 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSayCoNav: Utilizing Large Language Models for Adaptive Collaboration in Decentralized Multi-Robot Navigation
May 19, 2025Adaptive collaboration is critical to a team of autonomous robots to perform complicated navigation tasks in large-scale unknown environments. An effective collaboration strategy should be determined and adapted according to each robot's skills and current status to successfully achieve the shared goal. We present SayCoNav, a new approach that leverages large language models (LLMs) for automatically generating this collaboration strategy among a team of robots. Building on the collaboration strategy, each robot uses the LLM to generate its plans and actions in a decentralized way. By sharing information to each other during navigation, each robot also continuously updates its step-by-step plans accordingly. We evaluate SayCoNav on Multi-Object Navigation (MultiON) tasks, that require the team of the robots to utilize their complementary strengths to efficiently search multiple different objects in unknown environments. By validating SayCoNav with varied team compositions and conditions against baseline methods, our experimental results show that SayCoNav can improve search efficiency by at most 44.28% through effective collaboration among heterogeneous robots. It can also dynamically adapt to the changing conditions during task execution.
Graph2Nav: 3D Object-Relation Graph Generation to Robot Navigation
Apr 23, 2025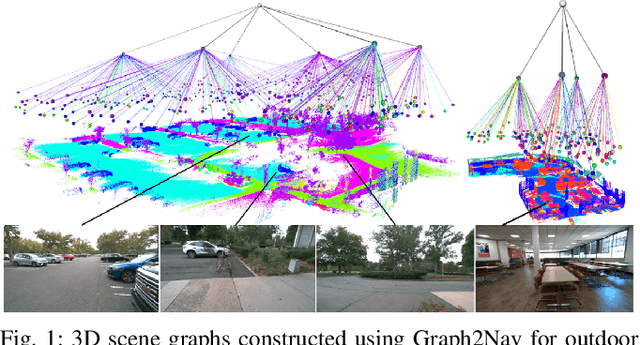
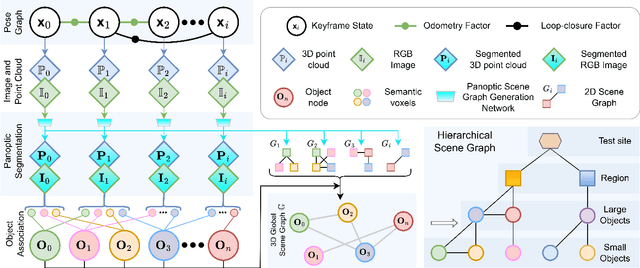
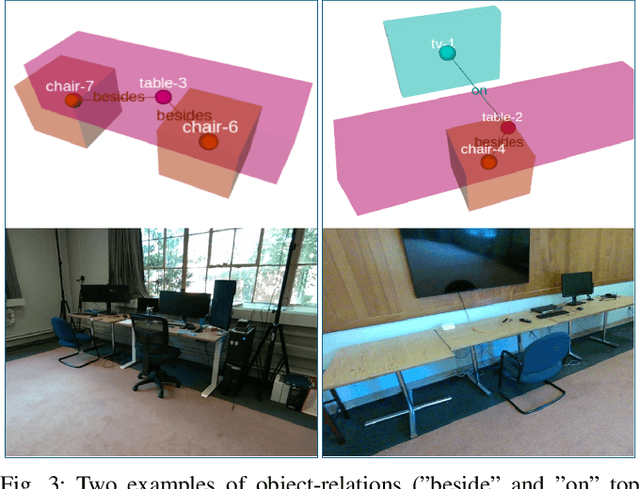

We propose Graph2Nav, a real-time 3D object-relation graph generation framework, for autonomous navigation in the real world. Our framework fully generates and exploits both 3D objects and a rich set of semantic relationships among objects in a 3D layered scene graph, which is applicable to both indoor and outdoor scenes. It learns to generate 3D semantic relations among objects, by leveraging and advancing state-of-the-art 2D panoptic scene graph works into the 3D world via 3D semantic mapping techniques. This approach avoids previous training data constraints in learning 3D scene graphs directly from 3D data. We conduct experiments to validate the accuracy in locating 3D objects and labeling object-relations in our 3D scene graphs. We also evaluate the impact of Graph2Nav via integration with SayNav, a state-of-the-art planner based on large language models, on an unmanned ground robot to object search tasks in real environments. Our results demonstrate that modeling object relations in our scene graphs improves search efficiency in these navigation tasks.
DUDA: Distilled Unsupervised Domain Adaptation for Lightweight Semantic Segmentation
Apr 14, 2025Unsupervised Domain Adaptation (UDA) is essential for enabling semantic segmentation in new domains without requiring costly pixel-wise annotations. State-of-the-art (SOTA) UDA methods primarily use self-training with architecturally identical teacher and student networks, relying on Exponential Moving Average (EMA) updates. However, these approaches face substantial performance degradation with lightweight models due to inherent architectural inflexibility leading to low-quality pseudo-labels. To address this, we propose Distilled Unsupervised Domain Adaptation (DUDA), a novel framework that combines EMA-based self-training with knowledge distillation (KD). Our method employs an auxiliary student network to bridge the architectural gap between heavyweight and lightweight models for EMA-based updates, resulting in improved pseudo-label quality. DUDA employs a strategic fusion of UDA and KD, incorporating innovative elements such as gradual distillation from large to small networks, inconsistency loss prioritizing poorly adapted classes, and learning with multiple teachers. Extensive experiments across four UDA benchmarks demonstrate DUDA's superiority in achieving SOTA performance with lightweight models, often surpassing the performance of heavyweight models from other approaches.
Uncertainty Propagation through Trained Deep Neural Networks Using Factor Graphs
Dec 10, 2023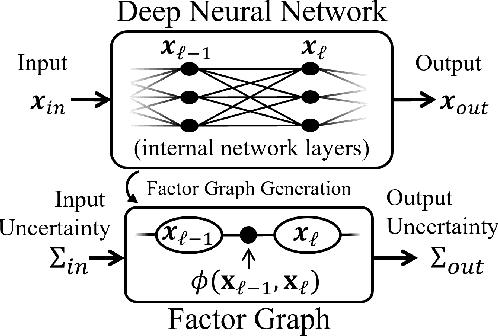
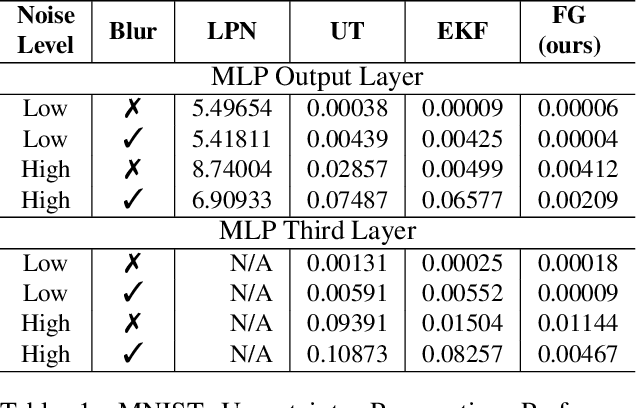
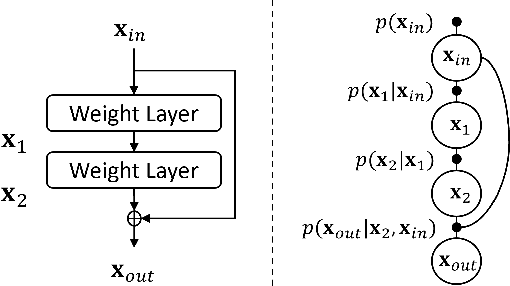
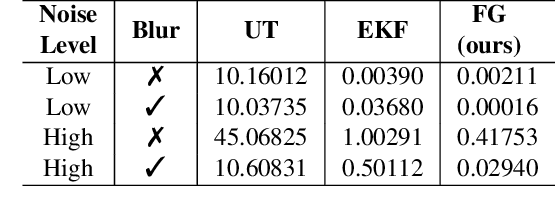
Predictive uncertainty estimation remains a challenging problem precluding the use of deep neural networks as subsystems within safety-critical applications. Aleatoric uncertainty is a component of predictive uncertainty that cannot be reduced through model improvements. Uncertainty propagation seeks to estimate aleatoric uncertainty by propagating input uncertainties to network predictions. Existing uncertainty propagation techniques use one-way information flows, propagating uncertainties layer-by-layer or across the entire neural network while relying either on sampling or analytical techniques for propagation. Motivated by the complex information flows within deep neural networks (e.g. skip connections), we developed and evaluated a novel approach by posing uncertainty propagation as a non-linear optimization problem using factor graphs. We observed statistically significant improvements in performance over prior work when using factor graphs across most of our experiments that included three datasets and two neural network architectures. Our implementation balances the benefits of sampling and analytical propagation techniques, which we believe, is a key factor in achieving performance improvements.
Unsupervised Domain Adaptation for Semantic Segmentation with Pseudo Label Self-Refinement
Oct 25, 2023



Deep learning-based solutions for semantic segmentation suffer from significant performance degradation when tested on data with different characteristics than what was used during the training. Adapting the models using annotated data from the new domain is not always practical. Unsupervised Domain Adaptation (UDA) approaches are crucial in deploying these models in the actual operating conditions. Recent state-of-the-art (SOTA) UDA methods employ a teacher-student self-training approach, where a teacher model is used to generate pseudo-labels for the new data which in turn guide the training process of the student model. Though this approach has seen a lot of success, it suffers from the issue of noisy pseudo-labels being propagated in the training process. To address this issue, we propose an auxiliary pseudo-label refinement network (PRN) for online refining of the pseudo labels and also localizing the pixels whose predicted labels are likely to be noisy. Being able to improve the quality of pseudo labels and select highly reliable ones, PRN helps self-training of segmentation models to be robust against pseudo label noise propagation during different stages of adaptation. We evaluate our approach on benchmark datasets with three different domain shifts, and our approach consistently performs significantly better than the previous state-of-the-art methods.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023



Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation
Mar 30, 2023



Unsupervised domain adaptation (UDA) approaches focus on adapting models trained on a labeled source domain to an unlabeled target domain. UDA methods have a strong assumption that the source data is accessible during adaptation, which may not be feasible in many real-world scenarios due to privacy concerns and resource constraints of devices. In this regard, source-free domain adaptation (SFDA) excels as access to source data is no longer required during adaptation. Recent state-of-the-art (SOTA) methods on SFDA mostly focus on pseudo-label refinement based self-training which generally suffers from two issues: i) inevitable occurrence of noisy pseudo-labels that could lead to early training time memorization, ii) refinement process requires maintaining a memory bank which creates a significant burden in resource constraint scenarios. To address these concerns, we propose C-SFDA, a curriculum learning aided self-training framework for SFDA that adapts efficiently and reliably to changes across domains based on selective pseudo-labeling. Specifically, we employ a curriculum learning scheme to promote learning from a restricted amount of pseudo labels selected based on their reliabilities. This simple yet effective step successfully prevents label noise propagation during different stages of adaptation and eliminates the need for costly memory-bank based label refinement. Our extensive experimental evaluations on both image recognition and semantic segmentation tasks confirm the effectiveness of our method. C-SFDA is readily applicable to online test-time domain adaptation and also outperforms previous SOTA methods in this task.