 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function
Paper and Code
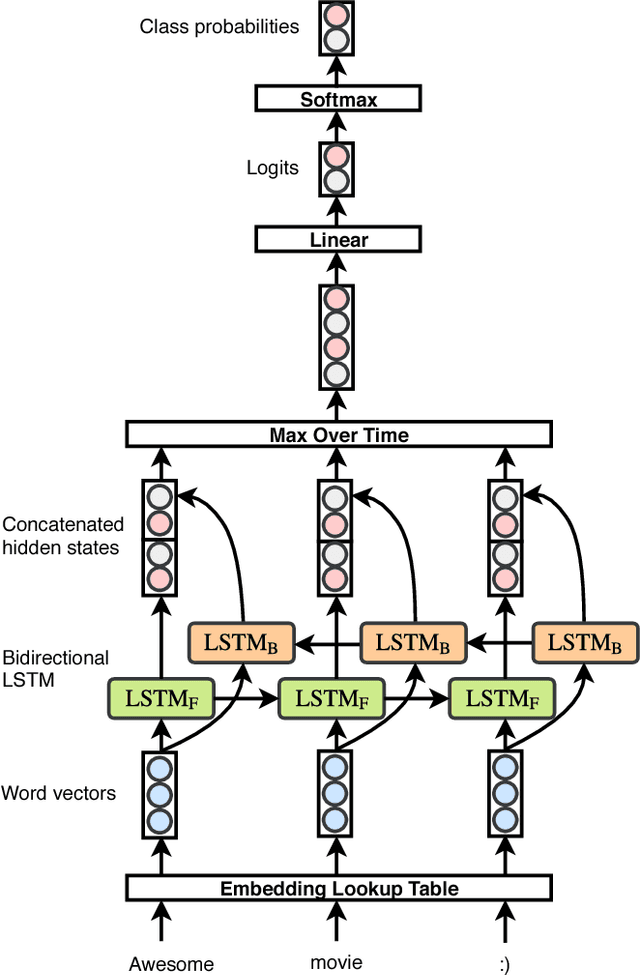
In this paper, we study bidirectional LSTM network for the task of text classification using both supervised and semi-supervised approaches. Several prior works have suggested that either complex pretraining schemes using unsupervised methods such as language modeling (Dai and Le 2015; Miyato, Dai, and Goodfellow 2016) or complicated models (Johnson and Zhang 2017) are necessary to achieve a high classification accuracy. However, we develop a training strategy that allows even a simple BiLSTM model, when trained with cross-entropy loss, to achieve competitive results compared with more complex approaches. Furthermore, in addition to cross-entropy loss, by using a combination of entropy minimization, adversarial, and virtual adversarial losses for both labeled and unlabeled data, we report state-of-the-art results for text classification task on several benchmark datasets. In particular, on the ACL-IMDB sentiment analysis and AG-News topic classification datasets, our method outperforms current approaches by a substantial margin. We also show the generality of the mixed objective function by improving the performance on relation extraction task.