 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Pixel Control: Challenges and Prospects
Aug 08, 2024
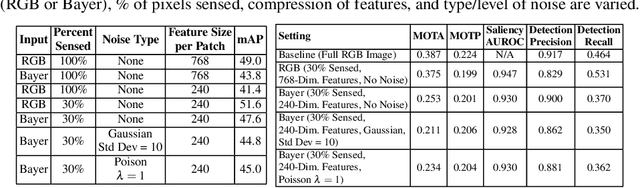

Recent advancements in sensors have led to high resolution and high data throughput at the pixel level. Simultaneously, the adoption of increasingly large (deep) neural networks (NNs) has lead to significant progress in computer vision. Currently, visual intelligence comes at increasingly high computational complexity, energy, and latency. We study a data-driven system that combines dynamic sensing at the pixel level with computer vision analytics at the video level and propose a feedback control loop to minimize data movement between the sensor front-end and computational back-end without compromising detection and tracking precision. Our contributions are threefold: (1) We introduce anticipatory attention and show that it leads to high precision prediction with sparse activation of pixels; (2) Leveraging the feedback control, we show that the dimensionality of learned feature vectors can be significantly reduced with increased sparsity; and (3) We emulate analog design choices (such as varying RGB or Bayer pixel format and analog noise) and study their impact on the key metrics of the data-driven system. Comparative analysis with traditional pixel and deep learning models shows significant performance enhancements. Our system achieves a 10X reduction in bandwidth and a 15-30X improvement in Energy-Delay Product (EDP) when activating only 30% of pixels, with a minor reduction in object detection and tracking precision. Based on analog emulation, our system can achieve a throughput of 205 megapixels/sec (MP/s) with a power consumption of only 110 mW per MP, i.e., a theoretical improvement of ~30X in EDP.
Improving the Robustness of Quantized Deep Neural Networks to White-Box Attacks using Stochastic Quantization and Information-Theoretic Ensemble Training
Nov 30, 2023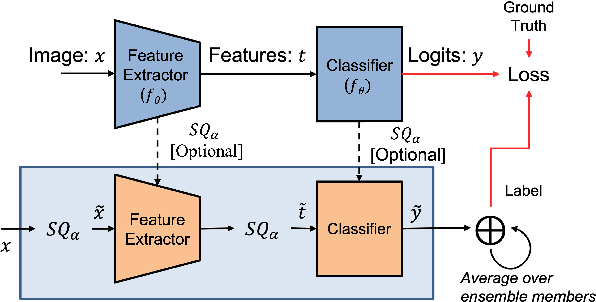



Most real-world applications that employ deep neural networks (DNNs) quantize them to low precision to reduce the compute needs. We present a method to improve the robustness of quantized DNNs to white-box adversarial attacks. We first tackle the limitation of deterministic quantization to fixed ``bins'' by introducing a differentiable Stochastic Quantizer (SQ). We explore the hypothesis that different quantizations may collectively be more robust than each quantized DNN. We formulate a training objective to encourage different quantized DNNs to learn different representations of the input image. The training objective captures diversity and accuracy via mutual information between ensemble members. Through experimentation, we demonstrate substantial improvement in robustness against $L_\infty$ attacks even if the attacker is allowed to backpropagate through SQ (e.g., > 50\% accuracy to PGD(5/255) on CIFAR10 without adversarial training), compared to vanilla DNNs as well as existing ensembles of quantized DNNs. We extend the method to detect attacks and generate robustness profiles in the adversarial information plane (AIP), towards a unified analysis of different threat models by correlating the MI and accuracy.
Real-time Hyper-Dimensional Reconfiguration at the Edge using Hardware Accelerators
Jun 10, 2022
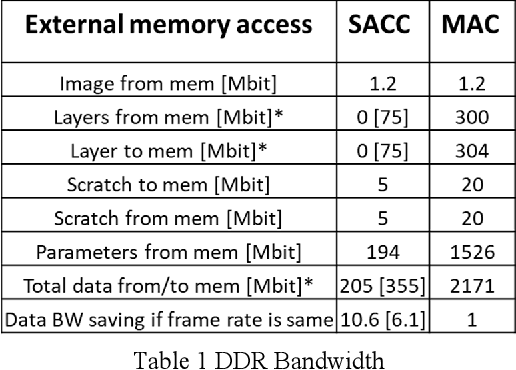
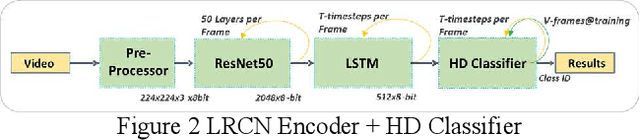
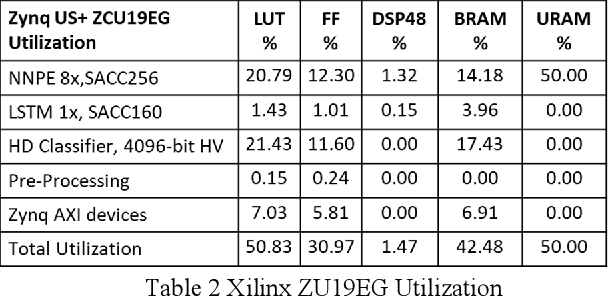
In this paper we present Hyper-Dimensional Reconfigurable Analytics at the Tactical Edge (HyDRATE) using low-SWaP embedded hardware that can perform real-time reconfiguration at the edge leveraging non-MAC (free of floating-point MultiplyACcumulate operations) deep neural nets (DNN) combined with hyperdimensional (HD) computing accelerators. We describe the algorithm, trained quantized model generation, and simulated performance of a feature extractor free of multiply-accumulates feeding a hyperdimensional logic-based classifier. Then we show how performance increases with the number of hyperdimensions. We describe the realized low-SWaP FPGA hardware and embedded software system compared to traditional DNNs and detail the implemented hardware accelerators. We discuss the measured system latency and power, noise robustness due to use of learnable quantization and HD computing, actual versus simulated system performance for a video activity classification task and demonstration of reconfiguration on this same dataset. We show that reconfigurability in the field is achieved by retraining only the feed-forward HD classifier without gradient descent backpropagation (gradient-free), using few-shot learning of new classes at the edge. Initial work performed used LRCN DNN and is currently extended to use Two-stream DNN with improved performance.
Saccade Mechanisms for Image Classification, Object Detection and Tracking
Jun 10, 2022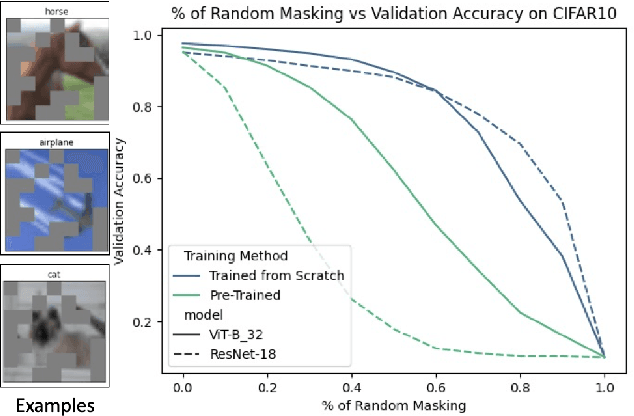
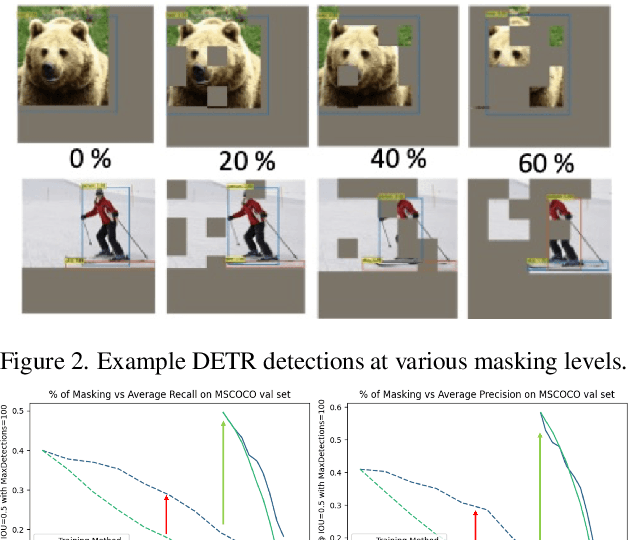

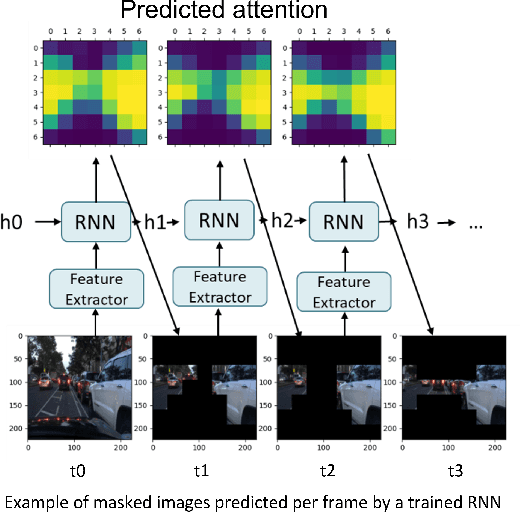
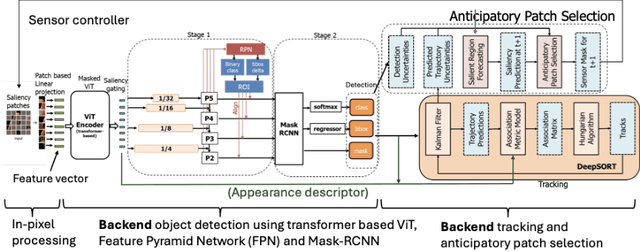
We examine how the saccade mechanism from biological vision can be used to make deep neural networks more efficient for classification and object detection problems. Our proposed approach is based on the ideas of attention-driven visual processing and saccades, miniature eye movements influenced by attention. We conduct experiments by analyzing: i) the robustness of different deep neural network (DNN) feature extractors to partially-sensed images for image classification and object detection, and ii) the utility of saccades in masking image patches for image classification and object tracking. Experiments with convolutional nets (ResNet-18) and transformer-based models (ViT, DETR, TransTrack) are conducted on several datasets (CIFAR-10, DAVSOD, MSCOCO, and MOT17). Our experiments show intelligent data reduction via learning to mimic human saccades when used in conjunction with state-of-the-art DNNs for classification, detection, and tracking tasks. We observed minimal drop in performance for the classification and detection tasks while only using about 30\% of the original sensor data. We discuss how the saccade mechanism can inform hardware design via ``in-pixel'' processing.