 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs
Jan 10, 2025



The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.
Unsupervised Domain Adaptation for Semantic Segmentation with Pseudo Label Self-Refinement
Oct 25, 2023



Deep learning-based solutions for semantic segmentation suffer from significant performance degradation when tested on data with different characteristics than what was used during the training. Adapting the models using annotated data from the new domain is not always practical. Unsupervised Domain Adaptation (UDA) approaches are crucial in deploying these models in the actual operating conditions. Recent state-of-the-art (SOTA) UDA methods employ a teacher-student self-training approach, where a teacher model is used to generate pseudo-labels for the new data which in turn guide the training process of the student model. Though this approach has seen a lot of success, it suffers from the issue of noisy pseudo-labels being propagated in the training process. To address this issue, we propose an auxiliary pseudo-label refinement network (PRN) for online refining of the pseudo labels and also localizing the pixels whose predicted labels are likely to be noisy. Being able to improve the quality of pseudo labels and select highly reliable ones, PRN helps self-training of segmentation models to be robust against pseudo label noise propagation during different stages of adaptation. We evaluate our approach on benchmark datasets with three different domain shifts, and our approach consistently performs significantly better than the previous state-of-the-art methods.
A Close Look at Spatial Modeling: From Attention to Convolution
Dec 23, 2022Vision Transformers have shown great promise recently for many vision tasks due to the insightful architecture design and attention mechanism. By revisiting the self-attention responses in Transformers, we empirically observe two interesting issues. First, Vision Transformers present a queryirrelevant behavior at deep layers, where the attention maps exhibit nearly consistent contexts in global scope, regardless of the query patch position (also head-irrelevant). Second, the attention maps are intrinsically sparse, few tokens dominate the attention weights; introducing the knowledge from ConvNets would largely smooth the attention and enhance the performance. Motivated by above observations, we generalize self-attention formulation to abstract a queryirrelevant global context directly and further integrate the global context into convolutions. The resulting model, a Fully Convolutional Vision Transformer (i.e., FCViT), purely consists of convolutional layers and firmly inherits the merits of both attention mechanism and convolutions, including dynamic property, weight sharing, and short- and long-range feature modeling, etc. Experimental results demonstrate the effectiveness of FCViT. With less than 14M parameters, our FCViT-S12 outperforms related work ResT-Lite by 3.7% top1 accuracy on ImageNet-1K. When scaling FCViT to larger models, we still perform better than previous state-of-the-art ConvNeXt with even fewer parameters. FCViT-based models also demonstrate promising transferability to downstream tasks, like object detection, instance segmentation, and semantic segmentation. Codes and models are made available at: https://github.com/ma-xu/FCViT.
Test-time Fourier Style Calibration for Domain Generalization
May 18, 2022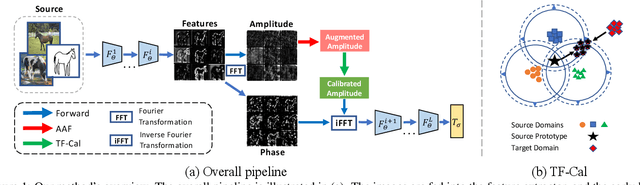
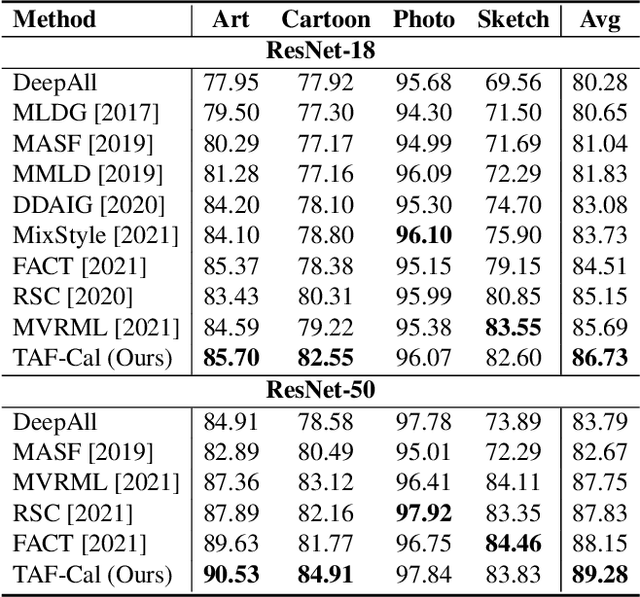
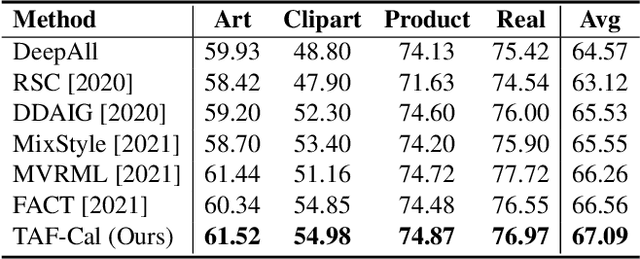
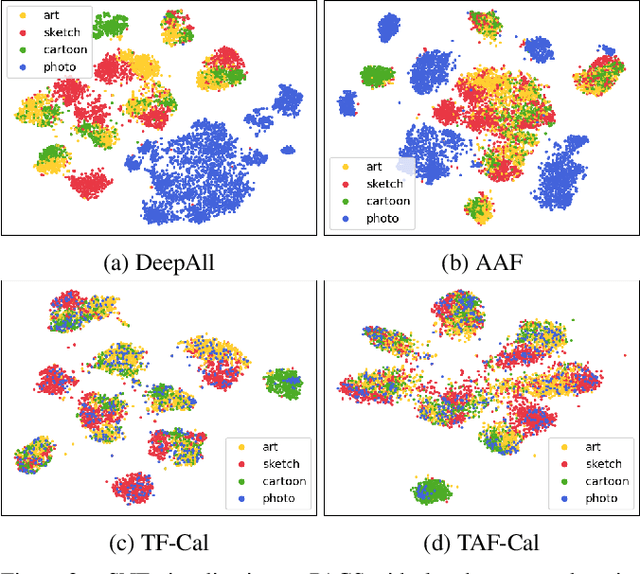
The topic of generalizing machine learning models learned on a collection of source domains to unknown target domains is challenging. While many domain generalization (DG) methods have achieved promising results, they primarily rely on the source domains at train-time without manipulating the target domains at test-time. Thus, it is still possible that those methods can overfit to source domains and perform poorly on target domains. Driven by the observation that domains are strongly related to styles, we argue that reducing the gap between source and target styles can boost models' generalizability. To solve the dilemma of having no access to the target domain during training, we introduce Test-time Fourier Style Calibration (TF-Cal) for calibrating the target domain style on the fly during testing. To access styles, we utilize Fourier transformation to decompose features into amplitude (style) features and phase (semantic) features. Furthermore, we present an effective technique to Augment Amplitude Features (AAF) to complement TF-Cal. Extensive experiments on several popular DG benchmarks and a segmentation dataset for medical images demonstrate that our method outperforms state-of-the-art methods.
Deep-learned speckle pattern and its application to ghost imaging
Dec 28, 2021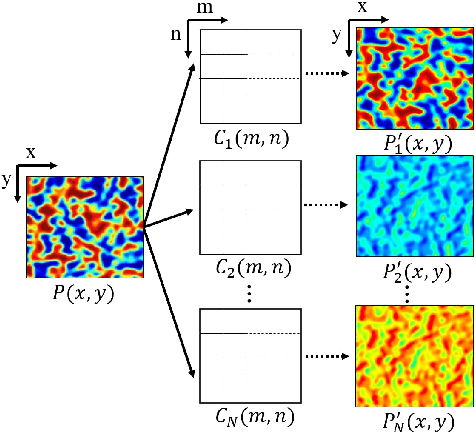
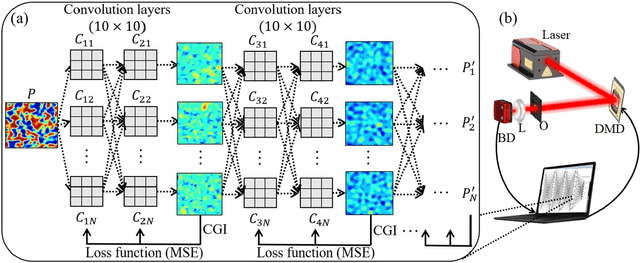

In this paper, we present a method for speckle pattern design using deep learning. The speckle patterns possess unique features after experiencing convolutions in Speckle-Net, our well-designed framework for speckle pattern generation. We then apply our method to the computational ghost imaging system. The standard deep learning-assisted ghost imaging methods use the network to recognize the reconstructed objects or imaging algorithms. In contrast, this innovative application optimizes the illuminating speckle patterns via Speckle-Net with specific sampling ratios. Our method, therefore, outperforms the other techniques for ghost imaging, particularly its ability to retrieve high-quality images with extremely low sampling ratios. It opens a new route towards nontrivial speckle generation by referring to a standard loss function on specified objectives with the modified deep neural network. It also has great potential for applications in the fields of dynamic speckle illumination microscopy, structured illumination microscopy, x-ray imaging, photo-acoustic imaging, and optical lattices.
Imaging through scattering media via spatial-temporal encoded pattern illumination
Dec 26, 2021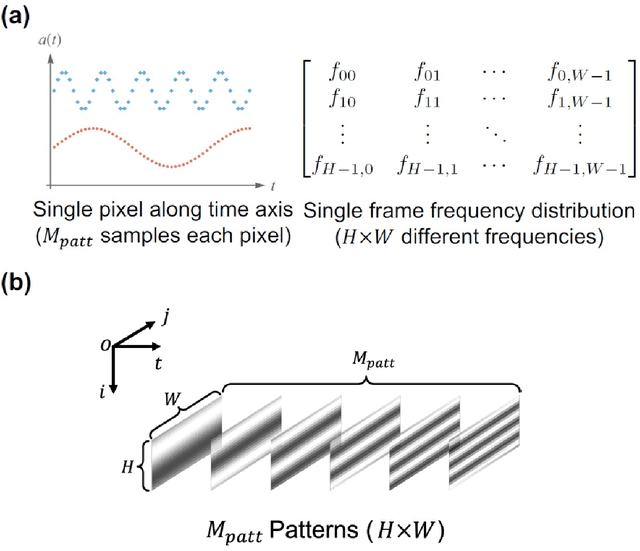
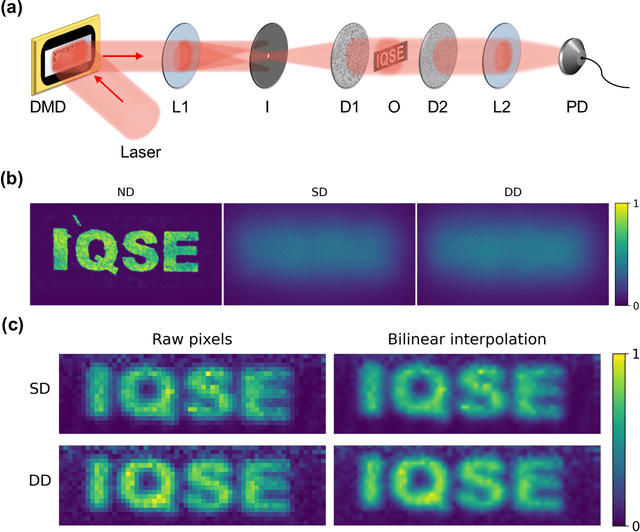
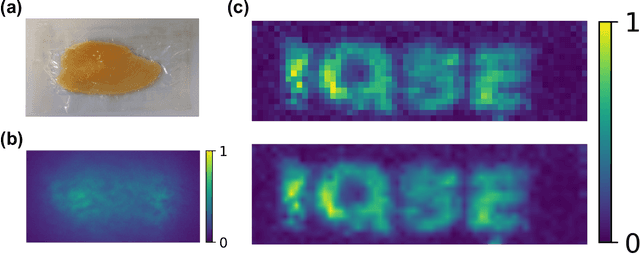
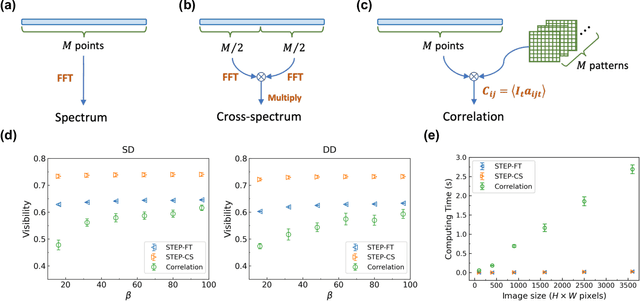
Optical imaging through scattering media is a long-standing challenge. Although many approaches have been developed to focus light or image objects through scattering media, they are either invasive, restricted to stationary or slowly-moving media, or require high-resolution cameras and complex algorithms to retrieve the images. Here we introduce a computational imaging technique that can overcome these restrictions by exploiting spatial-temporal encoded patterns (STEP). We present non-invasive imaging through scattering media with a single-pixel photodetector. We show that the method is insensitive to the motions of media. We further demonstrate that our image reconstruction algorithm is much more efficient than correlation-based algorithms for single-pixel imaging, which may allow fast imaging in currently unreachable scenarios.
0.8% Nyquist computational ghost imaging via non-experimental deep learning
Aug 17, 2021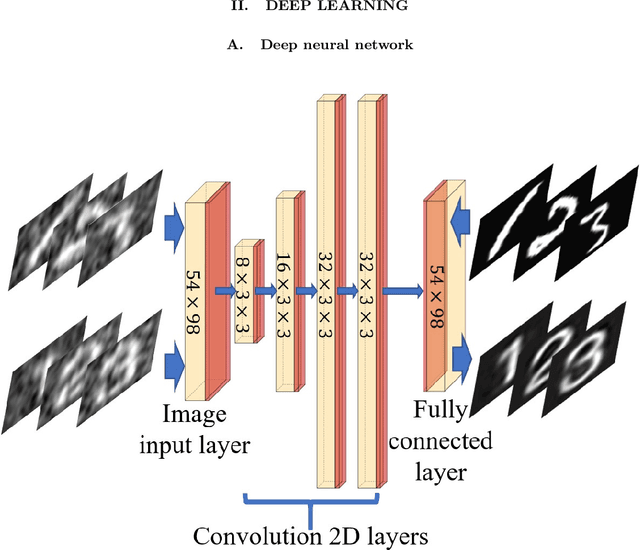
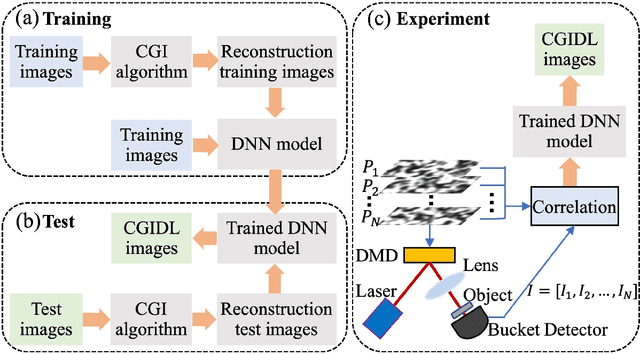

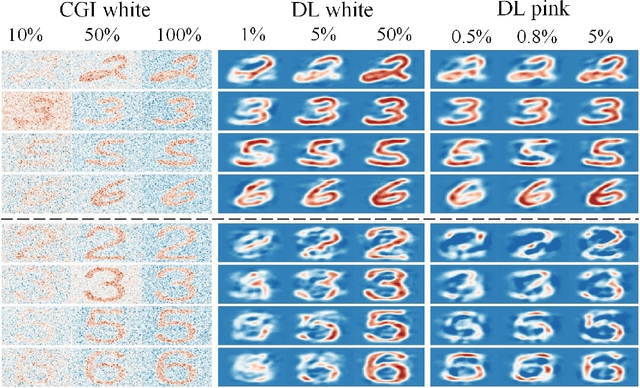
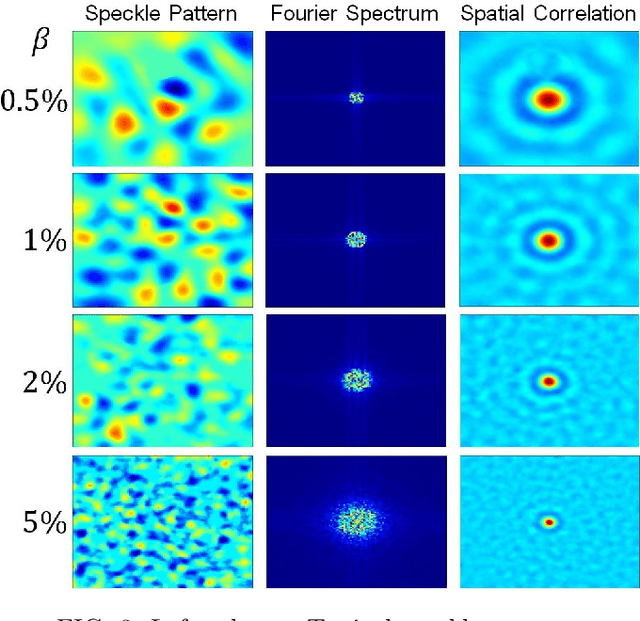
We present a framework for computational ghost imaging based on deep learning and customized pink noise speckle patterns. The deep neural network in this work, which can learn the sensing model and enhance image reconstruction quality, is trained merely by simulation. To demonstrate the sub-Nyquist level in our work, the conventional computational ghost imaging results, reconstructed imaging results using white noise and pink noise via deep learning are compared under multiple sampling rates at different noise conditions. We show that the proposed scheme can provide high-quality images with a sampling rate of 0.8% even when the object is outside the training dataset, and it is robust to noisy environments. This method is excellent for various applications, particularly those that require a low sampling rate, fast reconstruction efficiency, or experience strong noise interference.
PAC Bayesian Performance Guarantees for Deep (Stochastic) Networks in Medical Imaging
Apr 12, 2021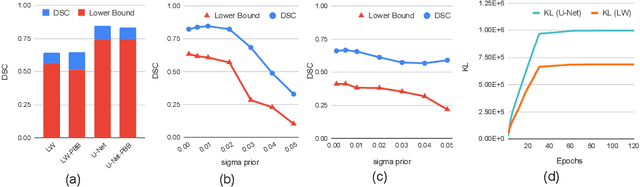
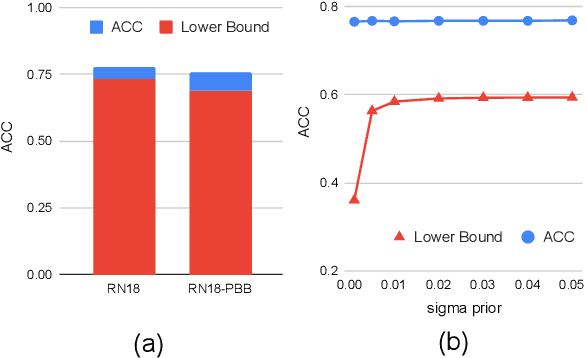
Application of deep neural networks to medical imaging tasks has in some sense become commonplace. Still, a "thorn in the side" of the deep learning movement is the argument that deep networks are somehow prone to overfitting and are thus unable to generalize well when datasets are small. The claim is not baseless and likely stems from the observation that PAC bounds on generalization error are usually so large for deep networks that they are vacuous (i.e., logically meaningless). Contrary to this, recent advances using the PAC-Bayesian framework have instead shown non-vacuous bounds on generalization error for large (stochastic) networks and standard datasets (e.g., MNIST and CIFAR-10). We apply these techniques to a much smaller medical imagining dataset (the ISIC 2018 challenge set). Further, we consider generalization of deep networks on segmentation tasks which has not commonly been done using the PAC-Bayesian framework. Importantly, we observe that the resultant bounds are also non-vacuous despite the sharp reduction in sample size. In total, our results demonstrate the applicability of PAC-Bayesian bounds for deep stochastic networks in the medical imaging domain.
Multi-Domain Learning by Meta-Learning: Taking Optimal Steps in Multi-Domain Loss Landscapes by Inner-Loop Learning
Feb 25, 2021

We consider a model-agnostic solution to the problem of Multi-Domain Learning (MDL) for multi-modal applications. Many existing MDL techniques are model-dependent solutions which explicitly require nontrivial architectural changes to construct domain-specific modules. Thus, properly applying these MDL techniques for new problems with well-established models, e.g. U-Net for semantic segmentation, may demand various low-level implementation efforts. In this paper, given emerging multi-modal data (e.g., various structural neuroimaging modalities), we aim to enable MDL purely algorithmically so that widely used neural networks can trivially achieve MDL in a model-independent manner. To this end, we consider a weighted loss function and extend it to an effective procedure by employing techniques from the recently active area of learning-to-learn (meta-learning). Specifically, we take inner-loop gradient steps to dynamically estimate posterior distributions over the hyperparameters of our loss function. Thus, our method is model-agnostic, requiring no additional model parameters and no network architecture changes; instead, only a few efficient algorithmic modifications are needed to improve performance in MDL. We demonstrate our solution to a fitting problem in medical imaging, specifically, in the automatic segmentation of white matter hyperintensity (WMH). We look at two neuroimaging modalities (T1-MR and FLAIR) with complementary information fitting for our problem.
Robust White Matter Hyperintensity Segmentation on Unseen Domain
Feb 17, 2021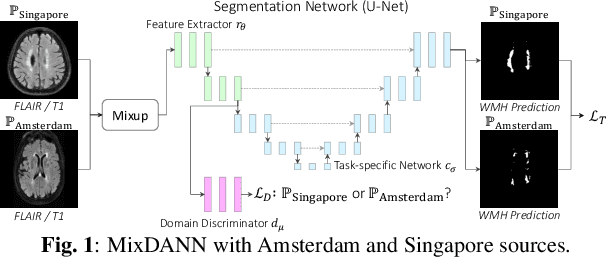
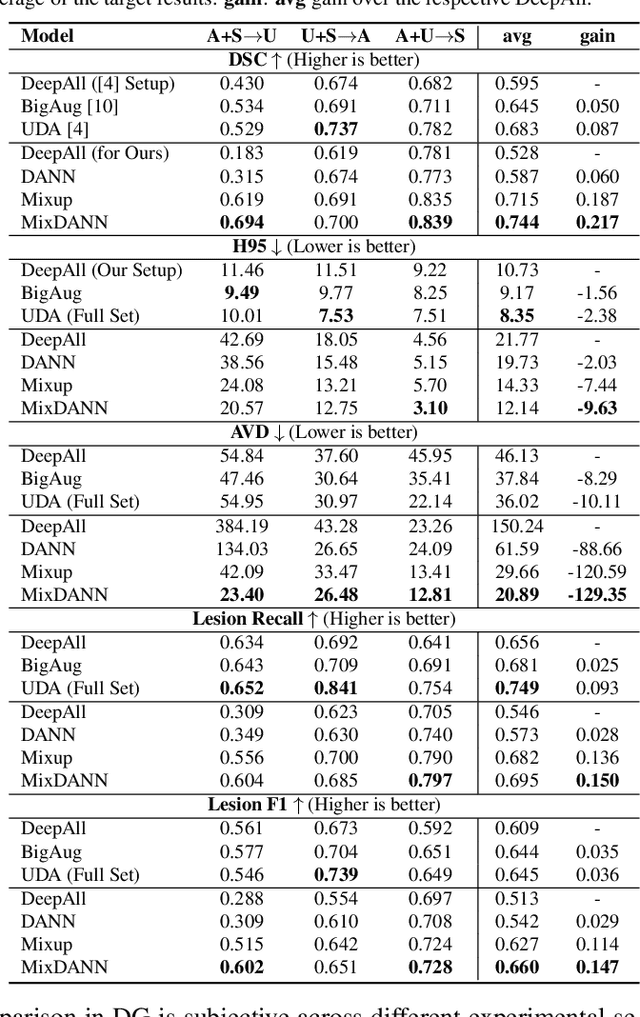
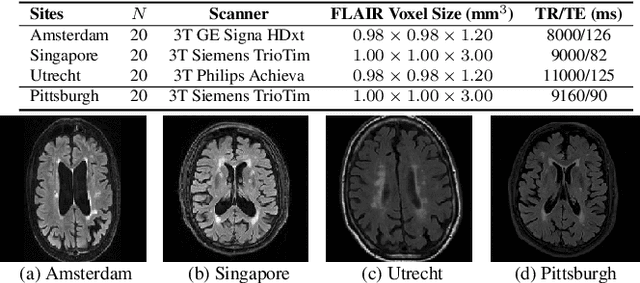
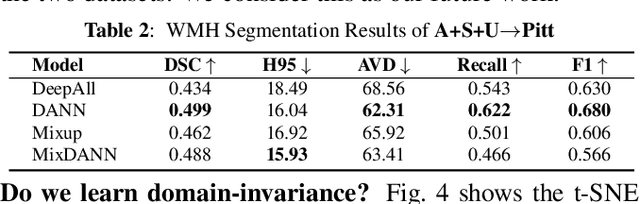
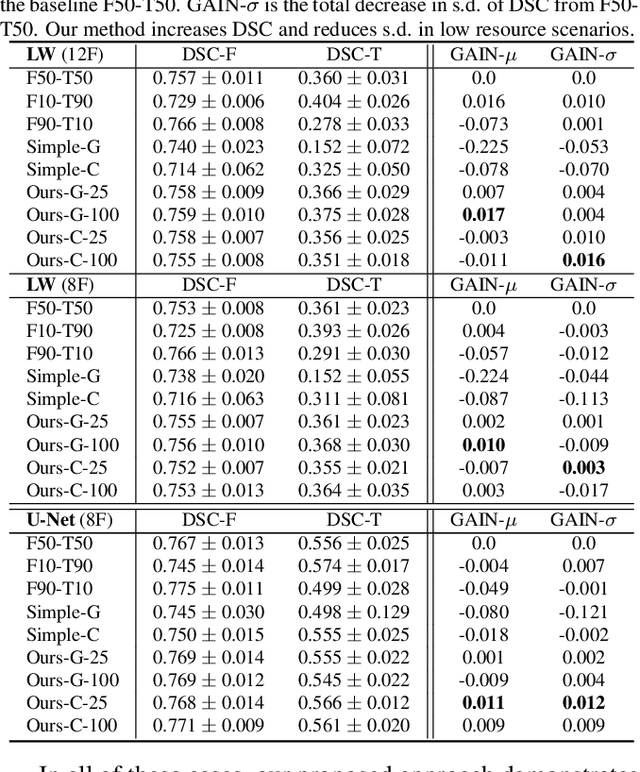
Typical machine learning frameworks heavily rely on an underlying assumption that training and test data follow the same distribution. In medical imaging which increasingly begun acquiring datasets from multiple sites or scanners, this identical distribution assumption often fails to hold due to systematic variability induced by site or scanner dependent factors. Therefore, we cannot simply expect a model trained on a given dataset to consistently work well, or generalize, on a dataset from another distribution. In this work, we address this problem, investigating the application of machine learning models to unseen medical imaging data. Specifically, we consider the challenging case of Domain Generalization (DG) where we train a model without any knowledge about the testing distribution. That is, we train on samples from a set of distributions (sources) and test on samples from a new, unseen distribution (target). We focus on the task of white matter hyperintensity (WMH) prediction using the multi-site WMH Segmentation Challenge dataset and our local in-house dataset. We identify how two mechanically distinct DG approaches, namely domain adversarial learning and mix-up, have theoretical synergy. Then, we show drastic improvements of WMH prediction on an unseen target domain.