 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024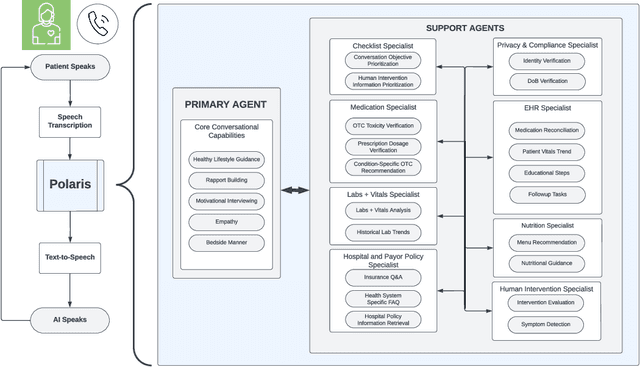
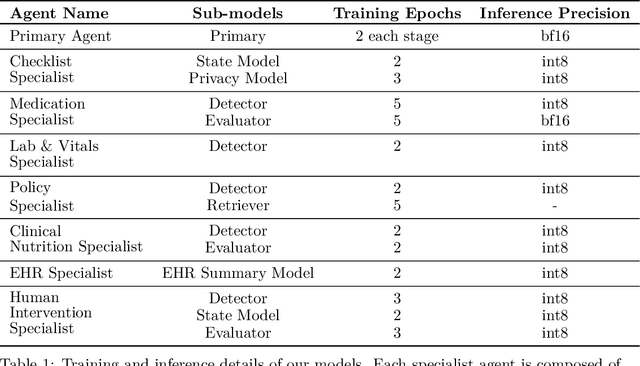
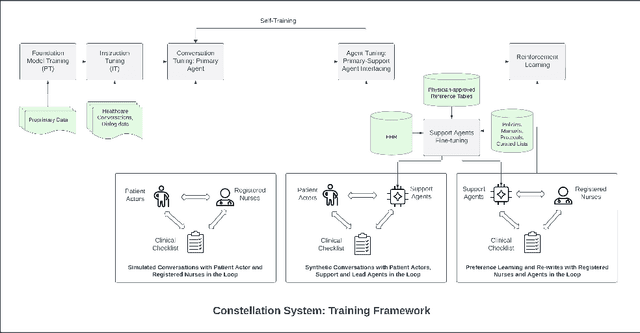
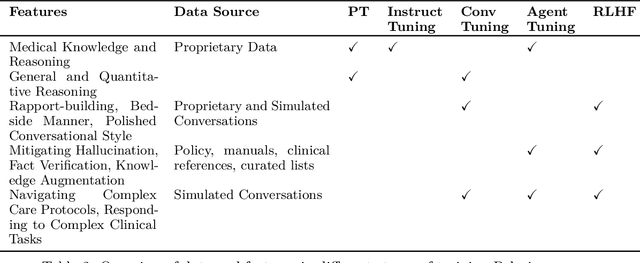
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Reducing audio membership inference attack accuracy to chance: 4 defenses
Oct 31, 2019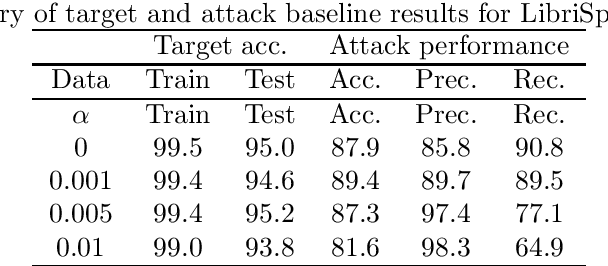
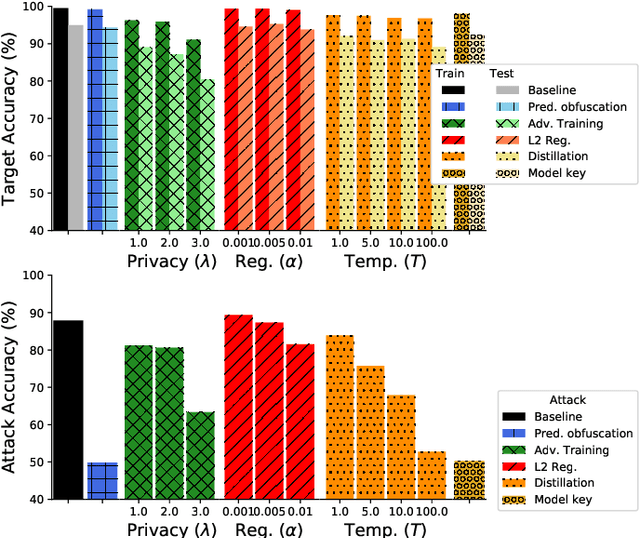
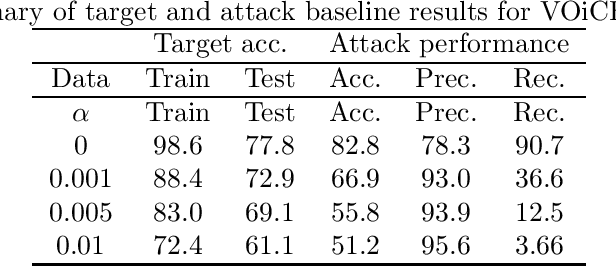
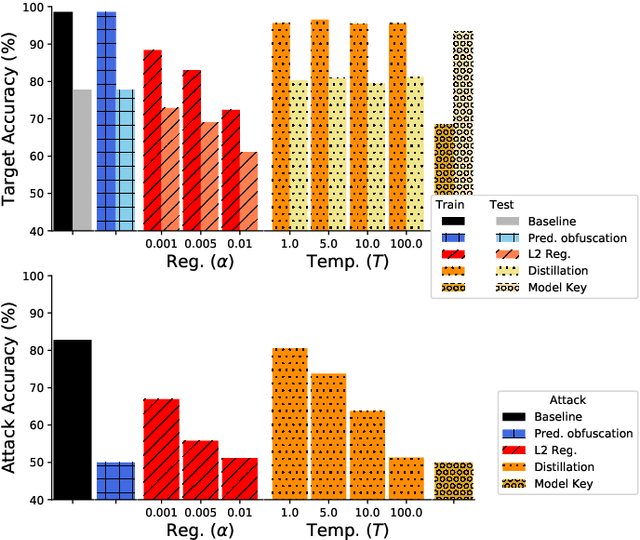
It is critical to understand the privacy and robustness vulnerabilities of machine learning models, as their implementation expands in scope. In membership inference attacks, adversaries can determine whether a particular set of data was used in training, putting the privacy of the data at risk. Existing work has mostly focused on image related tasks; we generalize this type of attack to speaker identification on audio samples. We demonstrate attack precision of 85.9\% and recall of 90.8\% for LibriSpeech, and 78.3\% precision and 90.7\% recall for VOiCES (Voices Obscured in Complex Environmental Settings). We find that implementing defenses such as prediction obfuscation, defensive distillation or adversarial training, can reduce attack accuracy to chance.
Robust or Private? Adversarial Training Makes Models More Vulnerable to Privacy Attacks
Jun 15, 2019
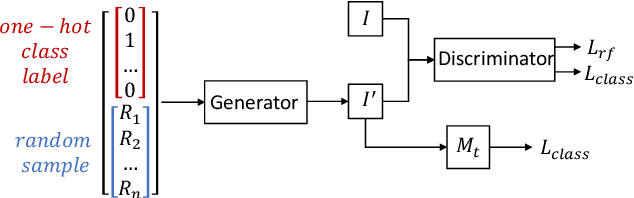

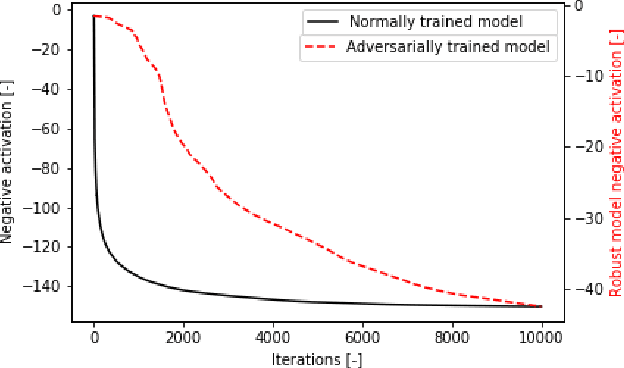
Adversarial training was introduced as a way to improve the robustness of deep learning models to adversarial attacks. This training method improves robustness against adversarial attacks, but increases the models vulnerability to privacy attacks. In this work we demonstrate how model inversion attacks, extracting training data directly from the model, previously thought to be intractable become feasible when attacking a robustly trained model. The input space for a traditionally trained model is dominated by adversarial examples - data points that strongly activate a certain class but lack semantic meaning - this makes it difficult to successfully conduct model inversion attacks. We demonstrate this effect using the CIFAR-10 dataset under three different model inversion attacks, a vanilla gradient descent method, gradient based method at different scales, and a generative adversarial network base attacks.
Deep Speech Denoising with Vector Space Projections
Apr 27, 2018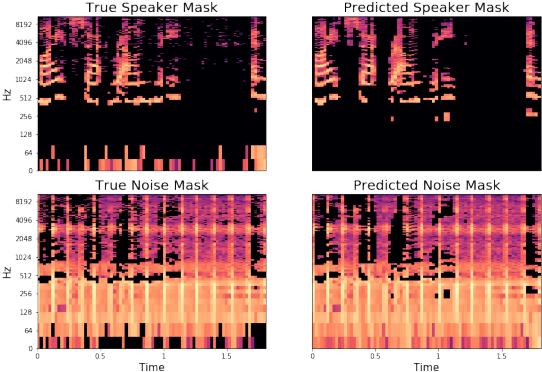
We propose an algorithm to denoise speakers from a single microphone in the presence of non-stationary and dynamic noise. Our approach is inspired by the recent success of neural network models separating speakers from other speakers and singers from instrumental accompaniment. Unlike prior art, we leverage embedding spaces produced with source-contrastive estimation, a technique derived from negative sampling techniques in natural language processing, while simultaneously obtaining a continuous inference mask. Our embedding space directly optimizes for the discrimination of speaker and noise by jointly modeling their characteristics. This space is generalizable in that it is not speaker or noise specific and is capable of denoising speech even if the model has not seen the speaker in the training set. Parameters are trained with dual objectives: one that promotes a selective bandpass filter that eliminates noise at time-frequency positions that exceed signal power, and another that proportionally splits time-frequency content between signal and noise. We compare to state of the art algorithms as well as traditional sparse non-negative matrix factorization solutions. The resulting algorithm avoids severe computational burden by providing a more intuitive and easily optimized approach, while achieving competitive accuracy.