 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset
Oct 09, 2020



We present MLQE-PE, a new dataset for Machine Translation (MT) Quality Estimation (QE) and Automatic Post-Editing (APE). The dataset contains seven language pairs, with human labels for 9,000 translations per language pair in the following formats: sentence-level direct assessments and post-editing effort, and word-level good/bad labels. It also contains the post-edited sentences, as well as titles of the articles where the sentences were extracted from, and the neural MT models used to translate the text.
A general approach to bridge the reality-gap
Sep 03, 2020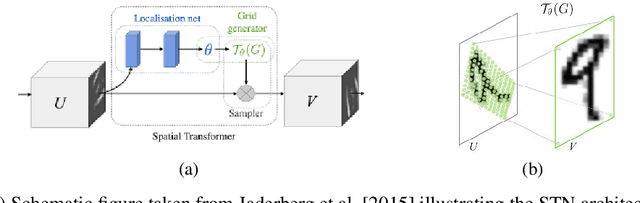

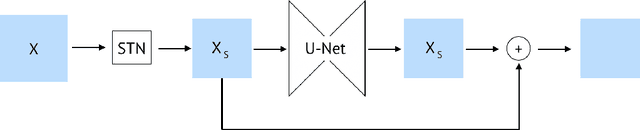
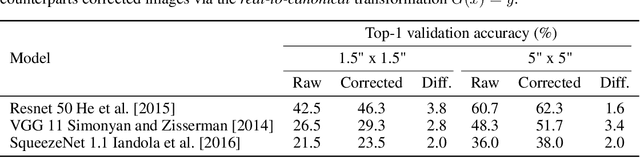
Employing machine learning models in the real world requires collecting large amounts of data, which is both time consuming and costly to collect. A common approach to circumvent this is to leverage existing, similar data-sets with large amounts of labelled data. However, models trained on these canonical distributions do not readily transfer to real-world ones. Domain adaptation and transfer learning are often used to breach this "reality gap", though both require a substantial amount of real-world data. In this paper we discuss a more general approach: we propose learning a general transformation to bring arbitrary images towards a canonical distribution where we can naively apply the trained machine learning models. This transformation is trained in an unsupervised regime, leveraging data augmentation to generate off-canonical examples of images and training a Deep Learning model to recover their original counterpart. We quantify the performance of this transformation using pre-trained ImageNet classifiers, demonstrating that this procedure can recover half of the loss in performance on the distorted data-set. We then validate the effectiveness of this approach on a series of pre-trained ImageNet models on a real world data set collected by printing and photographing images in different lighting conditions.
Reducing audio membership inference attack accuracy to chance: 4 defenses
Oct 31, 2019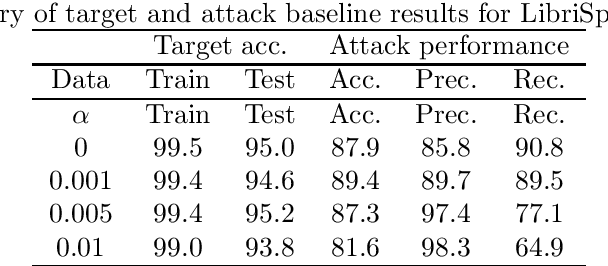
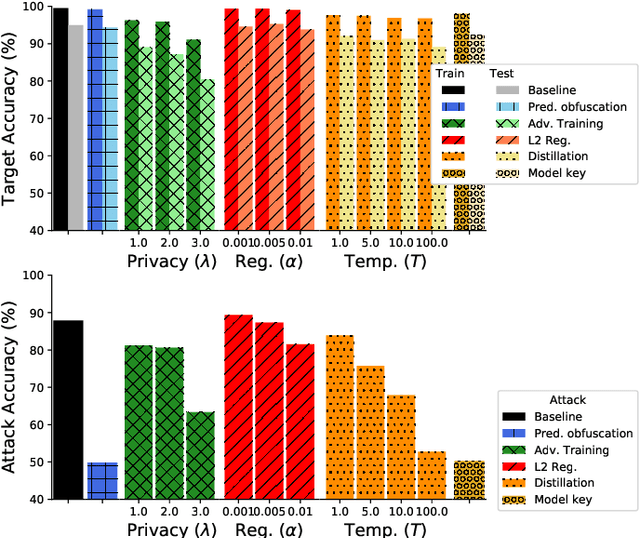
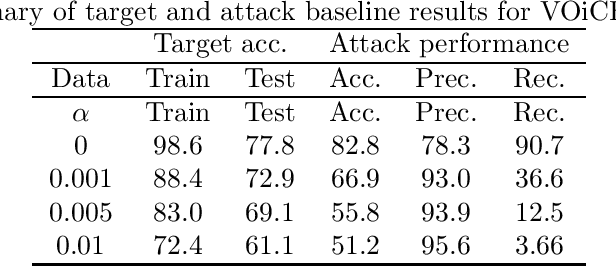
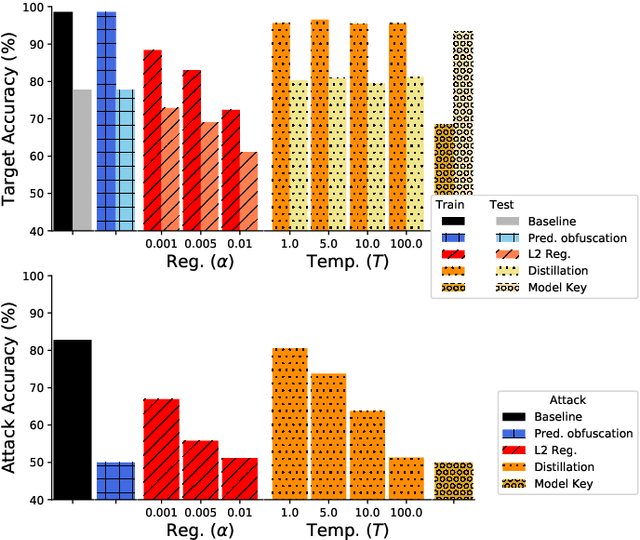
It is critical to understand the privacy and robustness vulnerabilities of machine learning models, as their implementation expands in scope. In membership inference attacks, adversaries can determine whether a particular set of data was used in training, putting the privacy of the data at risk. Existing work has mostly focused on image related tasks; we generalize this type of attack to speaker identification on audio samples. We demonstrate attack precision of 85.9\% and recall of 90.8\% for LibriSpeech, and 78.3\% precision and 90.7\% recall for VOiCES (Voices Obscured in Complex Environmental Settings). We find that implementing defenses such as prediction obfuscation, defensive distillation or adversarial training, can reduce attack accuracy to chance.
Robust or Private? Adversarial Training Makes Models More Vulnerable to Privacy Attacks
Jun 15, 2019
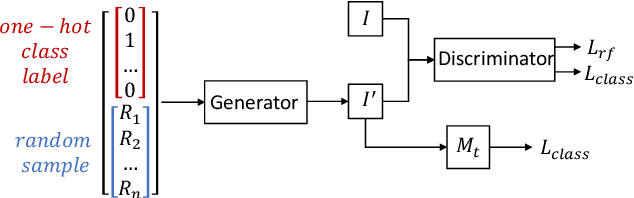

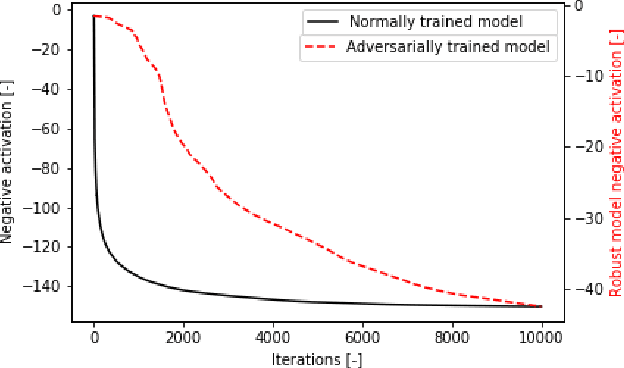
Adversarial training was introduced as a way to improve the robustness of deep learning models to adversarial attacks. This training method improves robustness against adversarial attacks, but increases the models vulnerability to privacy attacks. In this work we demonstrate how model inversion attacks, extracting training data directly from the model, previously thought to be intractable become feasible when attacking a robustly trained model. The input space for a traditionally trained model is dominated by adversarial examples - data points that strongly activate a certain class but lack semantic meaning - this makes it difficult to successfully conduct model inversion attacks. We demonstrate this effect using the CIFAR-10 dataset under three different model inversion attacks, a vanilla gradient descent method, gradient based method at different scales, and a generative adversarial network base attacks.