 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Net: Fine-Level Face Alignment through Anchors and Contours Estimation
Dec 02, 2020

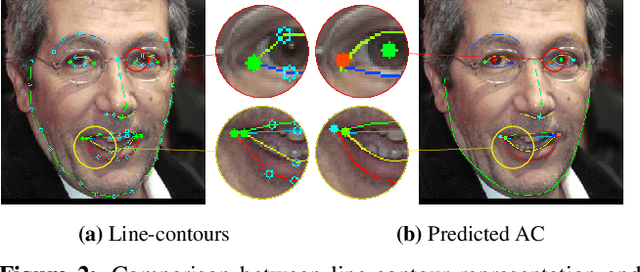

We propose a novel facial Anchors and Contours Estimation framework, ACE-Net, for fine-level face alignment tasks. ACE-Net predicts facial anchors and contours that are richer than traditional facial landmarks and more accurate than facial boundaries. In addition, it does not suffer from the ambiguities and inconsistencies in facial-landmarks definitions. We introduce a weakly supervised loss enabling ACE-Net to learn from existing facial landmarks datasets without the need for extra annotations. Synthetic data is also used during training to bridge the density gap between landmarks annotation and true facial contours. We evaluate ACE-Net on commonly used face alignment datasets 300-W and HELEN, and show that ACE-Net achieves significantly higher fine-level face alignment accuracy than landmarks based models, without compromising its performance at the landmarks level. The proposed ACE-Net framework does not rely on any specific network architecture and thus can be applied on top of existing face alignment models for finer face alignment representation.
Zero-Shot Learning with Knowledge Enhanced Visual Semantic Embeddings
Nov 21, 2020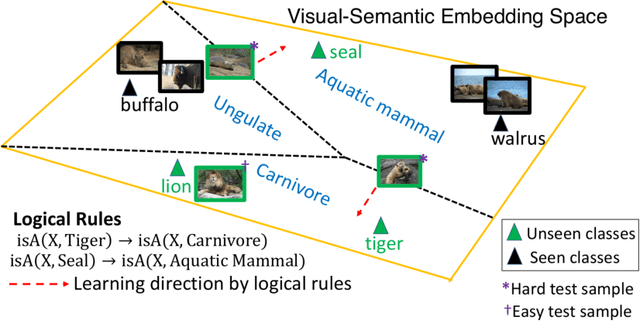
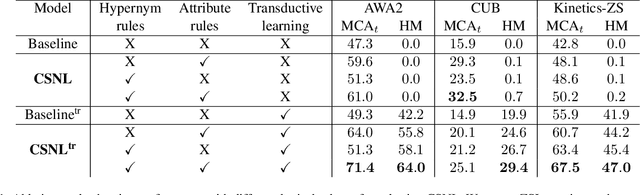
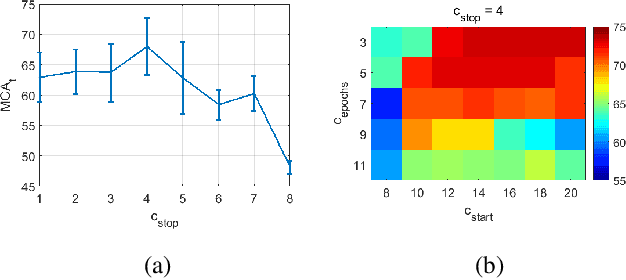

We improve zero-shot learning (ZSL) by incorporating common-sense knowledge in DNNs. We propose Common-Sense based Neuro-Symbolic Loss (CSNL) that formulates prior knowledge as novel neuro-symbolic loss functions that regularize visual-semantic embedding. CSNL forces visual features in the VSE to obey common-sense rules relating to hypernyms and attributes. We introduce two key novelties for improved learning: (1) enforcement of rules for a group instead of a single concept to take into account class-wise relationships, and (2) confidence margins inside logical operators that enable implicit curriculum learning and prevent premature overfitting. We evaluate the advantages of incorporating each knowledge source and show consistent gains over prior state-of-art methods in both conventional and generalized ZSL e.g. 11.5%, 5.5%, and 11.6% improvements on AWA2, CUB, and Kinetics respectively.