 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVP: Generating Visual Puzzles with Contrastive Hierarchical VAEs
Mar 30, 2025Raven's Progressive Matrices (RPMs) is an established benchmark to examine the ability to perform high-level abstract visual reasoning (AVR). Despite the current success of algorithms that solve this task, humans can generalize beyond a given puzzle and create new puzzles given a set of rules, whereas machines remain locked in solving a fixed puzzle from a curated choice list. We propose Generative Visual Puzzles (GenVP), a framework to model the entire RPM generation process, a substantially more challenging task. Our model's capability spans from generating multiple solutions for one specific problem prompt to creating complete new puzzles out of the desired set of rules. Experiments on five different datasets indicate that GenVP achieves state-of-the-art (SOTA) performance both in puzzle-solving accuracy and out-of-distribution (OOD) generalization in 22 OOD scenarios. Compared to SOTA generative approaches, which struggle to solve RPMs when the feasible solution space increases, GenVP efficiently generalizes to these challenging setups. Moreover, our model demonstrates the ability to produce a wide range of complete RPMs given a set of abstract rules by effectively capturing the relationships between abstract rules and visual object properties.
Box2Flow: Instance-based Action Flow Graphs from Videos
Aug 30, 2024A large amount of procedural videos on the web show how to complete various tasks. These tasks can often be accomplished in different ways and step orderings, with some steps able to be performed simultaneously, while others are constrained to be completed in a specific order. Flow graphs can be used to illustrate the step relationships of a task. Current task-based methods try to learn a single flow graph for all available videos of a specific task. The extracted flow graphs tend to be too abstract, failing to capture detailed step descriptions. In this work, our aim is to learn accurate and rich flow graphs by extracting them from a single video. We propose Box2Flow, an instance-based method to predict a step flow graph from a given procedural video. In detail, we extract bounding boxes from videos, predict pairwise edge probabilities between step pairs, and build the flow graph with a spanning tree algorithm. Experiments on MM-ReS and YouCookII show our method can extract flow graphs effectively.
CIC-BART-SSA: Controllable Image Captioning with Structured Semantic Augmentation
Jul 16, 2024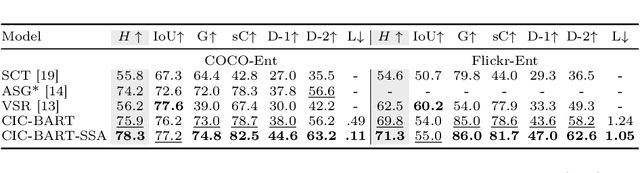


Controllable Image Captioning (CIC) aims at generating natural language descriptions for an image, conditioned on information provided by end users, e.g., regions, entities or events of interest. However, available image--language datasets mainly contain captions that describe the entirety of an image, making them ineffective for training CIC models that can potentially attend to any subset of regions or relationships. To tackle this challenge, we propose a novel, fully automatic method to sample additional focused and visually grounded captions using a unified structured semantic representation built on top of the existing set of captions associated with an image. We leverage Abstract Meaning Representation (AMR), a cross-lingual graph-based semantic formalism, to encode all possible spatio-semantic relations between entities, beyond the typical spatial-relations-only focus of current methods. We use this Structured Semantic Augmentation (SSA) framework to augment existing image--caption datasets with the grounded controlled captions, increasing their spatial and semantic diversity and focal coverage. We then develop a new model, CIC-BART-SSA, specifically tailored for the CIC task, that sources its control signals from SSA-diversified datasets. We empirically show that, compared to SOTA CIC models, CIC-BART-SSA generates captions that are superior in diversity and text quality, are competitive in controllability, and, importantly, minimize the gap between broad and highly focused controlled captioning performance by efficiently generalizing to the challenging highly focused scenarios. Code is available at https://github.com/SamsungLabs/CIC-BART-SSA.
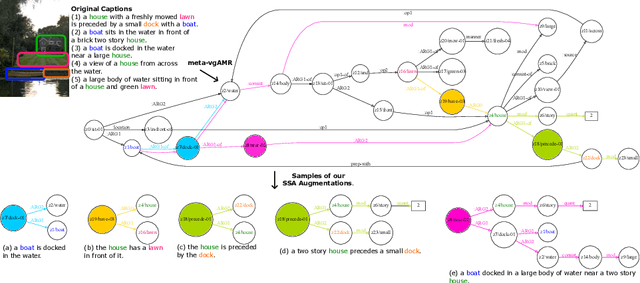
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
SAViR-T: Spatially Attentive Visual Reasoning with Transformers
Jun 22, 2022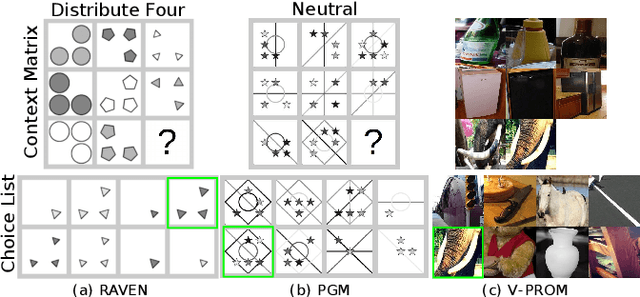
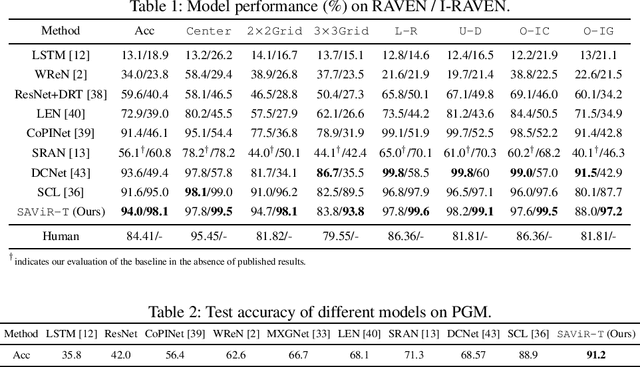
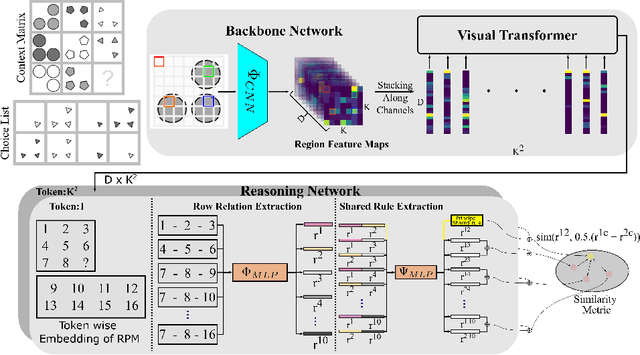
We present a novel computational model, "SAViR-T", for the family of visual reasoning problems embodied in the Raven's Progressive Matrices (RPM). Our model considers explicit spatial semantics of visual elements within each image in the puzzle, encoded as spatio-visual tokens, and learns the intra-image as well as the inter-image token dependencies, highly relevant for the visual reasoning task. Token-wise relationship, modeled through a transformer-based SAViR-T architecture, extract group (row or column) driven representations by leveraging the group-rule coherence and use this as the inductive bias to extract the underlying rule representations in the top two row (or column) per token in the RPM. We use this relation representations to locate the correct choice image that completes the last row or column for the RPM. Extensive experiments across both synthetic RPM benchmarks, including RAVEN, I-RAVEN, RAVEN-FAIR, and PGM, and the natural image-based "V-PROM" demonstrate that SAViR-T sets a new state-of-the-art for visual reasoning, exceeding prior models' performance by a considerable margin.
Image De-Quantization Using Generative Models as Priors
Jul 17, 2020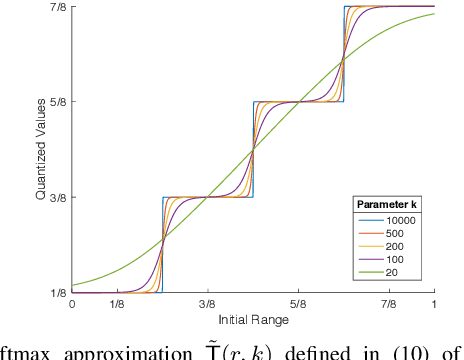
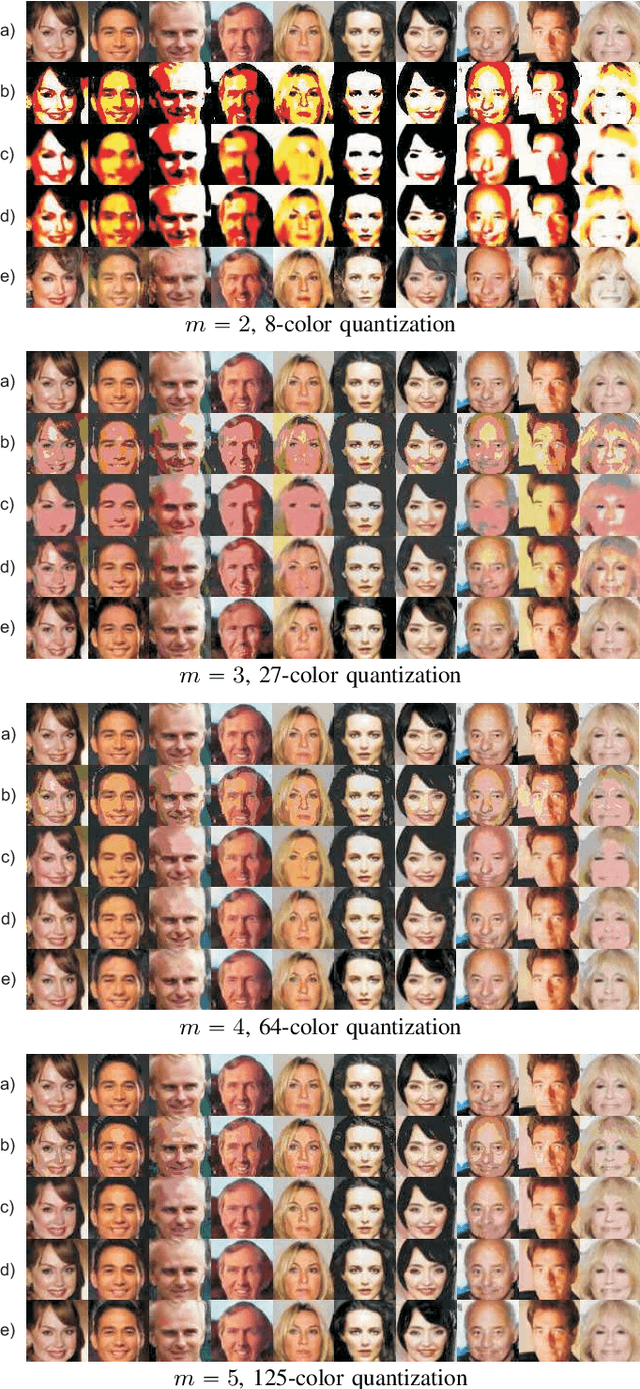


Image quantization is used in several applications aiming in reducing the number of available colors in an image and therefore its size. De-quantization is the task of reversing the quantization effect and recovering the original multi-chromatic level image. Existing techniques achieve de-quantization by imposing suitable constraints on the ideal image in order to make the recovery problem feasible since it is otherwise ill-posed. Our goal in this work is to develop a de-quantization mechanism through a rigorous mathematical analysis which is based on the classical statistical estimation theory. In this effort we incorporate generative modeling of the ideal image as a suitable prior information. The resulting technique is simple and capable of de-quantizing successfully images that have experienced severe quantization effects. Interestingly, our method can recover images even if the quantization process is not exactly known and contains unknown parameters.
Image Restoration from Parametric Transformations using Generative Models
Jun 16, 2020


When images are statistically described by a generative model we can use this information to develop optimum techniques for various image restoration problems as inpainting, super-resolution, image coloring, generative model inversion, etc. With the help of the generative model it is possible to formulate, in a natural way, these restoration problems as Statistical estimation problems. Our approach, by combining maximum a-posteriori probability with maximum likelihood estimation, is capable of restoring images that are distorted by transformations even when the latter contain unknown parameters. The resulting optimization is completely defined with no parameters requiring tuning. This must be compared with the current state of the art which requires exact knowledge of the transformations and contains regularizer terms with weights that must be properly defined. Finally, we must mention that we extend our method to accommodate mixtures of multiple images where each image is described by its own generative model and we are able of successfully separating each participating image from a single mixture.
Designing GANs: A Likelihood Ratio Approach
Feb 06, 2020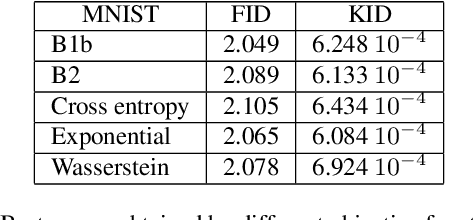
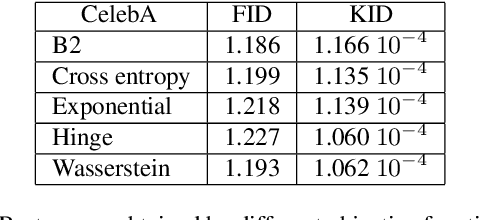
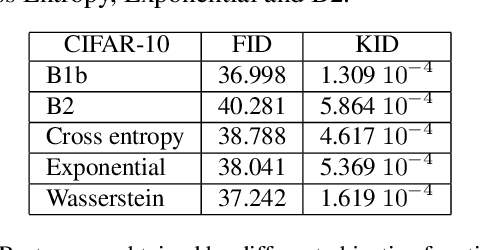

We are interested in the design of generative adversarial networks. The training of these mathematical structures requires the definition of proper min-max optimization problems. We propose a simple methodology for constructing such problems assuring, at the same time, that they provide the correct answer. We give characteristic examples developed by our method, some of which can be recognized from other applications and some introduced for the first time. We compare various possibilities by applying them to well known datasets using neural networks of different configurations and sizes.
Training Neural Networks for Likelihood/Density Ratio Estimation
Nov 05, 2019
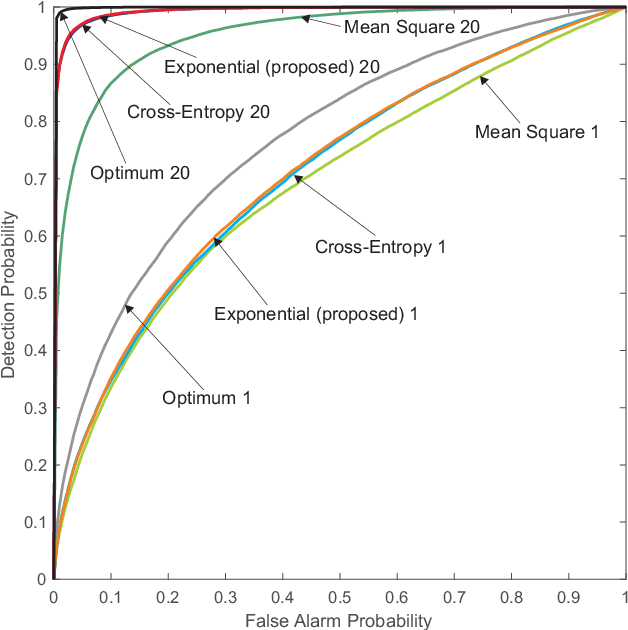

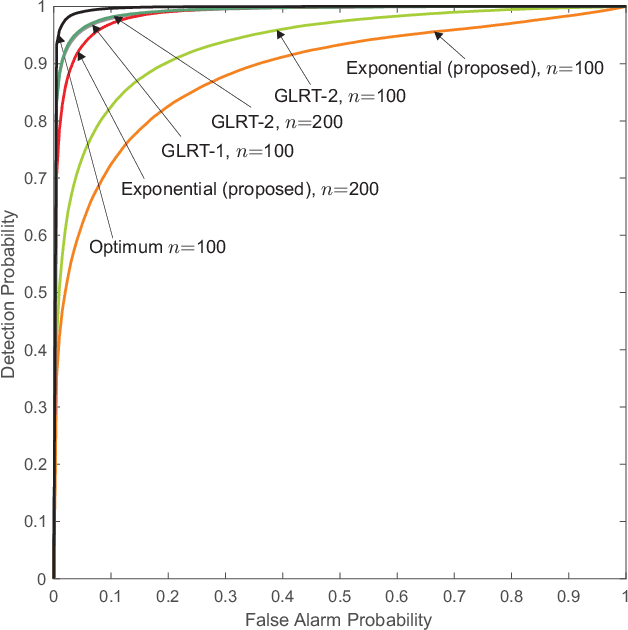
Various problems in Engineering and Statistics require the computation of the likelihood ratio function of two probability densities. In classical approaches the two densities are assumed known or to belong to some known parametric family. In a data-driven version we replace this requirement with the availability of data sampled from the densities of interest. For most well known problems in Detection and Hypothesis testing we develop solutions by providing neural network based estimates of the likelihood ratio or its transformations. This task necessitates the definition of proper optimizations which can be used for the training of the network. The main purpose of this work is to offer a simple and unified methodology for defining such optimization problems with guarantees that the solution is indeed the desired function. Our results are extended to cover estimates for likelihood ratios of conditional densities and estimates for statistics encountered in local approaches.
Optimizing Shallow Networks for Binary Classification
May 24, 2019
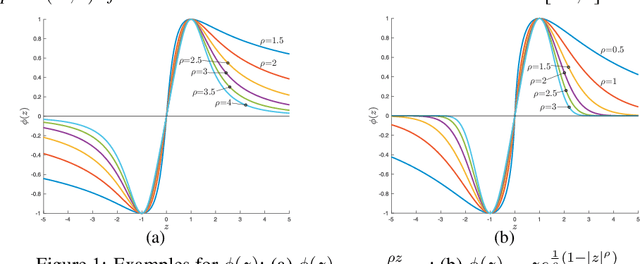

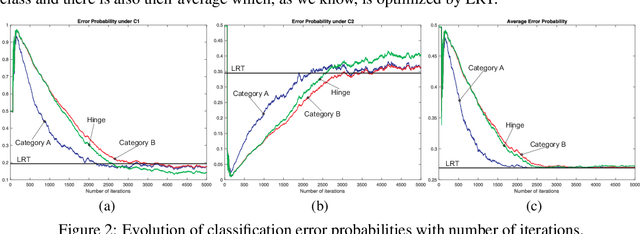
Data driven classification that relies on neural networks is based on optimization criteria that involve some form of distance between the output of the network and the desired label. Using the same mathematical mathematical analysis, for a multitude of such measures, we can show that their optimum solution matches the ideal likelihood ratio test classifier. In this work we introduce a different family of optimization problems which is not covered by the existing approaches and, therefore, opens possibilities for new training algorithms for neural network based classification. We give examples that lead to algorithms that are simple in implementation, exhibit stable convergence characteristics and are antagonistic to the most popular existing techniques.