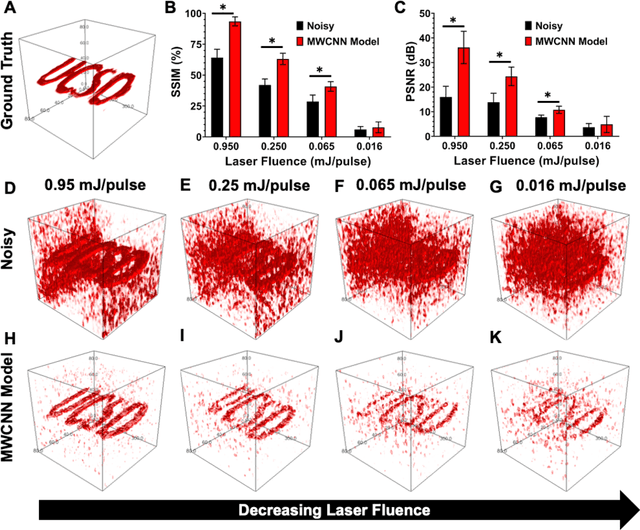
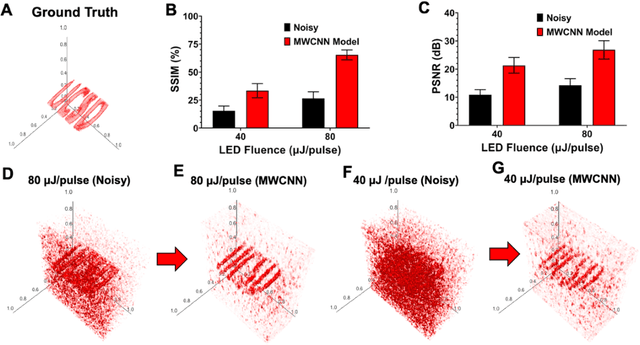
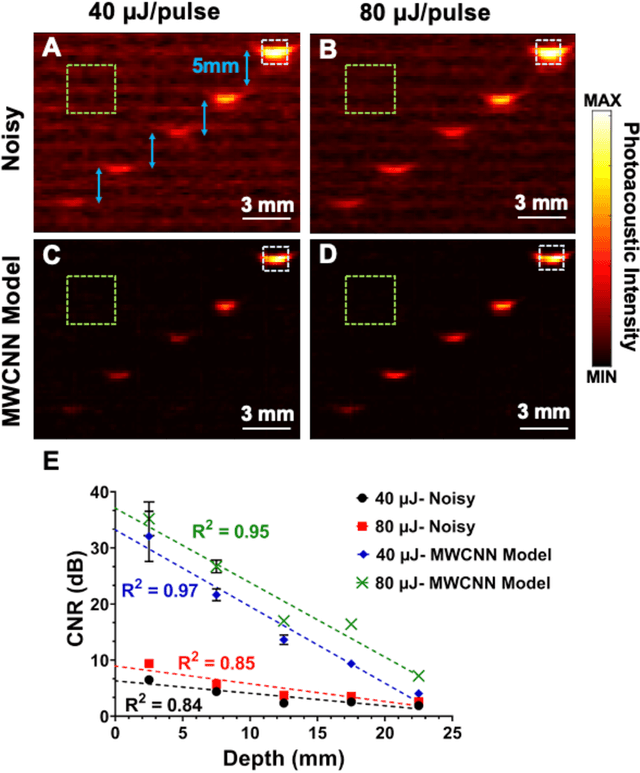
Low fluence illumination sources can facilitate clinical transition of photoacoustic imaging because they are rugged, portable, affordable, and safe. However, these sources also decrease image quality due to their low fluence. Here, we propose a denoising method using a multi-level wavelet-convolutional neural network to map low fluence illumination source images to its corresponding high fluence excitation map. Quantitative and qualitative results show a significant potential to remove the background noise and preserve the structures of target. Substantial improvements up to 2.20, 2.25, and 4.3-fold for PSNR, SSIM, and CNR metrics were observed, respectively. We also observed enhanced contrast (up to 1.76-fold) in an in vivo application using our proposed methods. We suggest that this tool can improve the value of such sources in photoacoustic imaging.
A Study on Multimodal and Interactive Explanations for Visual Question Answering
Mar 01, 2020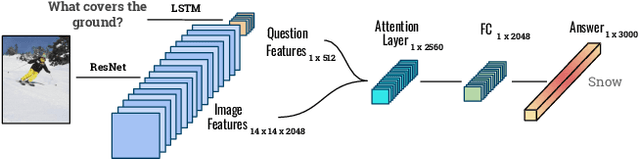
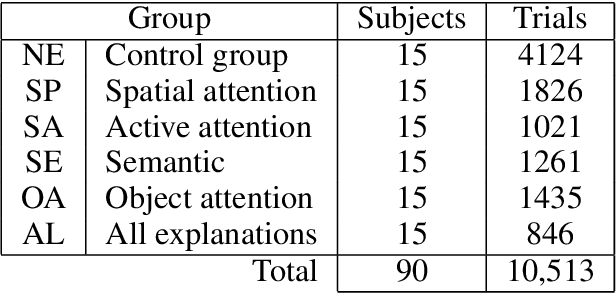
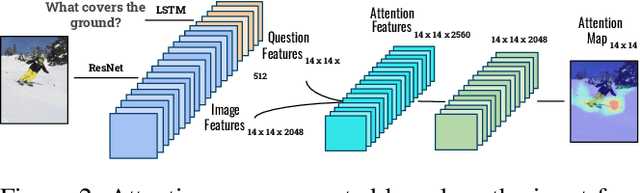

Explainability and interpretability of AI models is an essential factor affecting the safety of AI. While various explainable AI (XAI) approaches aim at mitigating the lack of transparency in deep networks, the evidence of the effectiveness of these approaches in improving usability, trust, and understanding of AI systems are still missing. We evaluate multimodal explanations in the setting of a Visual Question Answering (VQA) task, by asking users to predict the response accuracy of a VQA agent with and without explanations. We use between-subjects and within-subjects experiments to probe explanation effectiveness in terms of improving user prediction accuracy, confidence, and reliance, among other factors. The results indicate that the explanations help improve human prediction accuracy, especially in trials when the VQA system's answer is inaccurate. Furthermore, we introduce active attention, a novel method for evaluating causal attentional effects through intervention by editing attention maps. User explanation ratings are strongly correlated with human prediction accuracy and suggest the efficacy of these explanations in human-machine AI collaboration tasks.
* http://ceur-ws.org/Vol-2560/paper44.pdf