 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Shallow Networks for Binary Classification
Paper and Code
May 24, 2019
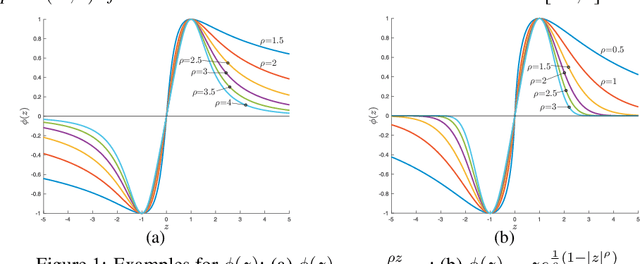

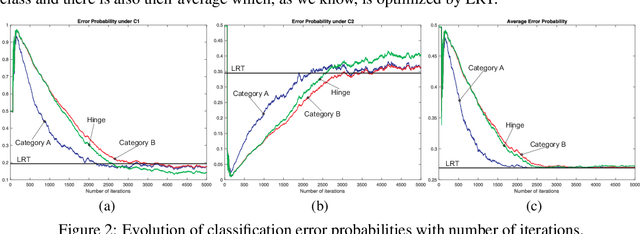
Data driven classification that relies on neural networks is based on optimization criteria that involve some form of distance between the output of the network and the desired label. Using the same mathematical mathematical analysis, for a multitude of such measures, we can show that their optimum solution matches the ideal likelihood ratio test classifier. In this work we introduce a different family of optimization problems which is not covered by the existing approaches and, therefore, opens possibilities for new training algorithms for neural network based classification. We give examples that lead to algorithms that are simple in implementation, exhibit stable convergence characteristics and are antagonistic to the most popular existing techniques.