 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePunching Bag vs. Punching Person: Motion Transferability in Videos
Jul 31, 2025Action recognition models demonstrate strong generalization, but can they effectively transfer high-level motion concepts across diverse contexts, even within similar distributions? For example, can a model recognize the broad action "punching" when presented with an unseen variation such as "punching person"? To explore this, we introduce a motion transferability framework with three datasets: (1) Syn-TA, a synthetic dataset with 3D object motions; (2) Kinetics400-TA; and (3) Something-Something-v2-TA, both adapted from natural video datasets. We evaluate 13 state-of-the-art models on these benchmarks and observe a significant drop in performance when recognizing high-level actions in novel contexts. Our analysis reveals: 1) Multimodal models struggle more with fine-grained unknown actions than with coarse ones; 2) The bias-free Syn-TA proves as challenging as real-world datasets, with models showing greater performance drops in controlled settings; 3) Larger models improve transferability when spatial cues dominate but struggle with intensive temporal reasoning, while reliance on object and background cues hinders generalization. We further explore how disentangling coarse and fine motions can improve recognition in temporally challenging datasets. We believe this study establishes a crucial benchmark for assessing motion transferability in action recognition. Datasets and relevant code: https://github.com/raiyaan-abdullah/Motion-Transfer.
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023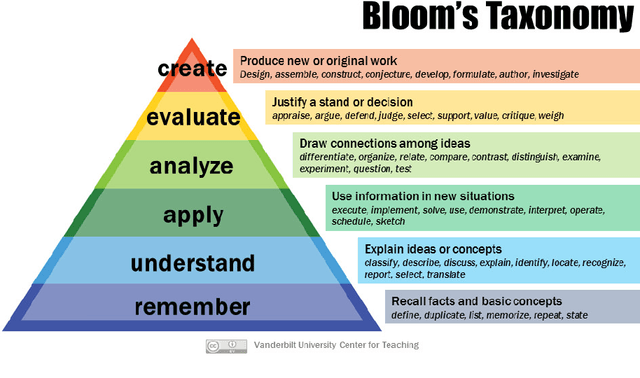
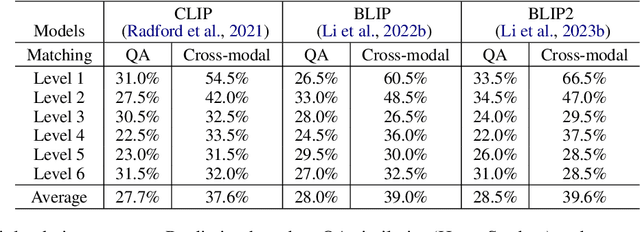

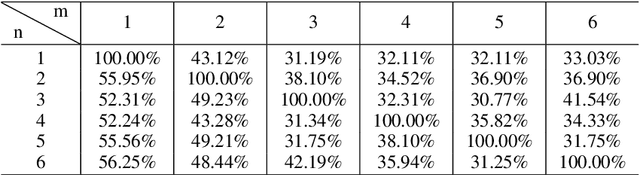
We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.
A Video is Worth 10,000 Words: Training and Benchmarking with Diverse Captions for Better Long Video Retrieval
Nov 30, 2023



Existing long video retrieval systems are trained and tested in the paragraph-to-video retrieval regime, where every long video is described by a single long paragraph. This neglects the richness and variety of possible valid descriptions of a video, which could be described in moment-by-moment detail, or in a single phrase summary, or anything in between. To provide a more thorough evaluation of the capabilities of long video retrieval systems, we propose a pipeline that leverages state-of-the-art large language models to carefully generate a diverse set of synthetic captions for long videos. We validate this pipeline's fidelity via rigorous human inspection. We then benchmark a representative set of video language models on these synthetic captions using a few long video datasets, showing that they struggle with the transformed data, especially the shortest captions. We also propose a lightweight fine-tuning method, where we use a contrastive loss to learn a hierarchical embedding loss based on the differing levels of information among the various captions. Our method improves performance both on the downstream paragraph-to-video retrieval task (+1.1% R@1 on ActivityNet), as well as for the various long video retrieval metrics we compute using our synthetic data (+3.6% R@1 for short descriptions on ActivityNet). For data access and other details, please refer to our project website at https://mgwillia.github.io/10k-words.
DRESS: Instructing Large Vision-Language Models to Align and Interact with Humans via Natural Language Feedback
Nov 16, 2023



We present DRESS, a large vision language model (LVLM) that innovatively exploits Natural Language feedback (NLF) from Large Language Models to enhance its alignment and interactions by addressing two key limitations in the state-of-the-art LVLMs. First, prior LVLMs generally rely only on the instruction finetuning stage to enhance alignment with human preferences. Without incorporating extra feedback, they are still prone to generate unhelpful, hallucinated, or harmful responses. Second, while the visual instruction tuning data is generally structured in a multi-turn dialogue format, the connections and dependencies among consecutive conversational turns are weak. This reduces the capacity for effective multi-turn interactions. To tackle these, we propose a novel categorization of the NLF into two key types: critique and refinement. The critique NLF identifies the strengths and weaknesses of the responses and is used to align the LVLMs with human preferences. The refinement NLF offers concrete suggestions for improvement and is adopted to improve the interaction ability of the LVLMs-- which focuses on LVLMs' ability to refine responses by incorporating feedback in multi-turn interactions. To address the non-differentiable nature of NLF, we generalize conditional reinforcement learning for training. Our experimental results demonstrate that DRESS can generate more helpful (9.76%), honest (11.52%), and harmless (21.03%) responses, and more effectively learn from feedback during multi-turn interactions compared to SOTA LVMLs.
Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
Sep 08, 2023Vision-language models (VLMs) have recently demonstrated strong efficacy as visual assistants that can parse natural queries about the visual content and generate human-like outputs. In this work, we explore the ability of these models to demonstrate human-like reasoning based on the perceived information. To address a crucial concern regarding the extent to which their reasoning capabilities are fully consistent and grounded, we also measure the reasoning consistency of these models. We achieve this by proposing a chain-of-thought (CoT) based consistency measure. However, such an evaluation requires a benchmark that encompasses both high-level inference and detailed reasoning chains, which is costly. We tackle this challenge by proposing a LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously ensuring the generation of a high-quality dataset. Based on this pipeline and the existing coarse-grained annotated dataset, we build the CURE benchmark to measure both the zero-shot reasoning performance and consistency of VLMs. We evaluate existing state-of-the-art VLMs, and find that even the best-performing model is unable to demonstrate strong visual reasoning capabilities and consistency, indicating that substantial efforts are required to enable VLMs to perform visual reasoning as systematically and consistently as humans. As an early step, we propose a two-stage training framework aimed at improving both the reasoning performance and consistency of VLMs. The first stage involves employing supervised fine-tuning of VLMs using step-by-step reasoning samples automatically generated by LLMs. In the second stage, we further augment the training process by incorporating feedback provided by LLMs to produce reasoning chains that are highly consistent and grounded. We empirically highlight the effectiveness of our framework in both reasoning performance and consistency.
Probing Conceptual Understanding of Large Visual-Language Models
Apr 07, 2023



We present a novel framework for probing and improving relational, compositional and contextual understanding of large visual-language models (V+L). While large V+L models have achieved success in various downstream tasks, it is not clear if they have a conceptual grasp of the content. We propose a novel benchmarking dataset for probing three aspects of content understanding. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We have experimented with 5 well known models, such as CLIP and ViLT, and found that they mostly fail to demonstrate a conceptual understanding. That said, we find interesting insights such as cross-attention helps learning conceptual understanding. We use these insights to propose a new finetuning technique that rewards the three conceptual understanding measures we proposed. We hope that the presented benchmarks will help the community assess and improve the conceptual understanding capabilities of large V+L models.
Unpacking Large Language Models with Conceptual Consistency
Sep 29, 2022

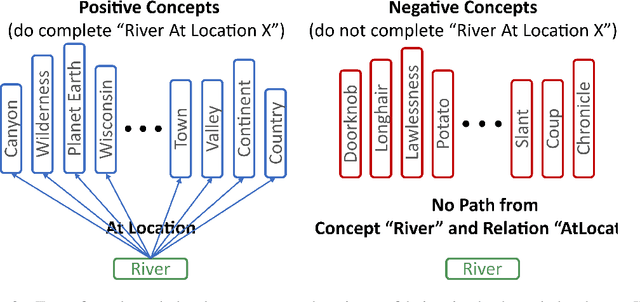

If a Large Language Model (LLM) answers "yes" to the question "Are mountains tall?" then does it know what a mountain is? Can you rely on it responding correctly or incorrectly to other questions about mountains? The success of Large Language Models (LLMs) indicates they are increasingly able to answer queries like these accurately, but that ability does not necessarily imply a general understanding of concepts relevant to the anchor query. We propose conceptual consistency to measure a LLM's understanding of relevant concepts. This novel metric measures how well a model can be characterized by finding out how consistent its responses to queries about conceptually relevant background knowledge are. To compute it we extract background knowledge by traversing paths between concepts in a knowledge base and then try to predict the model's response to the anchor query from the background knowledge. We investigate the performance of current LLMs in a commonsense reasoning setting using the CSQA dataset and the ConceptNet knowledge base. While conceptual consistency, like other metrics, does increase with the scale of the LLM used, we find that popular models do not necessarily have high conceptual consistency. Our analysis also shows significant variation in conceptual consistency across different kinds of relations, concepts, and prompts. This serves as a step toward building models that humans can apply a theory of mind to, and thus interact with intuitively.
Improving Users' Mental Model with Attention-directed Counterfactual Edits
Oct 15, 2021


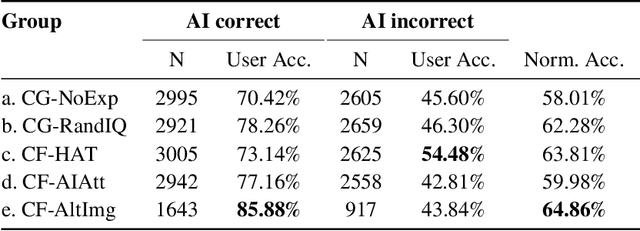
In the domain of Visual Question Answering (VQA), studies have shown improvement in users' mental model of the VQA system when they are exposed to examples of how these systems answer certain Image-Question (IQ) pairs. In this work, we show that showing controlled counterfactual image-question examples are more effective at improving the mental model of users as compared to simply showing random examples. We compare a generative approach and a retrieval-based approach to show counterfactual examples. We use recent advances in generative adversarial networks (GANs) to generate counterfactual images by deleting and inpainting certain regions of interest in the image. We then expose users to changes in the VQA system's answer on those altered images. To select the region of interest for inpainting, we experiment with using both human-annotated attention maps and a fully automatic method that uses the VQA system's attention values. Finally, we test the user's mental model by asking them to predict the model's performance on a test counterfactual image. We note an overall improvement in users' accuracy to predict answer change when shown counterfactual explanations. While realistic retrieved counterfactuals obviously are the most effective at improving the mental model, we show that a generative approach can also be equally effective.
Trigger Hunting with a Topological Prior for Trojan Detection
Oct 15, 2021



Despite their success and popularity, deep neural networks (DNNs) are vulnerable when facing backdoor attacks. This impedes their wider adoption, especially in mission critical applications. This paper tackles the problem of Trojan detection, namely, identifying Trojaned models -- models trained with poisoned data. One popular approach is reverse engineering, i.e., recovering the triggers on a clean image by manipulating the model's prediction. One major challenge of reverse engineering approach is the enormous search space of triggers. To this end, we propose innovative priors such as diversity and topological simplicity to not only increase the chances of finding the appropriate triggers but also improve the quality of the found triggers. Moreover, by encouraging a diverse set of trigger candidates, our method can perform effectively in cases with unknown target labels. We demonstrate that these priors can significantly improve the quality of the recovered triggers, resulting in substantially improved Trojan detection accuracy as validated on both synthetic and publicly available TrojAI benchmarks.
Comprehension Based Question Answering using Bloom's Taxonomy
Jun 08, 2021
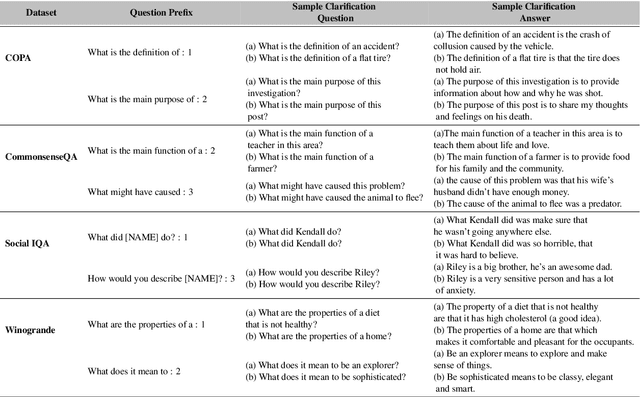


Current pre-trained language models have lots of knowledge, but a more limited ability to use that knowledge. Bloom's Taxonomy helps educators teach children how to use knowledge by categorizing comprehension skills, so we use it to analyze and improve the comprehension skills of large pre-trained language models. Our experiments focus on zero-shot question answering, using the taxonomy to provide proximal context that helps the model answer questions by being relevant to those questions. We show targeting context in this manner improves performance across 4 popular common sense question answer datasets.