 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDS: A Cross-cultural Dialogue Corpus for Social Norm Classification and Adherence Detection
Nov 13, 2025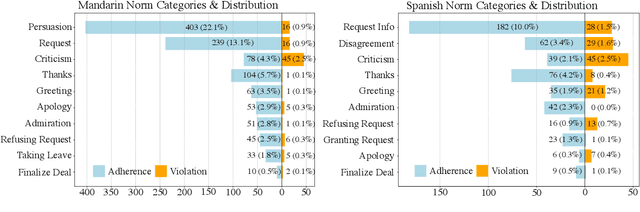
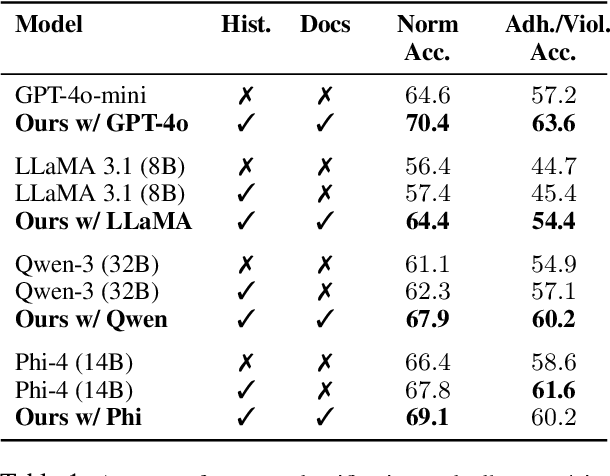
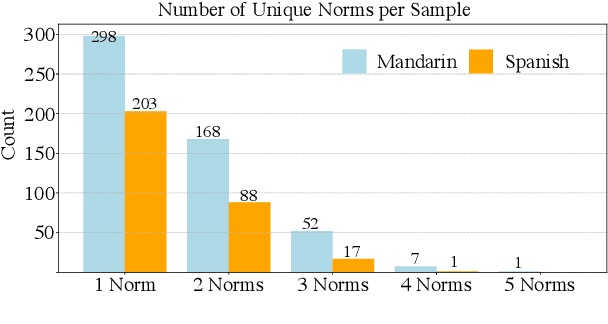
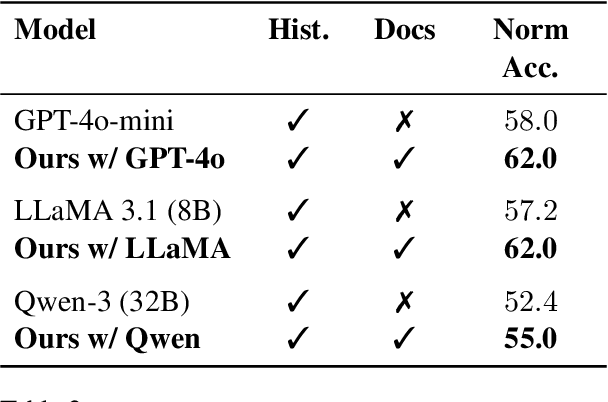
Social norms are implicit, culturally grounded expectations that guide interpersonal communication. Unlike factual commonsense, norm reasoning is subjective, context-dependent, and varies across cultures, posing challenges for computational models. Prior works provide valuable normative annotations but mostly target isolated utterances or synthetic dialogues, limiting their ability to capture the fluid, multi-turn nature of real-world conversations. In this work, we present Norm-RAG, a retrieval-augmented, agentic framework for nuanced social norm inference in multi-turn dialogues. Norm-RAG models utterance-level attributes including communicative intent, speaker roles, interpersonal framing, and linguistic cues and grounds them in structured normative documentation retrieved via a novel Semantic Chunking approach. This enables interpretable and context-aware reasoning about norm adherence and violation across multilingual dialogues. We further introduce MINDS (Multilingual Interactions with Norm-Driven Speech), a bilingual dataset comprising 31 multi-turn Mandarin-English and Spanish-English conversations. Each turn is annotated for norm category and adherence status using multi-annotator consensus, reflecting cross-cultural and realistic norm expression. Our experiments show that Norm-RAG improves norm detection and generalization, demonstrates improved performance for culturally adaptive and socially intelligent dialogue systems.
SayCoNav: Utilizing Large Language Models for Adaptive Collaboration in Decentralized Multi-Robot Navigation
May 19, 2025Adaptive collaboration is critical to a team of autonomous robots to perform complicated navigation tasks in large-scale unknown environments. An effective collaboration strategy should be determined and adapted according to each robot's skills and current status to successfully achieve the shared goal. We present SayCoNav, a new approach that leverages large language models (LLMs) for automatically generating this collaboration strategy among a team of robots. Building on the collaboration strategy, each robot uses the LLM to generate its plans and actions in a decentralized way. By sharing information to each other during navigation, each robot also continuously updates its step-by-step plans accordingly. We evaluate SayCoNav on Multi-Object Navigation (MultiON) tasks, that require the team of the robots to utilize their complementary strengths to efficiently search multiple different objects in unknown environments. By validating SayCoNav with varied team compositions and conditions against baseline methods, our experimental results show that SayCoNav can improve search efficiency by at most 44.28% through effective collaboration among heterogeneous robots. It can also dynamically adapt to the changing conditions during task execution.
GenVP: Generating Visual Puzzles with Contrastive Hierarchical VAEs
Mar 30, 2025Raven's Progressive Matrices (RPMs) is an established benchmark to examine the ability to perform high-level abstract visual reasoning (AVR). Despite the current success of algorithms that solve this task, humans can generalize beyond a given puzzle and create new puzzles given a set of rules, whereas machines remain locked in solving a fixed puzzle from a curated choice list. We propose Generative Visual Puzzles (GenVP), a framework to model the entire RPM generation process, a substantially more challenging task. Our model's capability spans from generating multiple solutions for one specific problem prompt to creating complete new puzzles out of the desired set of rules. Experiments on five different datasets indicate that GenVP achieves state-of-the-art (SOTA) performance both in puzzle-solving accuracy and out-of-distribution (OOD) generalization in 22 OOD scenarios. Compared to SOTA generative approaches, which struggle to solve RPMs when the feasible solution space increases, GenVP efficiently generalizes to these challenging setups. Moreover, our model demonstrates the ability to produce a wide range of complete RPMs given a set of abstract rules by effectively capturing the relationships between abstract rules and visual object properties.
Pelican: Correcting Hallucination in Vision-LLMs via Claim Decomposition and Program of Thought Verification
Jul 02, 2024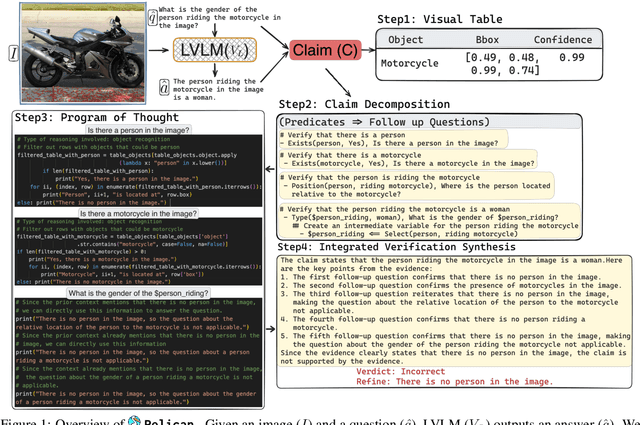
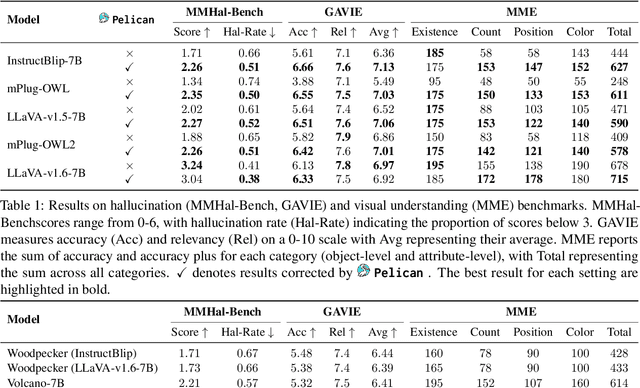
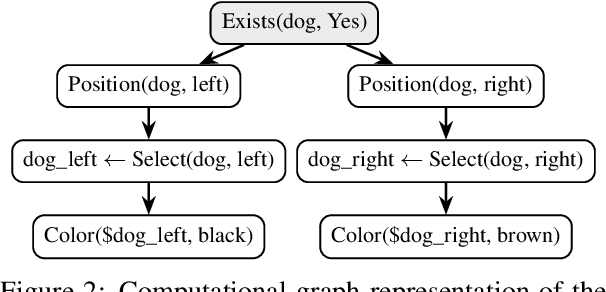

Large Visual Language Models (LVLMs) struggle with hallucinations in visual instruction following task(s), limiting their trustworthiness and real-world applicability. We propose Pelican -- a novel framework designed to detect and mitigate hallucinations through claim verification. Pelican first decomposes the visual claim into a chain of sub-claims based on first-order predicates. These sub-claims consist of (predicate, question) pairs and can be conceptualized as nodes of a computational graph. We then use Program-of-Thought prompting to generate Python code for answering these questions through flexible composition of external tools. Pelican improves over prior work by introducing (1) intermediate variables for precise grounding of object instances, and (2) shared computation for answering the sub-question to enable adaptive corrections and inconsistency identification. We finally use reasoning abilities of LLM to verify the correctness of the the claim by considering the consistency and confidence of the (question, answer) pairs from each sub-claim. Our experiments reveal a drop in hallucination rate by $\sim$8%-32% across various baseline LVLMs and a 27% drop compared to approaches proposed for hallucination mitigation on MMHal-Bench. Results on two other benchmarks further corroborate our results.
Unpacking Large Language Models with Conceptual Consistency
Sep 29, 2022

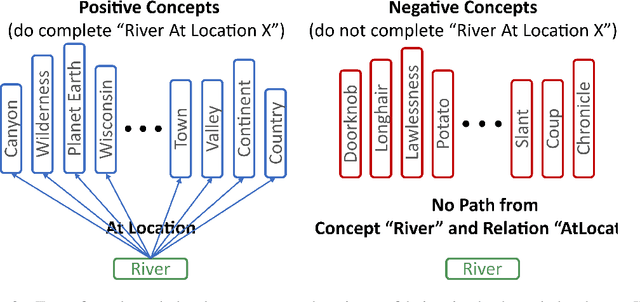

If a Large Language Model (LLM) answers "yes" to the question "Are mountains tall?" then does it know what a mountain is? Can you rely on it responding correctly or incorrectly to other questions about mountains? The success of Large Language Models (LLMs) indicates they are increasingly able to answer queries like these accurately, but that ability does not necessarily imply a general understanding of concepts relevant to the anchor query. We propose conceptual consistency to measure a LLM's understanding of relevant concepts. This novel metric measures how well a model can be characterized by finding out how consistent its responses to queries about conceptually relevant background knowledge are. To compute it we extract background knowledge by traversing paths between concepts in a knowledge base and then try to predict the model's response to the anchor query from the background knowledge. We investigate the performance of current LLMs in a commonsense reasoning setting using the CSQA dataset and the ConceptNet knowledge base. While conceptual consistency, like other metrics, does increase with the scale of the LLM used, we find that popular models do not necessarily have high conceptual consistency. Our analysis also shows significant variation in conceptual consistency across different kinds of relations, concepts, and prompts. This serves as a step toward building models that humans can apply a theory of mind to, and thus interact with intuitively.
SAViR-T: Spatially Attentive Visual Reasoning with Transformers
Jun 22, 2022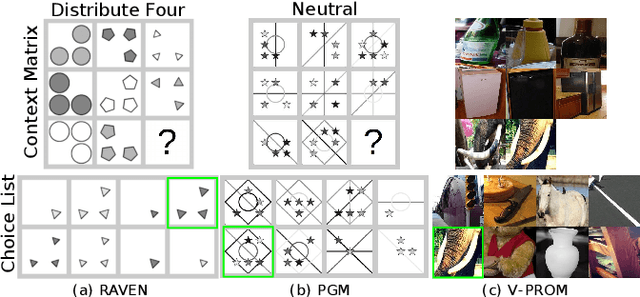
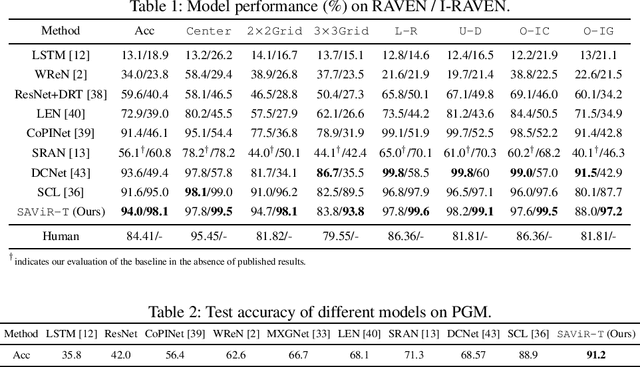
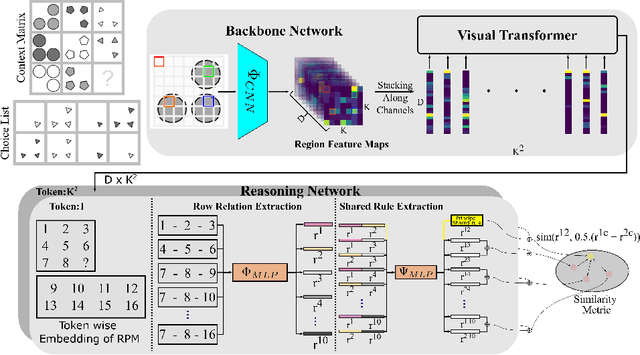
We present a novel computational model, "SAViR-T", for the family of visual reasoning problems embodied in the Raven's Progressive Matrices (RPM). Our model considers explicit spatial semantics of visual elements within each image in the puzzle, encoded as spatio-visual tokens, and learns the intra-image as well as the inter-image token dependencies, highly relevant for the visual reasoning task. Token-wise relationship, modeled through a transformer-based SAViR-T architecture, extract group (row or column) driven representations by leveraging the group-rule coherence and use this as the inductive bias to extract the underlying rule representations in the top two row (or column) per token in the RPM. We use this relation representations to locate the correct choice image that completes the last row or column for the RPM. Extensive experiments across both synthetic RPM benchmarks, including RAVEN, I-RAVEN, RAVEN-FAIR, and PGM, and the natural image-based "V-PROM" demonstrate that SAViR-T sets a new state-of-the-art for visual reasoning, exceeding prior models' performance by a considerable margin.
Challenges in Procedural Multimodal Machine Comprehension:A Novel Way To Benchmark
Oct 22, 2021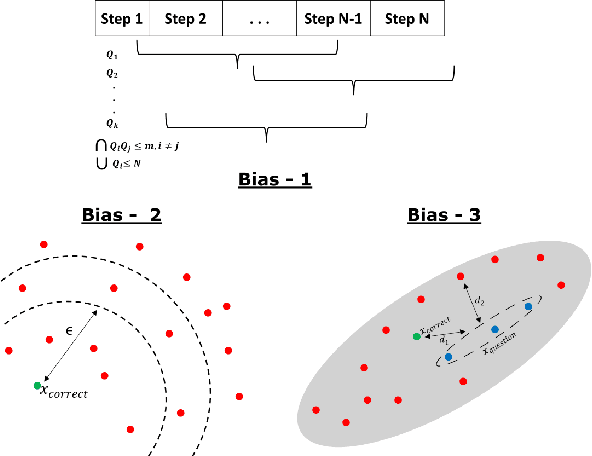

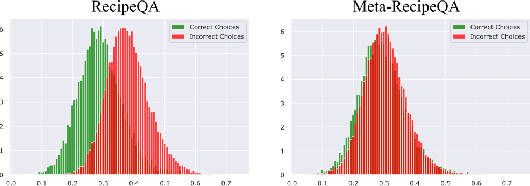

We focus on Multimodal Machine Reading Comprehension (M3C) where a model is expected to answer questions based on given passage (or context), and the context and the questions can be in different modalities. Previous works such as RecipeQA have proposed datasets and cloze-style tasks for evaluation. However, we identify three critical biases stemming from the question-answer generation process and memorization capabilities of large deep models. These biases makes it easier for a model to overfit by relying on spurious correlations or naive data patterns. We propose a systematic framework to address these biases through three Control-Knobs that enable us to generate a test bed of datasets of progressive difficulty levels. We believe that our benchmark (referred to as Meta-RecipeQA) will provide, for the first time, a fine grained estimate of a model's generalization capabilities. We also propose a general M3C model that is used to realize several prior SOTA models and motivate a novel hierarchical transformer based reasoning network (HTRN). We perform a detailed evaluation of these models with different language and visual features on our benchmark. We observe a consistent improvement with HTRN over SOTA (~18% in Visual Cloze task and ~13% in average over all the tasks). We also observe a drop in performance across all the models when testing on RecipeQA and proposed Meta-RecipeQA (e.g. 83.6% versus 67.1% for HTRN), which shows that the proposed dataset is relatively less biased. We conclude by highlighting the impact of the control knobs with some quantitative results.
DAReN: A Collaborative Approach Towards Reasoning And Disentangling
Sep 27, 2021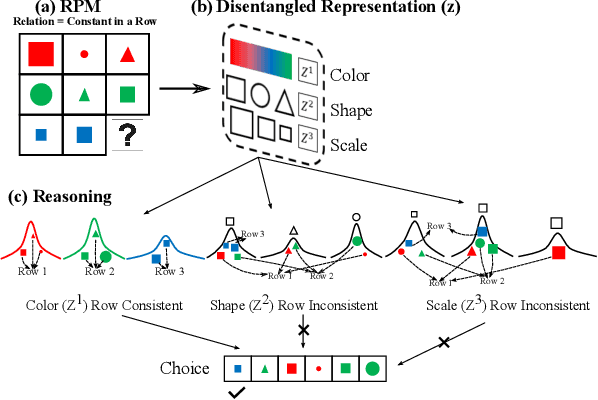

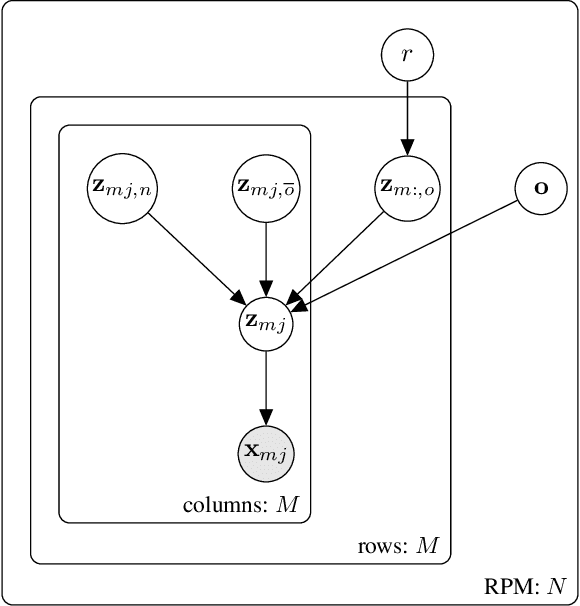
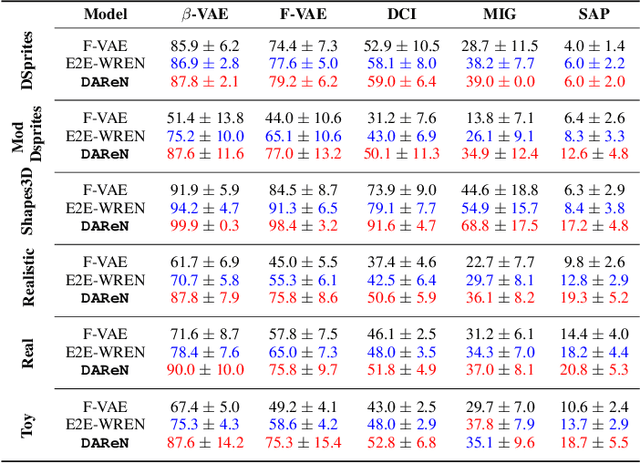
Computational learning approaches to solving visual reasoning tests, such as Raven's Progressive Matrices (RPM),critically depend on the ability of the computational approach to identify the visual concepts used in the test (i.e., the representation) as well as the latent rules based on those concepts (i.e., the reasoning). However, learning of representation and reasoning is a challenging and ill-posed task,often approached in a stage-wise manner (first representation, then reasoning). In this work, we propose an end-to-end joint representation-reasoning learning framework, which leverages a weak form of inductive bias to improve both tasks together. Specifically, we propose a general generative graphical model for RPMs, GM-RPM, and apply it to solve the reasoning test. We accomplish this using a novel learning framework Disentangling based Abstract Reasoning Network (DAReN) based on the principles of GM-RPM. We perform an empirical evaluation of DAReN over several benchmark datasets. DAReN shows consistent improvement over state-of-the-art (SOTA) models on both the reasoning and the disentanglement tasks. This demonstrates the strong correlation between disentangled latent representation and the ability to solve abstract visual reasoning tasks.
Comprehension Based Question Answering using Bloom's Taxonomy
Jun 08, 2021
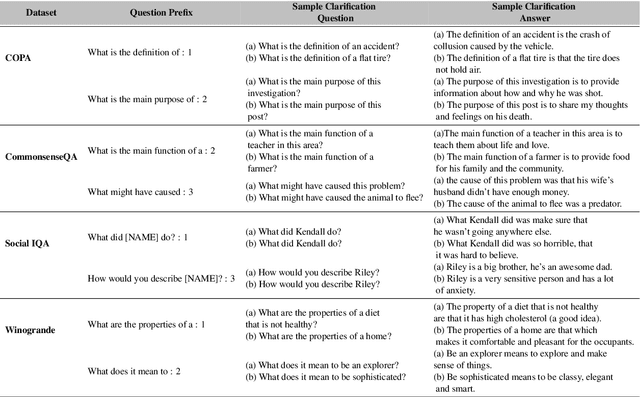


Current pre-trained language models have lots of knowledge, but a more limited ability to use that knowledge. Bloom's Taxonomy helps educators teach children how to use knowledge by categorizing comprehension skills, so we use it to analyze and improve the comprehension skills of large pre-trained language models. Our experiments focus on zero-shot question answering, using the taxonomy to provide proximal context that helps the model answer questions by being relevant to those questions. We show targeting context in this manner improves performance across 4 popular common sense question answer datasets.
Towards Solving Multimodal Comprehension
Apr 20, 2021
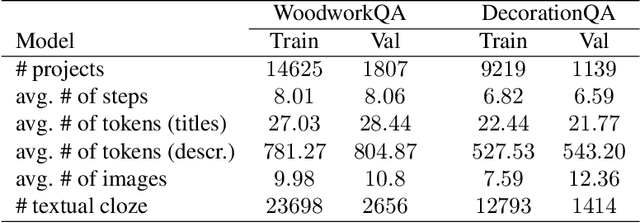


This paper targets the problem of procedural multimodal machine comprehension (M3C). This task requires an AI to comprehend given steps of multimodal instructions and then answer questions. Compared to vanilla machine comprehension tasks where an AI is required only to understand a textual input, procedural M3C is more challenging as the AI needs to comprehend both the temporal and causal factors along with multimodal inputs. Recently Yagcioglu et al. [35] introduced RecipeQA dataset to evaluate M3C. Our first contribution is the introduction of two new M3C datasets- WoodworkQA and DecorationQA with 16K and 10K instructional procedures, respectively. We then evaluate M3C using a textual cloze style question-answering task and highlight an inherent bias in the question answer generation method from [35] that enables a naive baseline to cheat by learning from only answer choices. This naive baseline performs similar to a popular method used in question answering- Impatient Reader [6] that uses attention over both the context and the query. We hypothesized that this naturally occurring bias present in the dataset affects even the best performing model. We verify our proposed hypothesis and propose an algorithm capable of modifying the given dataset to remove the bias elements. Finally, we report our performance on the debiased dataset with several strong baselines. We observe that the performance of all methods falls by a margin of 8% - 16% after correcting for the bias. We hope these datasets and the analysis will provide valuable benchmarks and encourage further research in this area.