 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of Neural Retrievers for Open-Domain Question Answering
Paper and Code


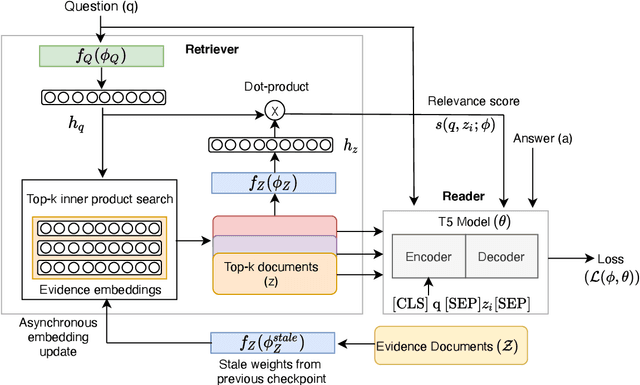
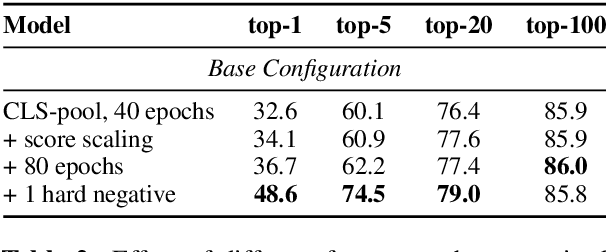
Recent work on training neural retrievers for open-domain question answering (OpenQA) has employed both supervised and unsupervised approaches. However, it remains unclear how unsupervised and supervised methods can be used most effectively for neural retrievers. In this work, we systematically study retriever pre-training. We first propose an approach of unsupervised pre-training with the Inverse Cloze Task and masked salient spans, followed by supervised finetuning using question-context pairs. This approach leads to absolute gains of 2+ points over the previous best result in the top-20 retrieval accuracy on Natural Questions and TriviaQA datasets. We also explore two approaches for end-to-end supervised training of the reader and retriever components in OpenQA models. In the first approach, the reader considers each retrieved document separately while in the second approach, the reader considers all the retrieved documents together. Our experiments demonstrate the effectiveness of these approaches as we obtain new state-of-the-art results. On the Natural Questions dataset, we obtain a top-20 retrieval accuracy of 84, an improvement of 5 points over the recent DPR model. In addition, we achieve good results on answer extraction, outperforming recent models like REALM and RAG by 3+ points. We further scale up end-to-end training to large models and show consistent gains in performance over smaller models.