 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePelican: Correcting Hallucination in Vision-LLMs via Claim Decomposition and Program of Thought Verification
Paper and Code
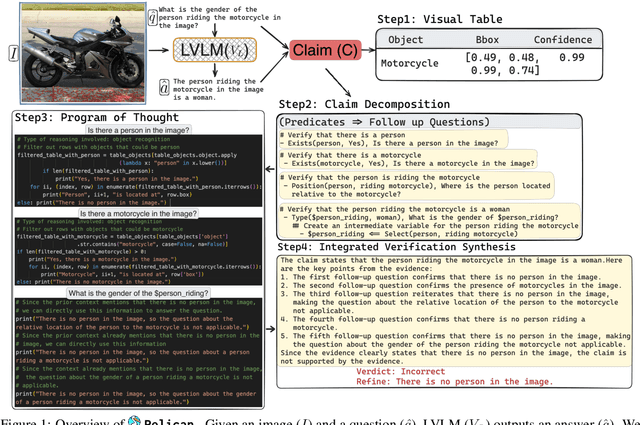
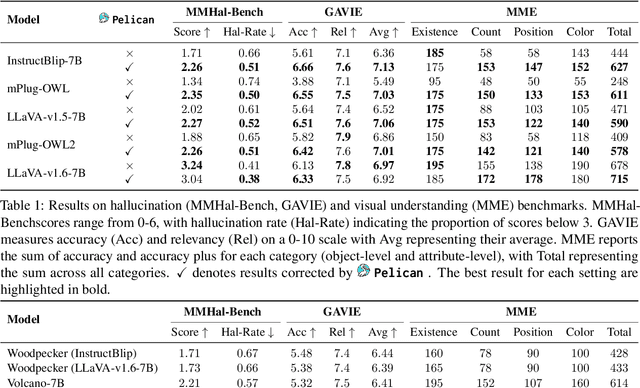
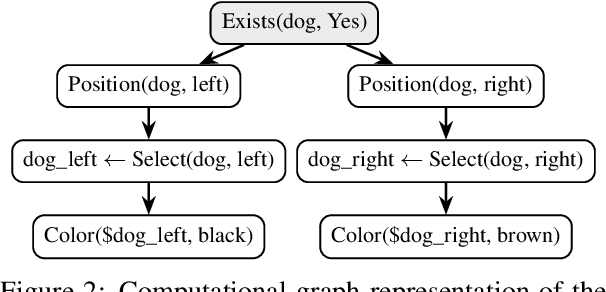

Large Visual Language Models (LVLMs) struggle with hallucinations in visual instruction following task(s), limiting their trustworthiness and real-world applicability. We propose Pelican -- a novel framework designed to detect and mitigate hallucinations through claim verification. Pelican first decomposes the visual claim into a chain of sub-claims based on first-order predicates. These sub-claims consist of (predicate, question) pairs and can be conceptualized as nodes of a computational graph. We then use Program-of-Thought prompting to generate Python code for answering these questions through flexible composition of external tools. Pelican improves over prior work by introducing (1) intermediate variables for precise grounding of object instances, and (2) shared computation for answering the sub-question to enable adaptive corrections and inconsistency identification. We finally use reasoning abilities of LLM to verify the correctness of the the claim by considering the consistency and confidence of the (question, answer) pairs from each sub-claim. Our experiments reveal a drop in hallucination rate by $\sim$8%-32% across various baseline LVLMs and a 27% drop compared to approaches proposed for hallucination mitigation on MMHal-Bench. Results on two other benchmarks further corroborate our results.