 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model Adaptation for Continual Learning at the Edge
Aug 03, 2023



Most machine learning (ML) systems assume stationary and matching data distributions during training and deployment. This is often a false assumption. When ML models are deployed on real devices, data distributions often shift over time due to changes in environmental factors, sensor characteristics, and task-of-interest. While it is possible to have a human-in-the-loop to monitor for distribution shifts and engineer new architectures in response to these shifts, such a setup is not cost-effective. Instead, non-stationary automated ML (AutoML) models are needed. This paper presents the Encoder-Adaptor-Reconfigurator (EAR) framework for efficient continual learning under domain shifts. The EAR framework uses a fixed deep neural network (DNN) feature encoder and trains shallow networks on top of the encoder to handle novel data. The EAR framework is capable of 1) detecting when new data is out-of-distribution (OOD) by combining DNNs with hyperdimensional computing (HDC), 2) identifying low-parameter neural adaptors to adapt the model to the OOD data using zero-shot neural architecture search (ZS-NAS), and 3) minimizing catastrophic forgetting on previous tasks by progressively growing the neural architecture as needed and dynamically routing data through the appropriate adaptors and reconfigurators for handling domain-incremental and class-incremental continual learning. We systematically evaluate our approach on several benchmark datasets for domain adaptation and demonstrate strong performance compared to state-of-the-art algorithms for OOD detection and few-/zero-shot NAS.
Learning with Local Gradients at the Edge
Aug 17, 2022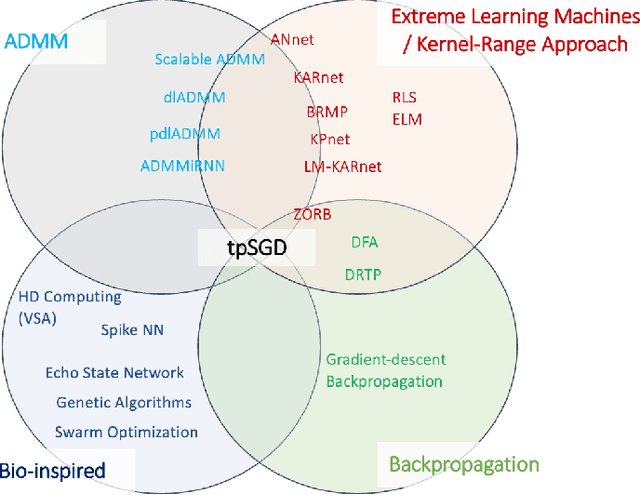
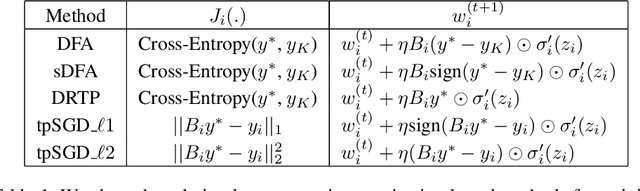

To enable learning on edge devices with fast convergence and low memory, we present a novel backpropagation-free optimization algorithm dubbed Target Projection Stochastic Gradient Descent (tpSGD). tpSGD generalizes direct random target projection to work with arbitrary loss functions and extends target projection for training recurrent neural networks (RNNs) in addition to feedforward networks. tpSGD uses layer-wise stochastic gradient descent (SGD) and local targets generated via random projections of the labels to train the network layer-by-layer with only forward passes. tpSGD doesn't require retaining gradients during optimization, greatly reducing memory allocation compared to SGD backpropagation (BP) methods that require multiple instances of the entire neural network weights, input/output, and intermediate results. Our method performs comparably to BP gradient-descent within 5% accuracy on relatively shallow networks of fully connected layers, convolutional layers, and recurrent layers. tpSGD also outperforms other state-of-the-art gradient-free algorithms in shallow models consisting of multi-layer perceptrons, convolutional neural networks (CNNs), and RNNs with competitive accuracy and less memory and time. We evaluate the performance of tpSGD in training deep neural networks (e.g. VGG) and extend the approach to multi-layer RNNs. These experiments highlight new research directions related to optimized layer-based adaptor training for domain-shift using tpSGD at the edge.
Real-time Hyper-Dimensional Reconfiguration at the Edge using Hardware Accelerators
Jun 10, 2022
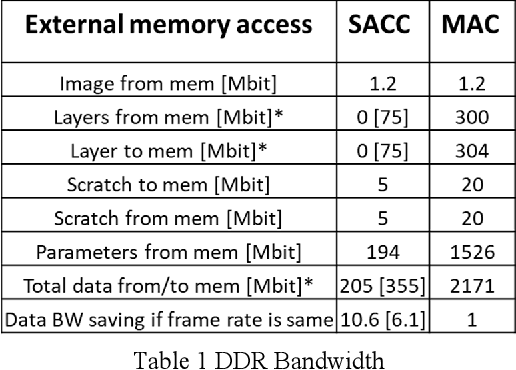
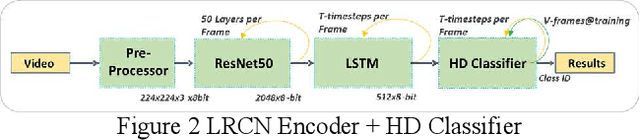
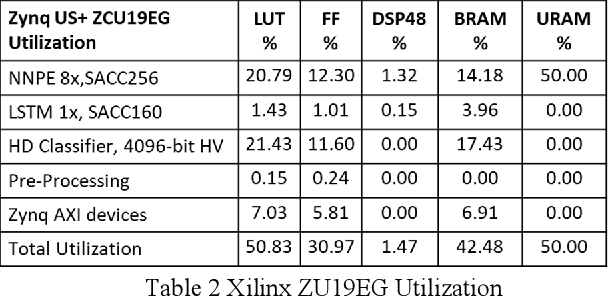
In this paper we present Hyper-Dimensional Reconfigurable Analytics at the Tactical Edge (HyDRATE) using low-SWaP embedded hardware that can perform real-time reconfiguration at the edge leveraging non-MAC (free of floating-point MultiplyACcumulate operations) deep neural nets (DNN) combined with hyperdimensional (HD) computing accelerators. We describe the algorithm, trained quantized model generation, and simulated performance of a feature extractor free of multiply-accumulates feeding a hyperdimensional logic-based classifier. Then we show how performance increases with the number of hyperdimensions. We describe the realized low-SWaP FPGA hardware and embedded software system compared to traditional DNNs and detail the implemented hardware accelerators. We discuss the measured system latency and power, noise robustness due to use of learnable quantization and HD computing, actual versus simulated system performance for a video activity classification task and demonstration of reconfiguration on this same dataset. We show that reconfigurability in the field is achieved by retraining only the feed-forward HD classifier without gradient descent backpropagation (gradient-free), using few-shot learning of new classes at the edge. Initial work performed used LRCN DNN and is currently extended to use Two-stream DNN with improved performance.
A general approach to bridge the reality-gap
Sep 03, 2020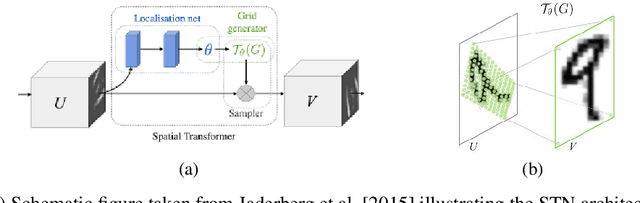

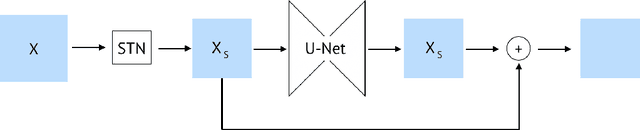
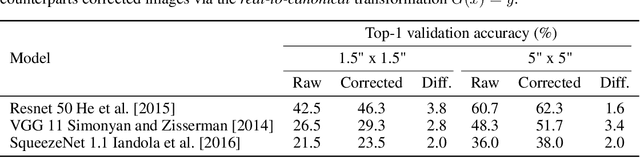
Employing machine learning models in the real world requires collecting large amounts of data, which is both time consuming and costly to collect. A common approach to circumvent this is to leverage existing, similar data-sets with large amounts of labelled data. However, models trained on these canonical distributions do not readily transfer to real-world ones. Domain adaptation and transfer learning are often used to breach this "reality gap", though both require a substantial amount of real-world data. In this paper we discuss a more general approach: we propose learning a general transformation to bring arbitrary images towards a canonical distribution where we can naively apply the trained machine learning models. This transformation is trained in an unsupervised regime, leveraging data augmentation to generate off-canonical examples of images and training a Deep Learning model to recover their original counterpart. We quantify the performance of this transformation using pre-trained ImageNet classifiers, demonstrating that this procedure can recover half of the loss in performance on the distorted data-set. We then validate the effectiveness of this approach on a series of pre-trained ImageNet models on a real world data set collected by printing and photographing images in different lighting conditions.
Reducing audio membership inference attack accuracy to chance: 4 defenses
Oct 31, 2019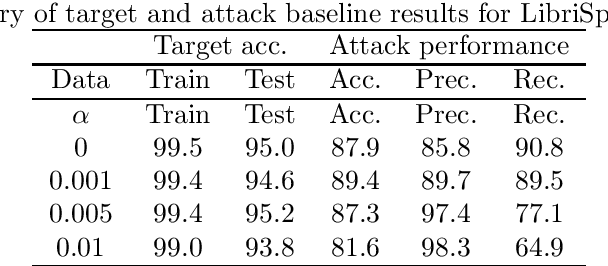
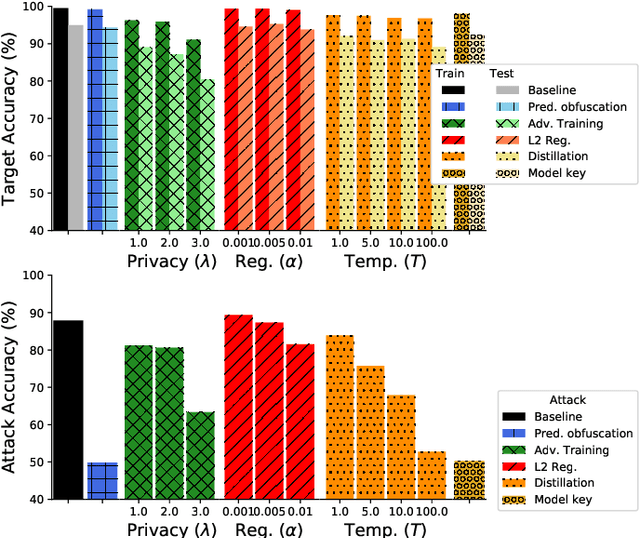
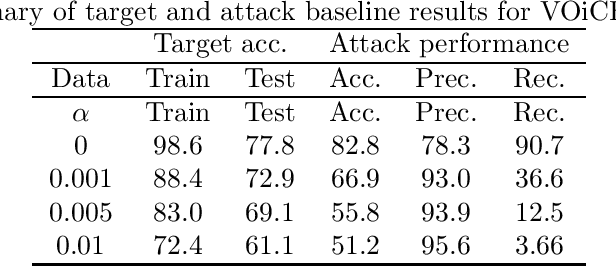
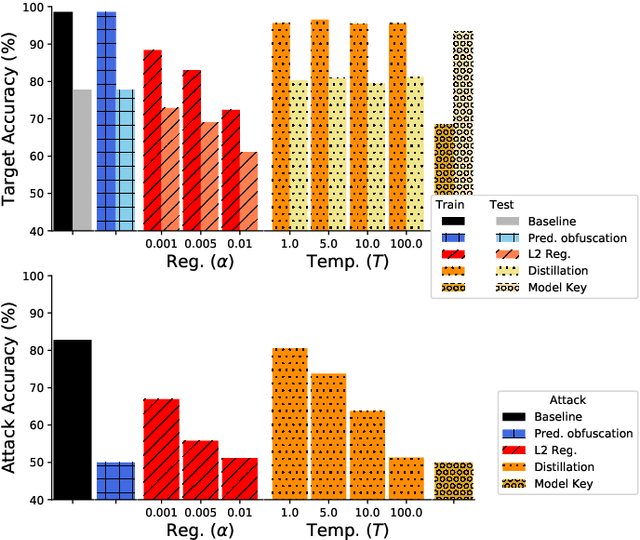
It is critical to understand the privacy and robustness vulnerabilities of machine learning models, as their implementation expands in scope. In membership inference attacks, adversaries can determine whether a particular set of data was used in training, putting the privacy of the data at risk. Existing work has mostly focused on image related tasks; we generalize this type of attack to speaker identification on audio samples. We demonstrate attack precision of 85.9\% and recall of 90.8\% for LibriSpeech, and 78.3\% precision and 90.7\% recall for VOiCES (Voices Obscured in Complex Environmental Settings). We find that implementing defenses such as prediction obfuscation, defensive distillation or adversarial training, can reduce attack accuracy to chance.
Robust or Private? Adversarial Training Makes Models More Vulnerable to Privacy Attacks
Jun 15, 2019
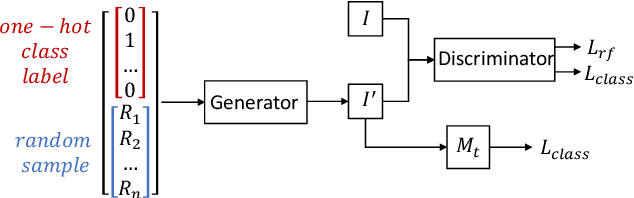

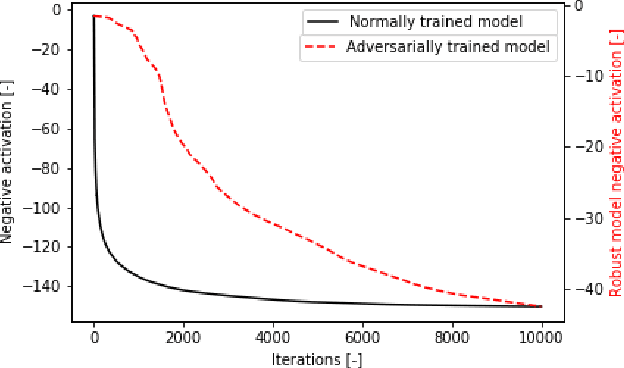
Adversarial training was introduced as a way to improve the robustness of deep learning models to adversarial attacks. This training method improves robustness against adversarial attacks, but increases the models vulnerability to privacy attacks. In this work we demonstrate how model inversion attacks, extracting training data directly from the model, previously thought to be intractable become feasible when attacking a robustly trained model. The input space for a traditionally trained model is dominated by adversarial examples - data points that strongly activate a certain class but lack semantic meaning - this makes it difficult to successfully conduct model inversion attacks. We demonstrate this effect using the CIFAR-10 dataset under three different model inversion attacks, a vanilla gradient descent method, gradient based method at different scales, and a generative adversarial network base attacks.