 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Knowledge at Scale Improves Reasoning
Apr 01, 2026Test-time scaling has emerged as an effective way to improve language models on challenging reasoning tasks. However, most existing methods treat each problem in isolation and do not systematically reuse knowledge from prior reasoning trajectories. In particular, they underutilize procedural knowledge: how to reframe a problem, choose an approach, and verify or backtrack when needed. We introduce Reasoning Memory, a retrieval-augmented generation (RAG) framework for reasoning models that explicitly retrieves and reuses procedural knowledge at scale. Starting from existing corpora of step-by-step reasoning trajectories, we decompose each trajectory into self-contained subquestion-subroutine pairs, yielding a datastore of 32 million compact procedural knowledge entries. At inference time, a lightweight in-thought prompt lets the model verbalize the core subquestion, retrieve relevant subroutines within its reasoning trace, and reason under diverse retrieved subroutines as implicit procedural priors. Across six math, science, and coding benchmarks, Reasoning Memory consistently outperforms RAG with document, trajectory, and template knowledge, as well as a compute-matched test-time scaling baseline. With a higher inference budget, it improves over no retrieval by up to 19.2% and over the strongest compute-matched baseline by 7.9% across task types. Ablation studies show that these gains come from two key factors: the broad procedural coverage of the source trajectories and our decomposition and retrieval design, which together enable effective extraction and reuse of procedural knowledge.
Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval
Aug 03, 2024



Recent advances in large language models (LLMs) have enabled autonomous agents with complex reasoning and task-fulfillment capabilities using a wide range of tools. However, effectively identifying the most relevant tools for a given task becomes a key bottleneck as the toolset size grows, hindering reliable tool utilization. To address this, we introduce Re-Invoke, an unsupervised tool retrieval method designed to scale effectively to large toolsets without training. Specifically, we first generate a diverse set of synthetic queries that comprehensively cover different aspects of the query space associated with each tool document during the tool indexing phase. Second, we leverage LLM's query understanding capabilities to extract key tool-related context and underlying intents from user queries during the inference phase. Finally, we employ a novel multi-view similarity ranking strategy based on intents to pinpoint the most relevant tools for each query. Our evaluation demonstrates that Re-Invoke significantly outperforms state-of-the-art alternatives in both single-tool and multi-tool scenarios, all within a fully unsupervised setting. Notably, on the ToolE datasets, we achieve a 20% relative improvement in nDCG@5 for single-tool retrieval and a 39% improvement for multi-tool retrieval.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


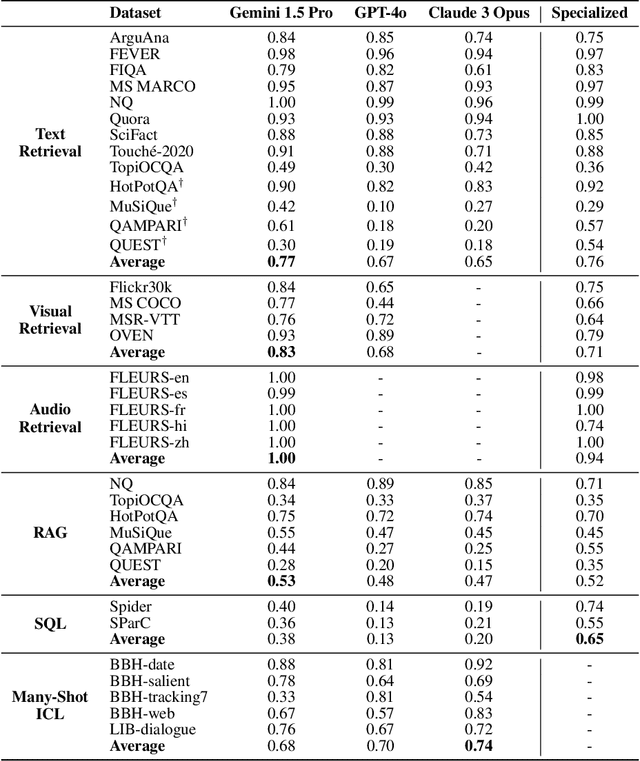
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Questions Are All You Need to Train a Dense Passage Retriever
Jun 21, 2022
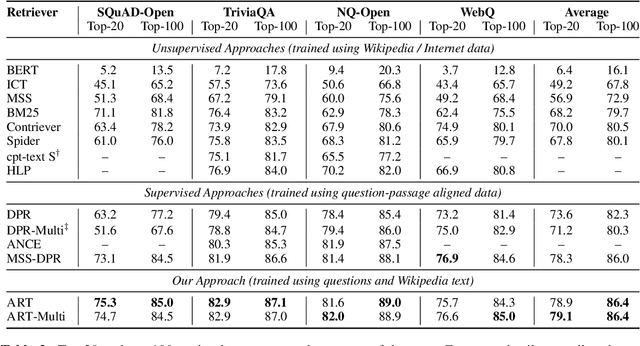
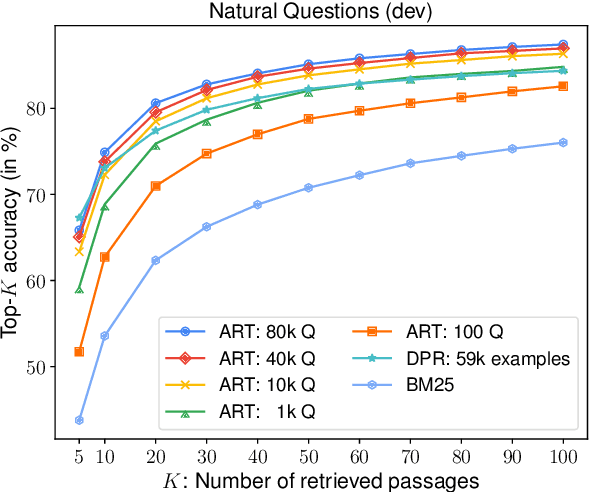
We introduce ART, a new corpus-level autoencoding approach for training dense retrieval models that does not require any labeled training data. Dense retrieval is a central challenge for open-domain tasks, such as Open QA, where state-of-the-art methods typically require large supervised datasets with custom hard-negative mining and denoising of positive examples. ART, in contrast, only requires access to unpaired inputs and outputs (e.g. questions and potential answer documents). It uses a new document-retrieval autoencoding scheme, where (1) an input question is used to retrieve a set of evidence documents, and (2) the documents are then used to compute the probability of reconstructing the original question. Training for retrieval based on question reconstruction enables effective unsupervised learning of both document and question encoders, which can be later incorporated into complete Open QA systems without any further finetuning. Extensive experiments demonstrate that ART obtains state-of-the-art results on multiple QA retrieval benchmarks with only generic initialization from a pre-trained language model, removing the need for labeled data and task-specific losses.
Improving Passage Retrieval with Zero-Shot Question Generation
Apr 15, 2022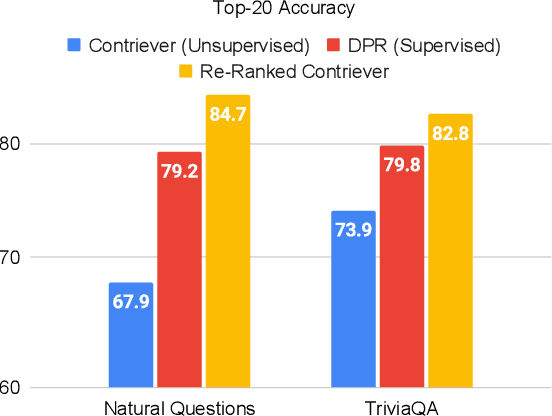
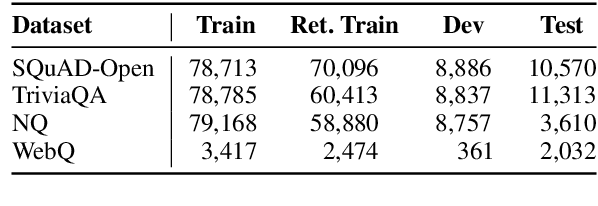
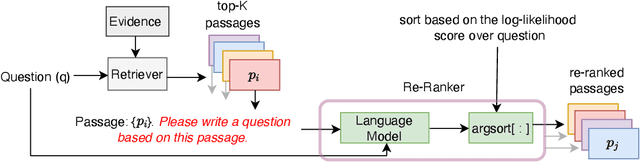
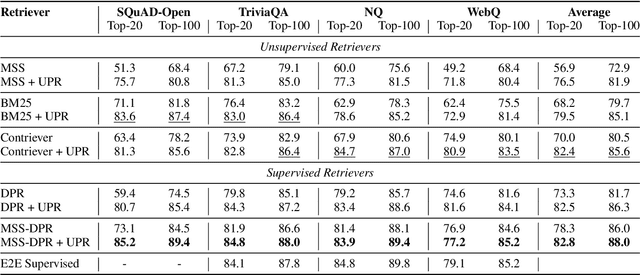
We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot question generation model, which uses a pre-trained language model to compute the probability of the input question conditioned on a retrieved passage. This approach can be applied on top of any retrieval method (e.g. neural or keyword-based), does not require any domain- or task-specific training (and therefore is expected to generalize better to data distribution shifts), and provides rich cross-attention between query and passage (i.e. it must explain every token in the question). When evaluated on a number of open-domain retrieval datasets, our re-ranker improves strong unsupervised retrieval models by 6%-18% absolute and strong supervised models by up to 12% in terms of top-20 passage retrieval accuracy. We also obtain new state-of-the-art results on full open-domain question answering by simply adding the new re-ranker to existing models with no further changes.
End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
Jun 09, 2021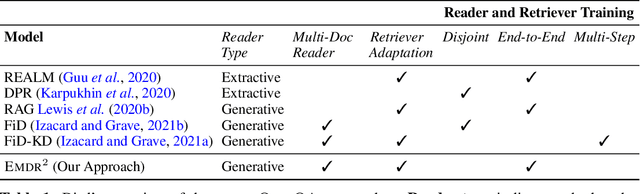
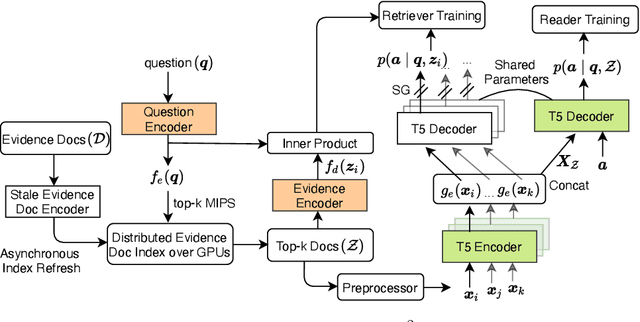
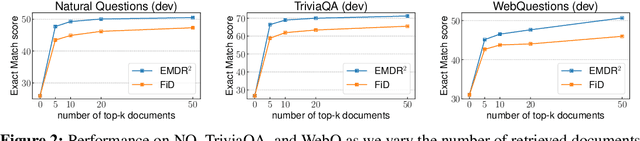
We present an end-to-end differentiable training method for retrieval-augmented open-domain question answering systems that combine information from multiple retrieved documents when generating answers. We model retrieval decisions as latent variables over sets of relevant documents. Since marginalizing over sets of retrieved documents is computationally hard, we approximate this using an expectation-maximization algorithm. We iteratively estimate the value of our latent variable (the set of relevant documents for a given question) and then use this estimate to update the retriever and reader parameters. We hypothesize that such end-to-end training allows training signals to flow to the reader and then to the retriever better than staged-wise training. This results in a retriever that is able to select more relevant documents for a question and a reader that is trained on more accurate documents to generate an answer. Experiments on three benchmark datasets demonstrate that our proposed method outperforms all existing approaches of comparable size by 2-3% absolute exact match points, achieving new state-of-the-art results. Our results also demonstrate the feasibility of learning to retrieve to improve answer generation without explicit supervision of retrieval decisions.
End-to-End Training of Neural Retrievers for Open-Domain Question Answering
Jan 02, 2021

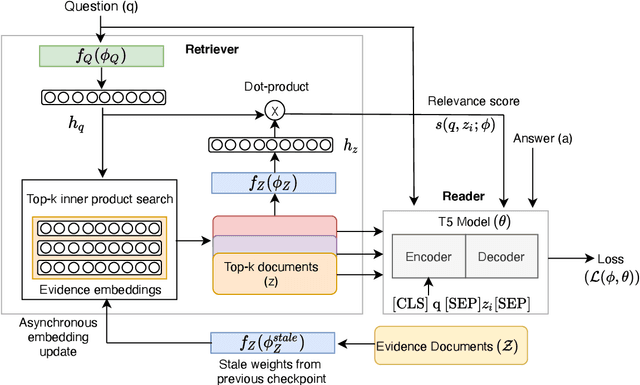
Recent work on training neural retrievers for open-domain question answering (OpenQA) has employed both supervised and unsupervised approaches. However, it remains unclear how unsupervised and supervised methods can be used most effectively for neural retrievers. In this work, we systematically study retriever pre-training. We first propose an approach of unsupervised pre-training with the Inverse Cloze Task and masked salient spans, followed by supervised finetuning using question-context pairs. This approach leads to absolute gains of 2+ points over the previous best result in the top-20 retrieval accuracy on Natural Questions and TriviaQA datasets. We also explore two approaches for end-to-end supervised training of the reader and retriever components in OpenQA models. In the first approach, the reader considers each retrieved document separately while in the second approach, the reader considers all the retrieved documents together. Our experiments demonstrate the effectiveness of these approaches as we obtain new state-of-the-art results. On the Natural Questions dataset, we obtain a top-20 retrieval accuracy of 84, an improvement of 5 points over the recent DPR model. In addition, we achieve good results on answer extraction, outperforming recent models like REALM and RAG by 3+ points. We further scale up end-to-end training to large models and show consistent gains in performance over smaller models.
Stronger Transformers for Neural Multi-Hop Question Generation
Oct 22, 2020
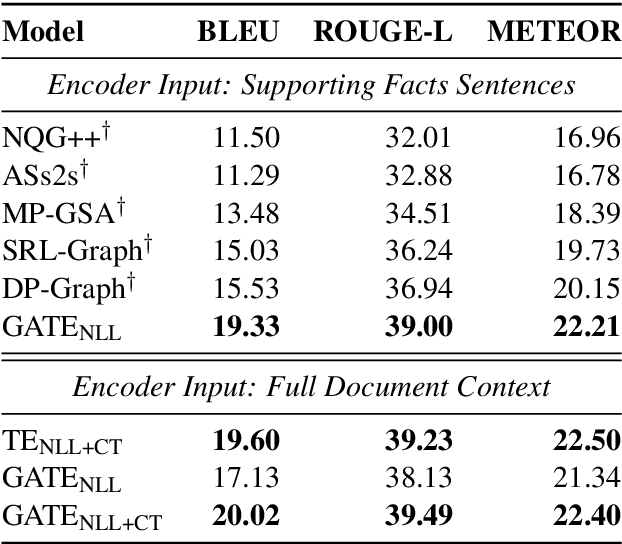

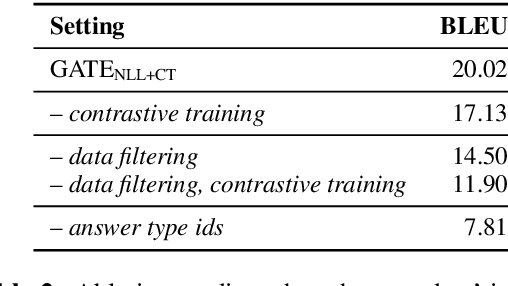
Prior work on automated question generation has almost exclusively focused on generating simple questions whose answers can be extracted from a single document. However, there is an increasing interest in developing systems that are capable of more complex multi-hop question generation, where answering the questions requires reasoning over multiple documents. In this work, we introduce a series of strong transformer models for multi-hop question generation, including a graph-augmented transformer that leverages relations between entities in the text. While prior work has emphasized the importance of graph-based models, we show that we can substantially outperform the state-of-the-art by 5 BLEU points using a standard transformer architecture. We further demonstrate that graph-based augmentations can provide complimentary improvements on top of this foundation. Interestingly, we find that several important factors--such as the inclusion of an auxiliary contrastive objective and data filtering could have larger impacts on performance. We hope that our stronger baselines and analysis provide a constructive foundation for future work in this area.
Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function
Sep 08, 2020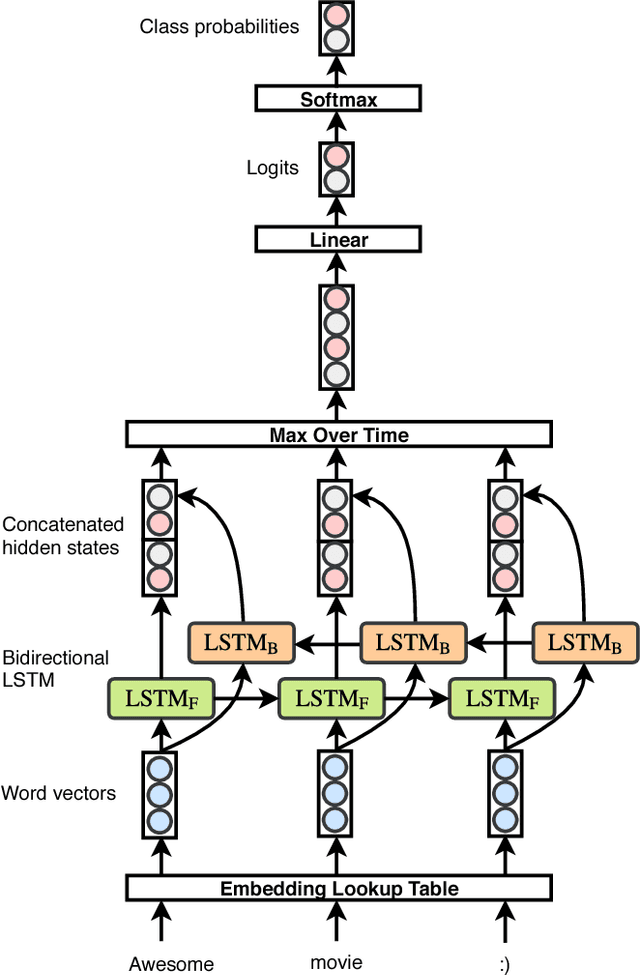
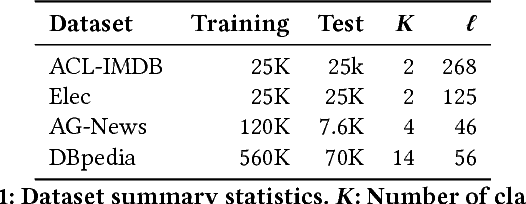
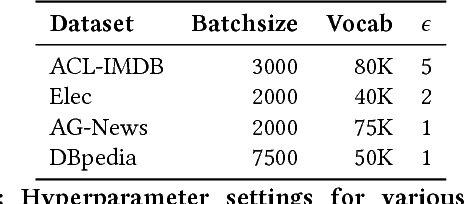
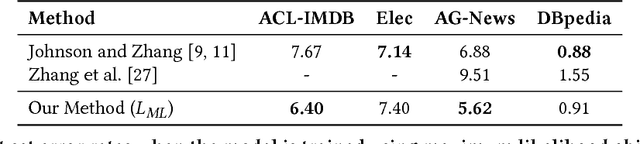
In this paper, we study bidirectional LSTM network for the task of text classification using both supervised and semi-supervised approaches. Several prior works have suggested that either complex pretraining schemes using unsupervised methods such as language modeling (Dai and Le 2015; Miyato, Dai, and Goodfellow 2016) or complicated models (Johnson and Zhang 2017) are necessary to achieve a high classification accuracy. However, we develop a training strategy that allows even a simple BiLSTM model, when trained with cross-entropy loss, to achieve competitive results compared with more complex approaches. Furthermore, in addition to cross-entropy loss, by using a combination of entropy minimization, adversarial, and virtual adversarial losses for both labeled and unlabeled data, we report state-of-the-art results for text classification task on several benchmark datasets. In particular, on the ACL-IMDB sentiment analysis and AG-News topic classification datasets, our method outperforms current approaches by a substantial margin. We also show the generality of the mixed objective function by improving the performance on relation extraction task.
Do Syntax Trees Help Pre-trained Transformers Extract Information?
Aug 20, 2020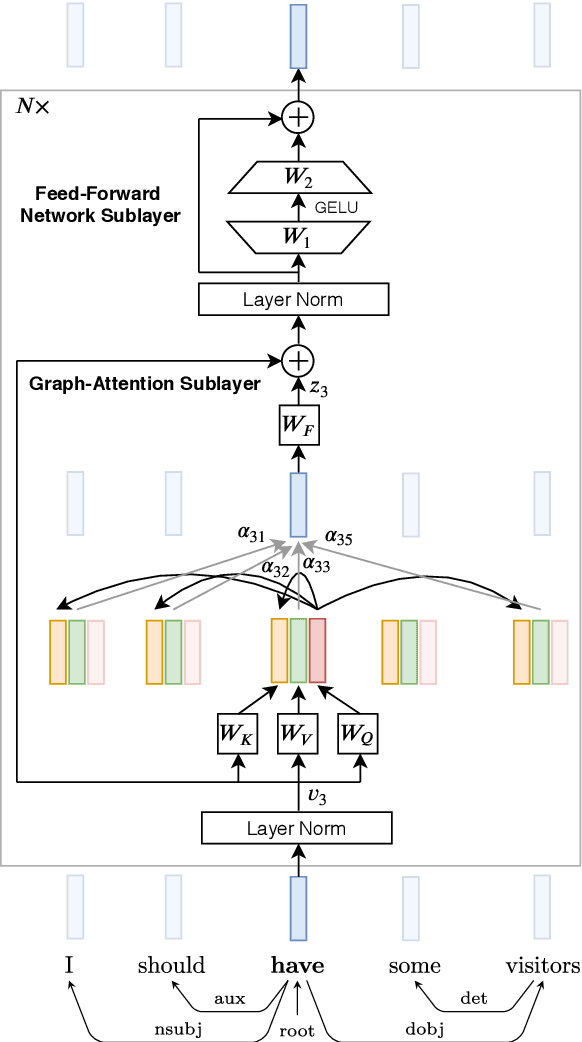
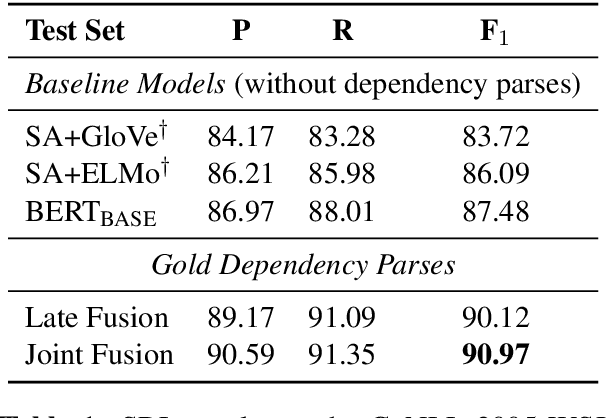
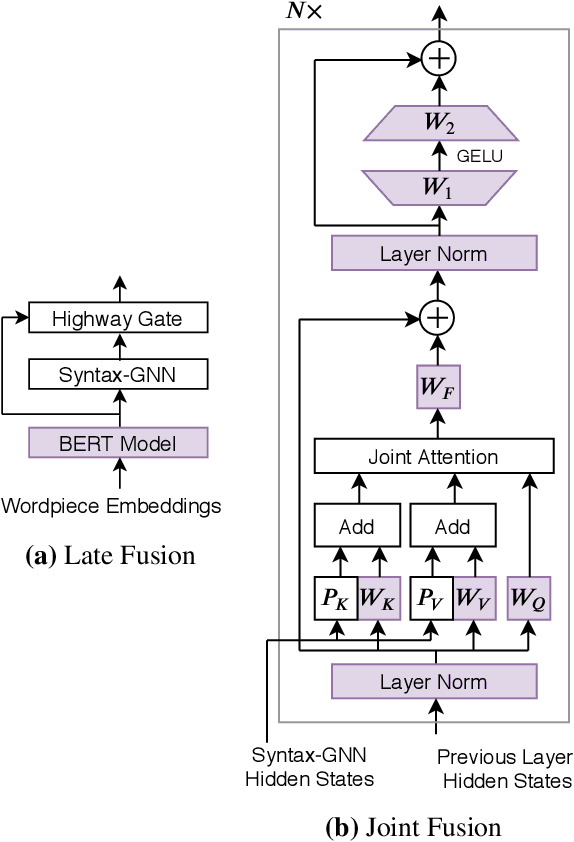
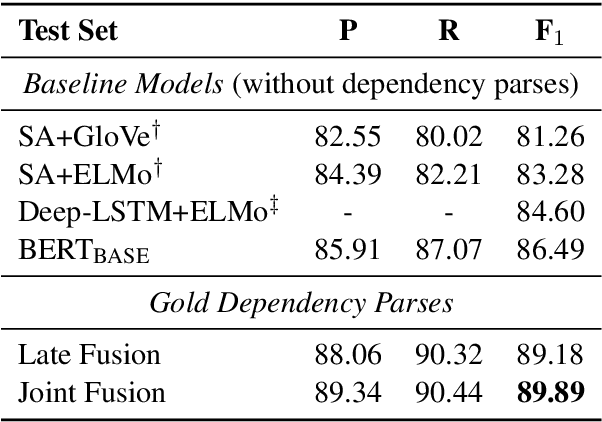
Much recent work suggests that incorporating syntax information from dependency trees can improve task-specific transformer models. However, the effect of incorporating dependency tree information into pre-trained transformer models (e.g., BERT) remains unclear, especially given recent studies highlighting how these models implicitly encode syntax. In this work, we systematically study the utility of incorporating dependency trees into pre-trained transformers on three representative information extraction tasks: semantic role labeling (SRL), named entity recognition, and relation extraction. We propose and investigate two distinct strategies for incorporating dependency structure: a late fusion approach, which applies a graph neural network on the output of a transformer, and a joint fusion approach, which infuses syntax structure into the transformer attention layers. These strategies are representative of prior work, but we introduce essential design decisions that are necessary for strong performance. Our empirical analysis demonstrates that these syntax-infused transformers obtain state-of-the-art results on SRL and relation extraction tasks. However, our analysis also reveals a critical shortcoming of these models: we find that their performance gains are highly contingent on the availability of human-annotated dependency parses, which raises important questions regarding the viability of syntax-augmented transformers in real-world applications.