 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs
Jan 10, 2025



The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.
Prefix-diffusion: A Lightweight Diffusion Model for Diverse Image Captioning
Sep 10, 2023

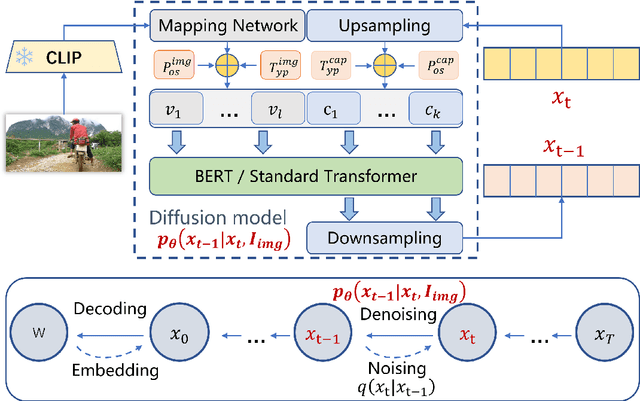

While impressive performance has been achieved in image captioning, the limited diversity of the generated captions and the large parameter scale remain major barriers to the real-word application of these systems. In this work, we propose a lightweight image captioning network in combination with continuous diffusion, called Prefix-diffusion. To achieve diversity, we design an efficient method that injects prefix image embeddings into the denoising process of the diffusion model. In order to reduce trainable parameters, we employ a pre-trained model to extract image features and further design an extra mapping network. Prefix-diffusion is able to generate diverse captions with relatively less parameters, while maintaining the fluency and relevance of the captions benefiting from the generative capabilities of the diffusion model. Our work paves the way for scaling up diffusion models for image captioning, and achieves promising performance compared with recent approaches.