 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing audio membership inference attack accuracy to chance: 4 defenses
Paper and Code
Oct 31, 2019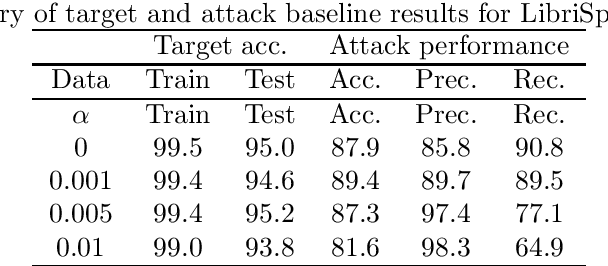
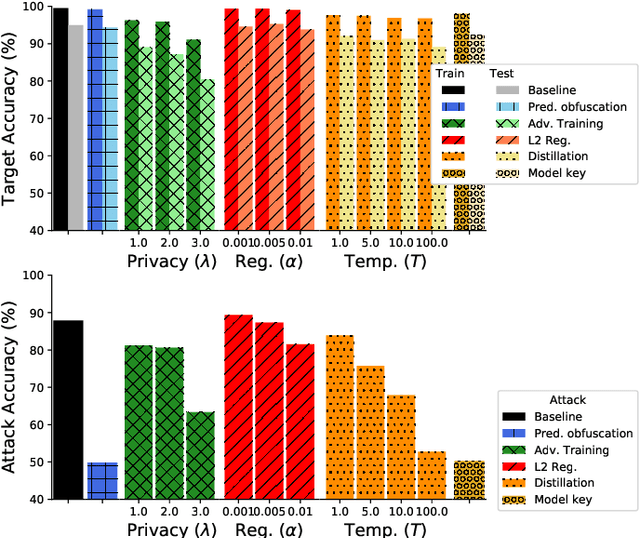
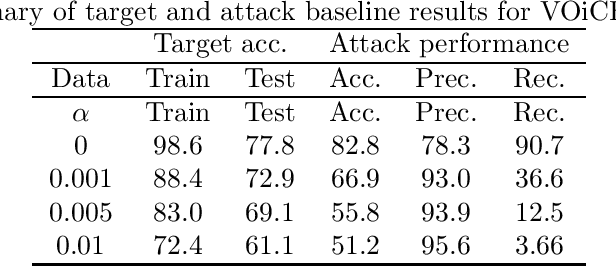
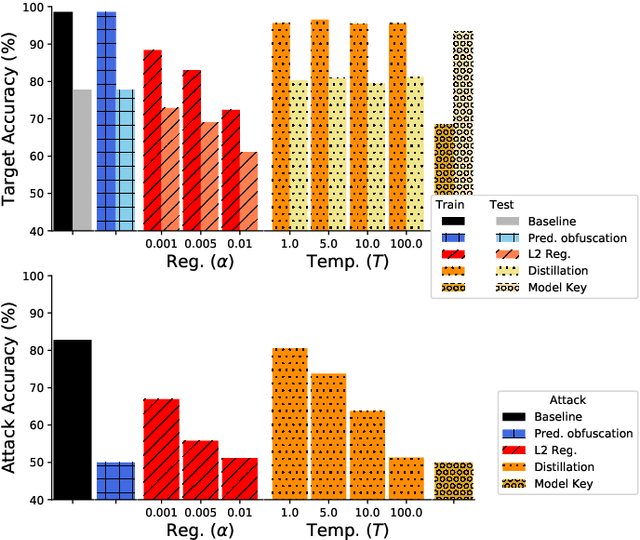
It is critical to understand the privacy and robustness vulnerabilities of machine learning models, as their implementation expands in scope. In membership inference attacks, adversaries can determine whether a particular set of data was used in training, putting the privacy of the data at risk. Existing work has mostly focused on image related tasks; we generalize this type of attack to speaker identification on audio samples. We demonstrate attack precision of 85.9\% and recall of 90.8\% for LibriSpeech, and 78.3\% precision and 90.7\% recall for VOiCES (Voices Obscured in Complex Environmental Settings). We find that implementing defenses such as prediction obfuscation, defensive distillation or adversarial training, can reduce attack accuracy to chance.