 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Understanding, Measurement, and Manipulation Using Category Theory
Oct 24, 2025We apply category theory to extract multimodal document structure which leads us to develop information theoretic measures, content summarization and extension, and self-supervised improvement of large pretrained models. We first develop a mathematical representation of a document as a category of question-answer pairs. Second, we develop an orthogonalization procedure to divide the information contained in one or more documents into non-overlapping pieces. The structures extracted in the first and second steps lead us to develop methods to measure and enumerate the information contained in a document. We also build on those steps to develop new summarization techniques, as well as to develop a solution to a new problem viz. exegesis resulting in an extension of the original document. Our question-answer pair methodology enables a novel rate distortion analysis of summarization techniques. We implement our techniques using large pretrained models, and we propose a multimodal extension of our overall mathematical framework. Finally, we develop a novel self-supervised method using RLVR to improve large pretrained models using consistency constraints such as composability and closure under certain operations that stem naturally from our category theoretic framework.
Punching Bag vs. Punching Person: Motion Transferability in Videos
Jul 31, 2025Action recognition models demonstrate strong generalization, but can they effectively transfer high-level motion concepts across diverse contexts, even within similar distributions? For example, can a model recognize the broad action "punching" when presented with an unseen variation such as "punching person"? To explore this, we introduce a motion transferability framework with three datasets: (1) Syn-TA, a synthetic dataset with 3D object motions; (2) Kinetics400-TA; and (3) Something-Something-v2-TA, both adapted from natural video datasets. We evaluate 13 state-of-the-art models on these benchmarks and observe a significant drop in performance when recognizing high-level actions in novel contexts. Our analysis reveals: 1) Multimodal models struggle more with fine-grained unknown actions than with coarse ones; 2) The bias-free Syn-TA proves as challenging as real-world datasets, with models showing greater performance drops in controlled settings; 3) Larger models improve transferability when spatial cues dominate but struggle with intensive temporal reasoning, while reliance on object and background cues hinders generalization. We further explore how disentangling coarse and fine motions can improve recognition in temporally challenging datasets. We believe this study establishes a crucial benchmark for assessing motion transferability in action recognition. Datasets and relevant code: https://github.com/raiyaan-abdullah/Motion-Transfer.
Interpreting Agent Behaviors in Reinforcement-Learning-Based Cyber-Battle Simulation Platforms
Jun 09, 2025We analyze two open source deep reinforcement learning agents submitted to the CAGE Challenge 2 cyber defense challenge, where each competitor submitted an agent to defend a simulated network against each of several provided rules-based attack agents. We demonstrate that one can gain interpretability of agent successes and failures by simplifying the complex state and action spaces and by tracking important events, shedding light on the fine-grained behavior of both the defense and attack agents in each experimental scenario. By analyzing important events within an evaluation episode, we identify patterns in infiltration and clearing events that tell us how well the attacker and defender played their respective roles; for example, defenders were generally able to clear infiltrations within one or two timesteps of a host being exploited. By examining transitions in the environment's state caused by the various possible actions, we determine which actions tended to be effective and which did not, showing that certain important actions are between 40% and 99% ineffective. We examine how decoy services affect exploit success, concluding for instance that decoys block up to 94% of exploits that would directly grant privileged access to a host. Finally, we discuss the realism of the challenge and ways that the CAGE Challenge 4 has addressed some of our concerns.
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023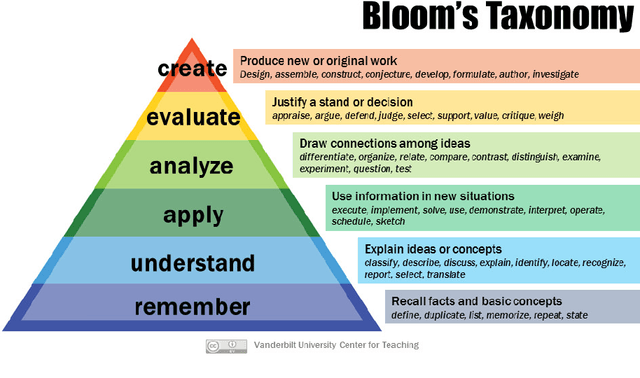
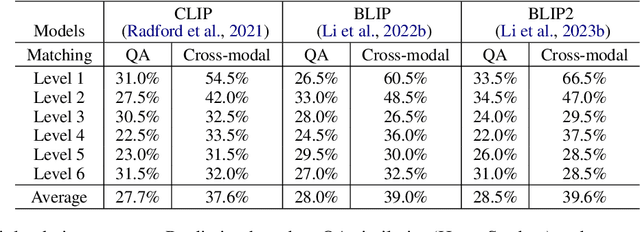

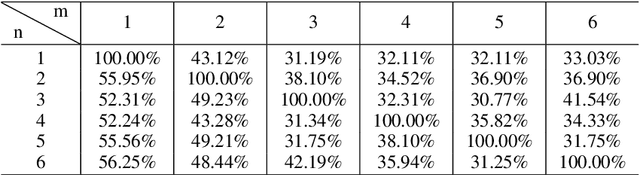
We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.