 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoNet: Rotation-oriented Continuous Image Translation
Apr 06, 2024The generation of smooth and continuous images between domains has recently drawn much attention in image-to-image (I2I) translation. Linear relationship acts as the basic assumption in most existing approaches, while applied to different aspects including features, models or labels. However, the linear assumption is hard to conform with the element dimension increases and suffers from the limit that having to obtain both ends of the line. In this paper, we propose a novel rotation-oriented solution and model the continuous generation with an in-plane rotation over the style representation of an image, achieving a network named RoNet. A rotation module is implanted in the generation network to automatically learn the proper plane while disentangling the content and the style of an image. To encourage realistic texture, we also design a patch-based semantic style loss that learns the different styles of the similar object in different domains. We conduct experiments on forest scenes (where the complex texture makes the generation very challenging), faces, streetscapes and the iphone2dslr task. The results validate the superiority of our method in terms of visual quality and continuity.
Prefix-diffusion: A Lightweight Diffusion Model for Diverse Image Captioning
Sep 10, 2023

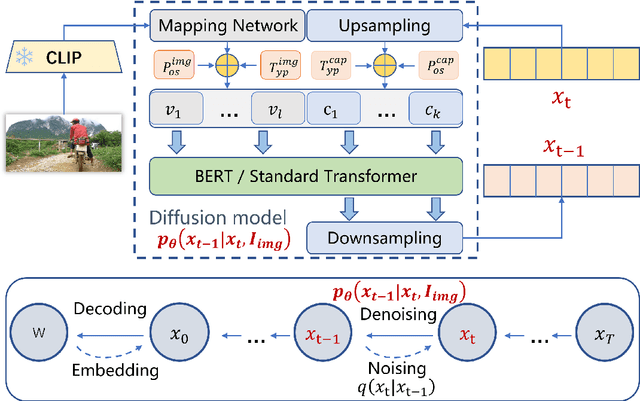

While impressive performance has been achieved in image captioning, the limited diversity of the generated captions and the large parameter scale remain major barriers to the real-word application of these systems. In this work, we propose a lightweight image captioning network in combination with continuous diffusion, called Prefix-diffusion. To achieve diversity, we design an efficient method that injects prefix image embeddings into the denoising process of the diffusion model. In order to reduce trainable parameters, we employ a pre-trained model to extract image features and further design an extra mapping network. Prefix-diffusion is able to generate diverse captions with relatively less parameters, while maintaining the fluency and relevance of the captions benefiting from the generative capabilities of the diffusion model. Our work paves the way for scaling up diffusion models for image captioning, and achieves promising performance compared with recent approaches.
A Survey to Deep Facial Attribute Analysis
Dec 26, 2018

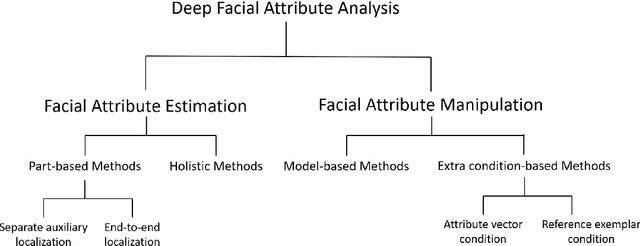

Facial attribute analysis has received considerable attention with the development of deep neural networks in the past few years. Facial attribute analysis contains two crucial issues: Facial Attribute Estimation (FAE), which recognizes whether facial attributes are present in given images, and Facial Attribute Manipulation (FAM), which synthesizes or removes desired facial attributes. In this paper, we provide a comprehensive survey on deep facial attribute analysis covering FAE and FAM. First, we present the basic knowledge of the two stages (i.e., data pre-processing and model construction) in the general deep facial attribute analysis pipeline. Second, we summarize the commonly used datasets and performance metrics. Third, we create a taxonomy of the state-of-the-arts and review detailed algorithms in FAE and FAM, respectively. Furthermore, we introduce several additional facial attribute related issues and applications. Finally, the possible challenges and future research directions are discussed.
Joint Adaptive Neighbours and Metric Learning for Multi-view Subspace Clustering
Sep 12, 2017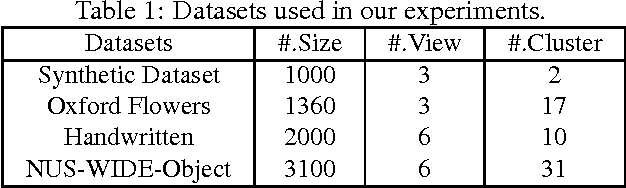
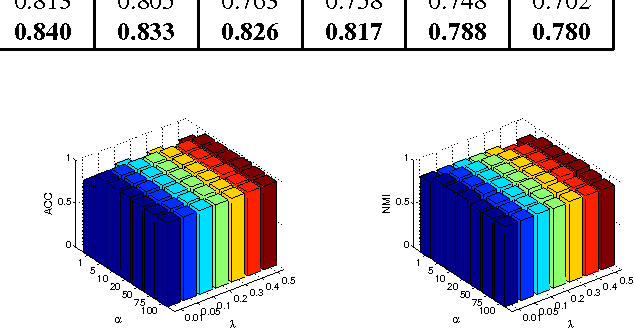


Due to the existence of various views or representations in many real-world data, multi-view learning has drawn much attention recently. Multi-view spectral clustering methods based on similarity matrixes or graphs are pretty popular. Generally, these algorithms learn informative graphs by directly utilizing original data. However, in the real-world applications, original data often contain noises and outliers that lead to unreliable graphs. In addition, different views may have different contributions to data clustering. In this paper, a novel Multiview Subspace Clustering method unifying Adaptive neighbours and Metric learning (MSCAM), is proposed to address the above problems. In this method, we use the subspace representations of different views to adaptively learn a consensus similarity matrix, uncovering the subspace structure and avoiding noisy nature of original data. For all views, we also learn different Mahalanobis matrixes that parameterize the squared distances and consider the contributions of different views. Further, we constrain the graph constructed by the similarity matrix to have exact c (c is the number of clusters) connected components. An iterative algorithm is developed to solve this optimization problem. Moreover, experiments on a synthetic dataset and different real-world datasets demonstrate the effectiveness of MSCAM.