 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelop AI Agents for System Engineering in Factorio
Feb 03, 2025



Continuing advances in frontier model research are paving the way for widespread deployment of AI agents. Meanwhile, global interest in building large, complex systems in software, manufacturing, energy and logistics has never been greater. Although AI driven system engineering holds tremendous promise, the static benchmarks dominating agent evaluations today fail to capture the crucial skills required for implementing dynamic systems, such as managing uncertain trade-offs and ensuring proactive adaptability. This position paper advocates for training and evaluating AI agents' system engineering abilities through automation-oriented sandbox games-particularly Factorio. By directing research efforts in this direction, we can equip AI agents with the specialized reasoning and long-horizon planning necessary to design, maintain, and optimize tomorrow's most demanding engineering projects.
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024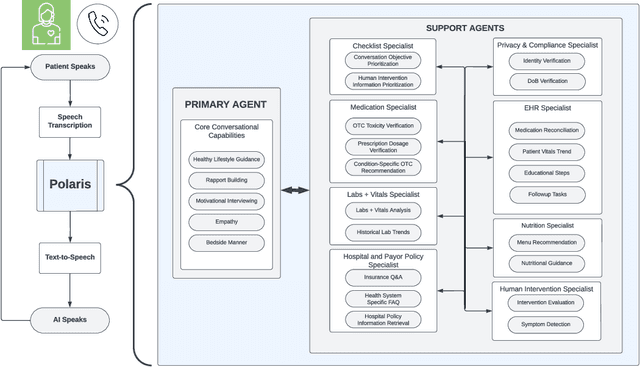
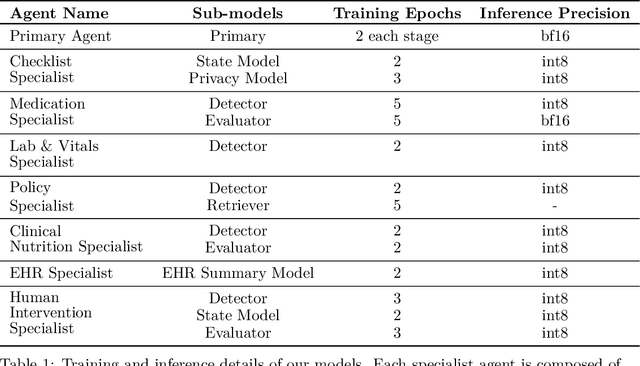
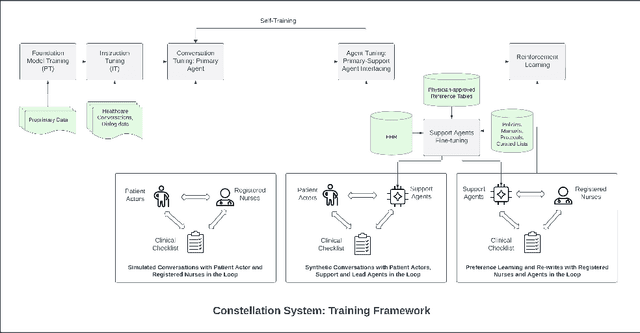
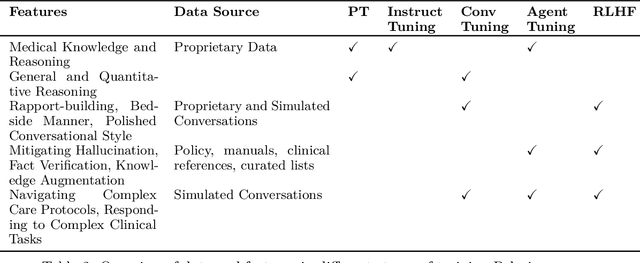
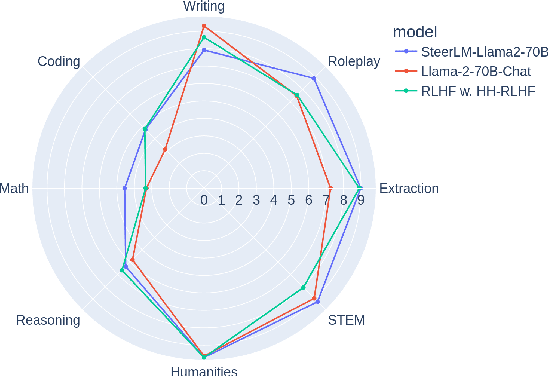
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM
Nov 16, 2023

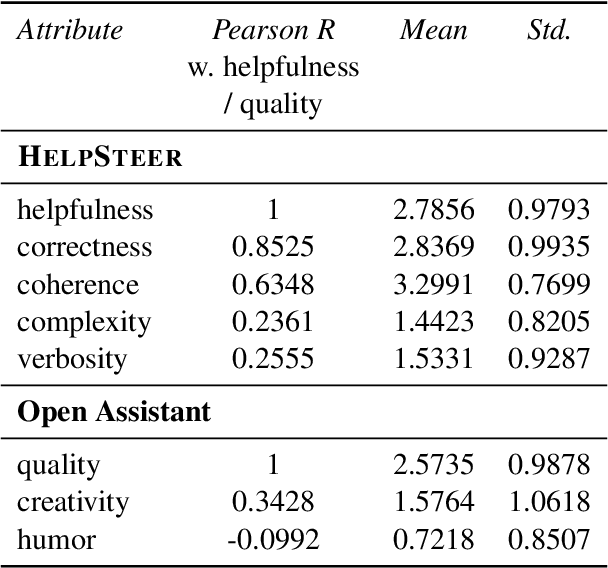
Existing open-source helpfulness preference datasets do not specify what makes some responses more helpful and others less so. Models trained on these datasets can incidentally learn to model dataset artifacts (e.g. preferring longer but unhelpful responses only due to their length). To alleviate this problem, we collect HelpSteer, a multi-attribute helpfulness dataset annotated for the various aspects that make responses helpful. Specifically, our 37k-sample dataset has annotations for correctness, coherence, complexity, and verbosity in addition to overall helpfulness of responses. Training Llama 2 70B using the HelpSteer dataset with SteerLM technique produces a model that scores 7.54 on MT Bench, which is currently the highest score for open models that do not require training data from more powerful models (e.g. GPT4). We release this dataset with CC-BY-4.0 license at https://huggingface.co/datasets/nvidia/HelpSteer
PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
May 14, 2022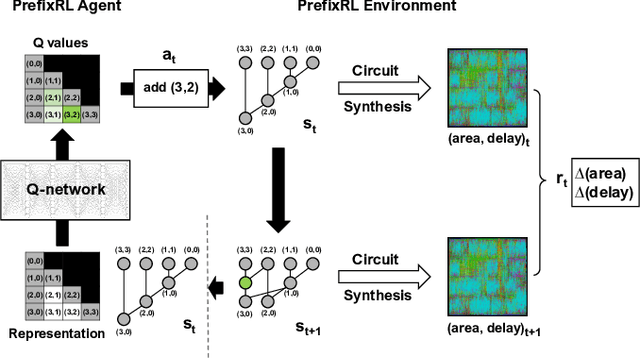
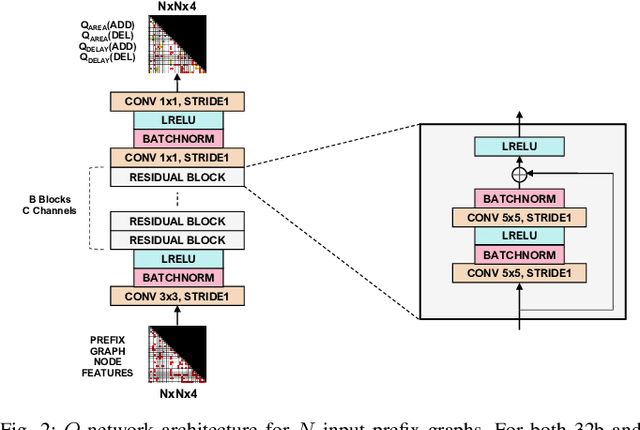
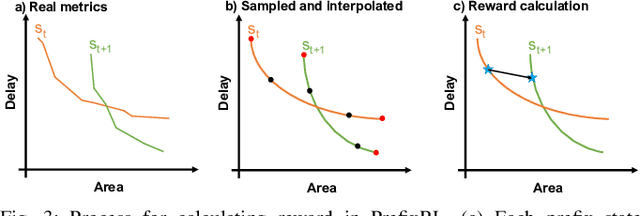
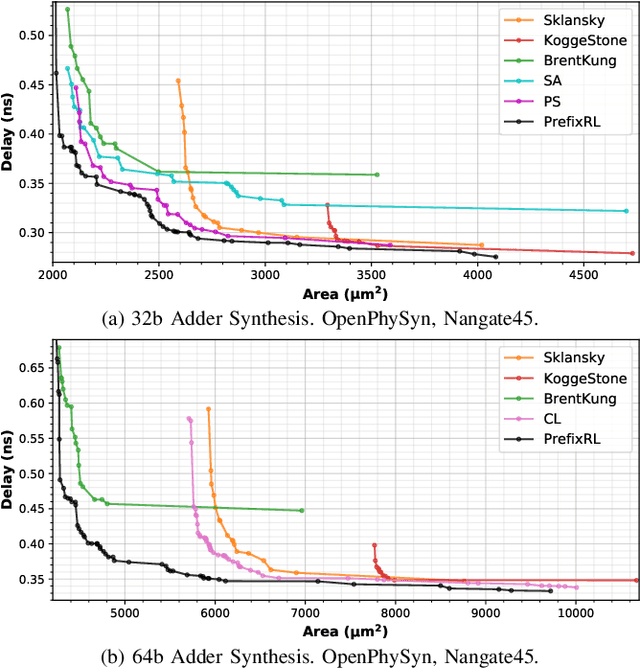
In this work, we present a reinforcement learning (RL) based approach to designing parallel prefix circuits such as adders or priority encoders that are fundamental to high-performance digital design. Unlike prior methods, our approach designs solutions tabula rasa purely through learning with synthesis in the loop. We design a grid-based state-action representation and an RL environment for constructing legal prefix circuits. Deep Convolutional RL agents trained on this environment produce prefix adder circuits that Pareto-dominate existing baselines with up to 16.0% and 30.2% lower area for the same delay in the 32b and 64b settings respectively. We observe that agents trained with open-source synthesis tools and cell library can design adder circuits that achieve lower area and delay than commercial tool adders in an industrial cell library.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
End-to-End Training of Neural Retrievers for Open-Domain Question Answering
Jan 02, 2021

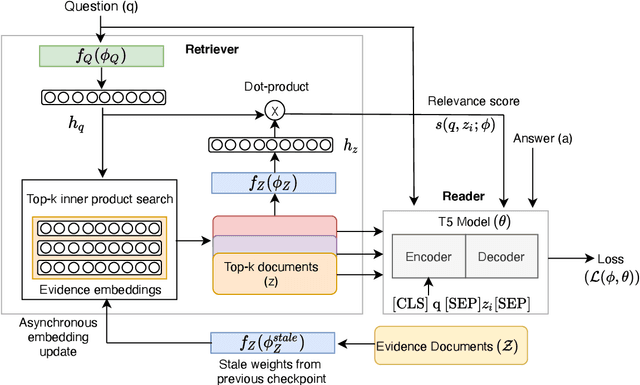
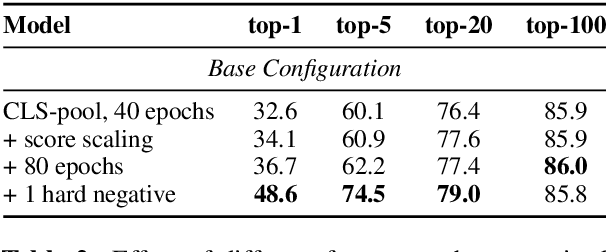
Recent work on training neural retrievers for open-domain question answering (OpenQA) has employed both supervised and unsupervised approaches. However, it remains unclear how unsupervised and supervised methods can be used most effectively for neural retrievers. In this work, we systematically study retriever pre-training. We first propose an approach of unsupervised pre-training with the Inverse Cloze Task and masked salient spans, followed by supervised finetuning using question-context pairs. This approach leads to absolute gains of 2+ points over the previous best result in the top-20 retrieval accuracy on Natural Questions and TriviaQA datasets. We also explore two approaches for end-to-end supervised training of the reader and retriever components in OpenQA models. In the first approach, the reader considers each retrieved document separately while in the second approach, the reader considers all the retrieved documents together. Our experiments demonstrate the effectiveness of these approaches as we obtain new state-of-the-art results. On the Natural Questions dataset, we obtain a top-20 retrieval accuracy of 84, an improvement of 5 points over the recent DPR model. In addition, we achieve good results on answer extraction, outperforming recent models like REALM and RAG by 3+ points. We further scale up end-to-end training to large models and show consistent gains in performance over smaller models.
Synthetic Datasets for Neural Program Synthesis
Dec 27, 2019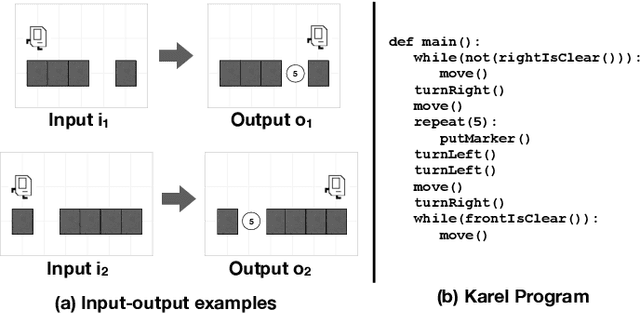



The goal of program synthesis is to automatically generate programs in a particular language from corresponding specifications, e.g. input-output behavior. Many current approaches achieve impressive results after training on randomly generated I/O examples in limited domain-specific languages (DSLs), as with string transformations in RobustFill. However, we empirically discover that applying test input generation techniques for languages with control flow and rich input space causes deep networks to generalize poorly to certain data distributions; to correct this, we propose a new methodology for controlling and evaluating the bias of synthetic data distributions over both programs and specifications. We demonstrate, using the Karel DSL and a small Calculator DSL, that training deep networks on these distributions leads to improved cross-distribution generalization performance.
Adversarial Policies: Attacking Deep Reinforcement Learning
May 25, 2019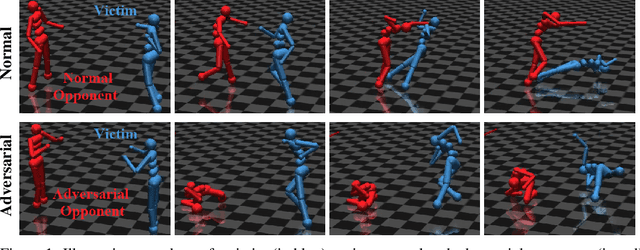

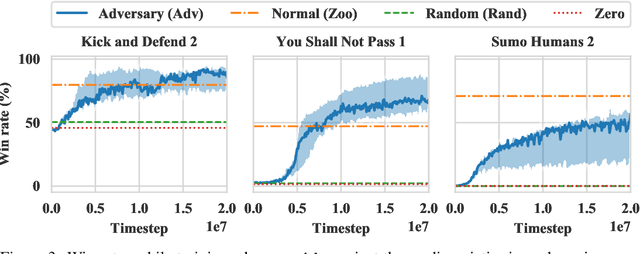
Deep reinforcement learning (RL) policies are known to be vulnerable to adversarial perturbations to their observations, similar to adversarial examples for classifiers. However, an attacker is not usually able to directly modify another agent's observations. This might lead one to wonder: is it possible to attack an RL agent simply by choosing an adversarial policy acting in a multi-agent environment so as to create natural observations that are adversarial? We demonstrate the existence of adversarial policies in zero-sum games between simulated humanoid robots with proprioceptive observations, against state-of-the-art victims trained via self-play to be robust to opponents. The adversarial policies reliably win against the victims but generate seemingly random and uncoordinated behavior. We find that these policies are more successful in high-dimensional environments, and induce substantially different activations in the victim policy network than when the victim plays against a normal opponent. Videos are available at http://adversarialpolicies.github.io.
Practical Text Classification With Large Pre-Trained Language Models
Dec 04, 2018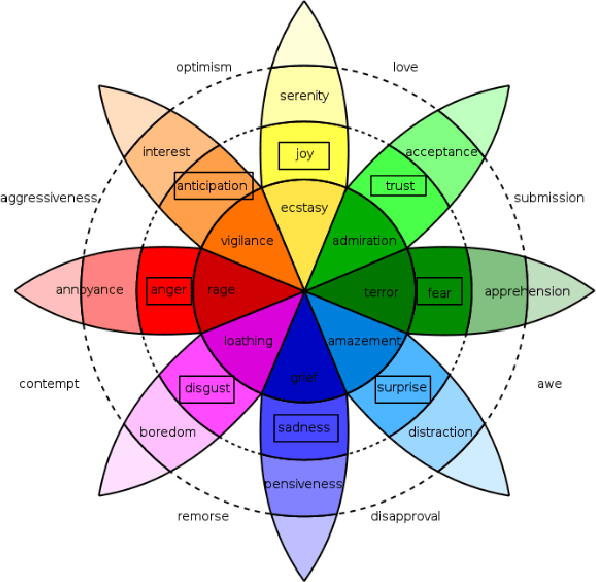


Multi-emotion sentiment classification is a natural language processing (NLP) problem with valuable use cases on real-world data. We demonstrate that large-scale unsupervised language modeling combined with finetuning offers a practical solution to this task on difficult datasets, including those with label class imbalance and domain-specific context. By training an attention-based Transformer network (Vaswani et al. 2017) on 40GB of text (Amazon reviews) (McAuley et al. 2015) and fine-tuning on the training set, our model achieves a 0.69 F1 score on the SemEval Task 1:E-c multi-dimensional emotion classification problem (Mohammad et al. 2018), based on the Plutchik wheel of emotions (Plutchik 1979). These results are competitive with state of the art models, including strong F1 scores on difficult (emotion) categories such as Fear (0.73), Disgust (0.77) and Anger (0.78), as well as competitive results on rare categories such as Anticipation (0.42) and Surprise (0.37). Furthermore, we demonstrate our application on a real world text classification task. We create a narrowly collected text dataset of real tweets on several topics, and show that our finetuned model outperforms general purpose commercially available APIs for sentiment and multidimensional emotion classification on this dataset by a significant margin. We also perform a variety of additional studies, investigating properties of deep learning architectures, datasets and algorithms for achieving practical multidimensional sentiment classification. Overall, we find that unsupervised language modeling and finetuning is a simple framework for achieving high quality results on real-world sentiment classification.
Recent Advances in Neural Program Synthesis
Feb 07, 2018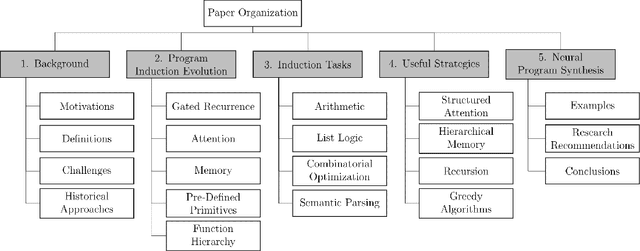
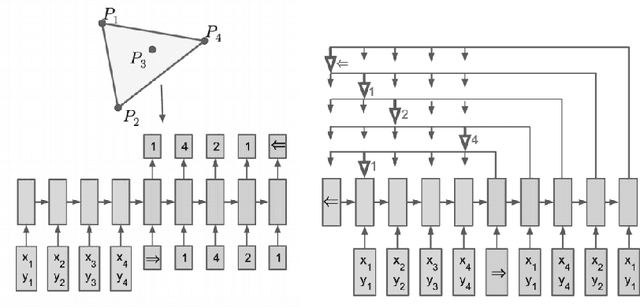
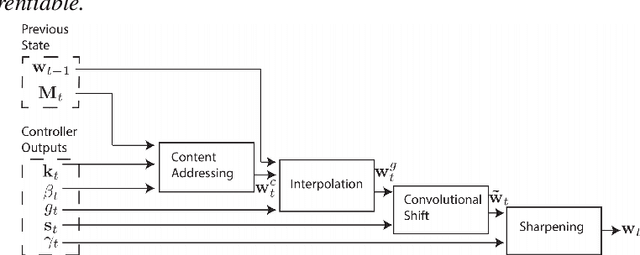
In recent years, deep learning has made tremendous progress in a number of fields that were previously out of reach for artificial intelligence. The successes in these problems has led researchers to consider the possibilities for intelligent systems to tackle a problem that humans have only recently themselves considered: program synthesis. This challenge is unlike others such as object recognition and speech translation, since its abstract nature and demand for rigor make it difficult even for human minds to attempt. While it is still far from being solved or even competitive with most existing methods, neural program synthesis is a rapidly growing discipline which holds great promise if completely realized. In this paper, we start with exploring the problem statement and challenges of program synthesis. Then, we examine the fascinating evolution of program induction models, along with how they have succeeded, failed and been reimagined since. Finally, we conclude with a contrastive look at program synthesis and future research recommendations for the field.