 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
Jun 09, 2021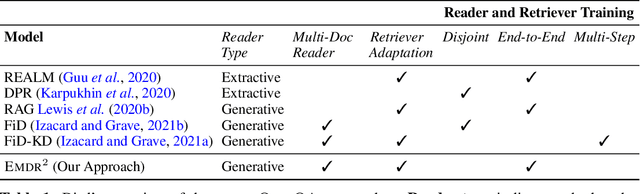
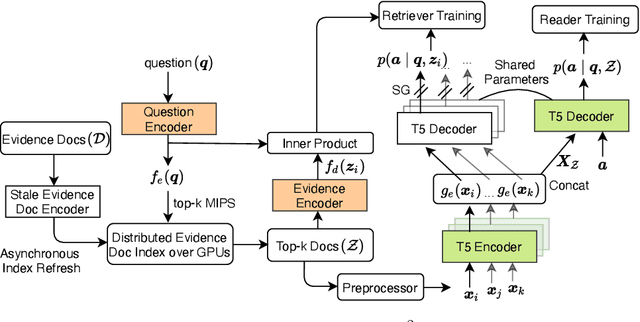
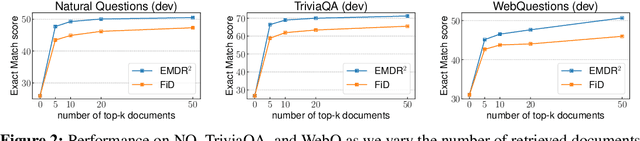
We present an end-to-end differentiable training method for retrieval-augmented open-domain question answering systems that combine information from multiple retrieved documents when generating answers. We model retrieval decisions as latent variables over sets of relevant documents. Since marginalizing over sets of retrieved documents is computationally hard, we approximate this using an expectation-maximization algorithm. We iteratively estimate the value of our latent variable (the set of relevant documents for a given question) and then use this estimate to update the retriever and reader parameters. We hypothesize that such end-to-end training allows training signals to flow to the reader and then to the retriever better than staged-wise training. This results in a retriever that is able to select more relevant documents for a question and a reader that is trained on more accurate documents to generate an answer. Experiments on three benchmark datasets demonstrate that our proposed method outperforms all existing approaches of comparable size by 2-3% absolute exact match points, achieving new state-of-the-art results. Our results also demonstrate the feasibility of learning to retrieve to improve answer generation without explicit supervision of retrieval decisions.
A Review of Biomedical Datasets Relating to Drug Discovery: A Knowledge Graph Perspective
Feb 26, 2021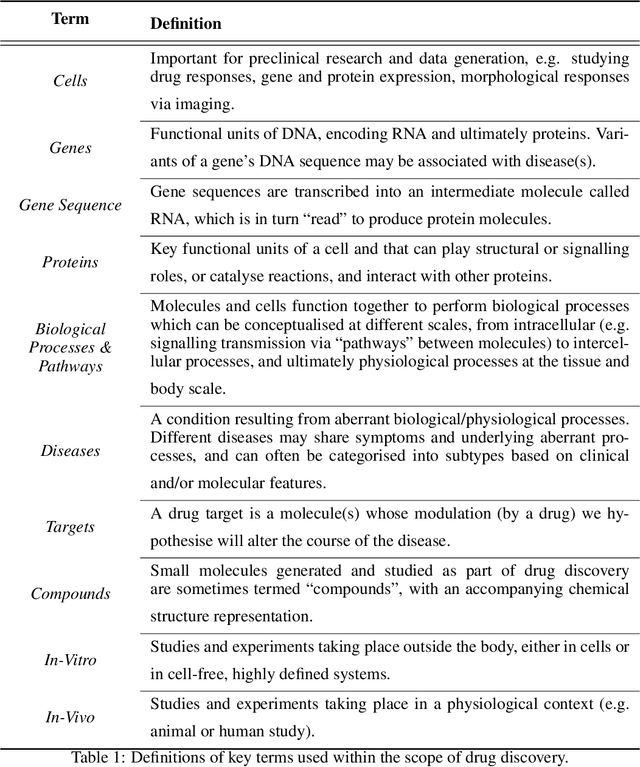
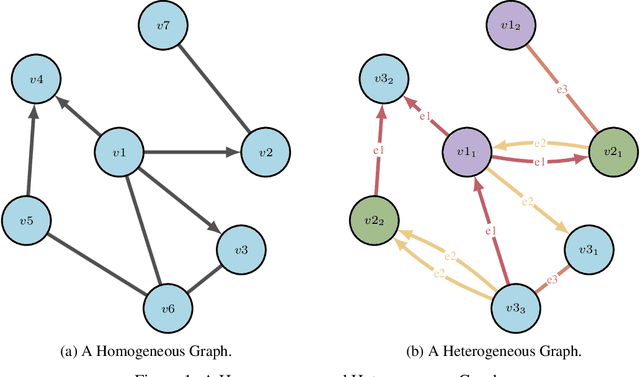
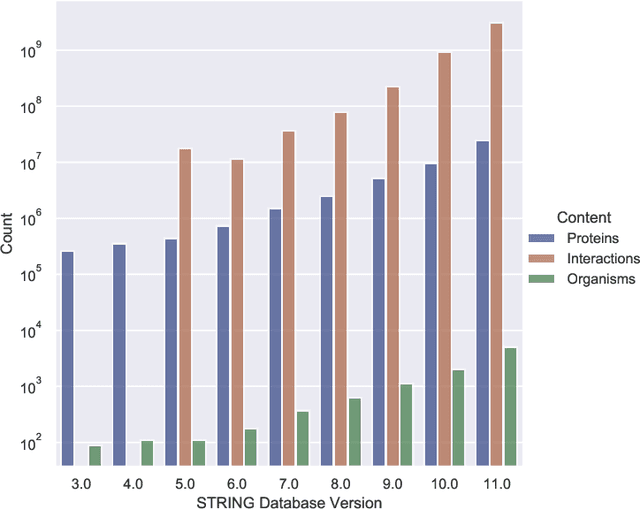
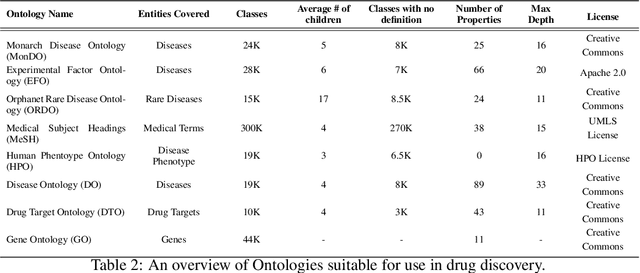
Drug discovery and development is an extremely complex process, with high attrition contributing to the costs of delivering new medicines to patients. Recently, various machine learning approaches have been proposed and investigated to help improve the effectiveness and speed of multiple stages of the drug discovery pipeline. Among these techniques, it is especially those using Knowledge Graphs that are proving to have considerable promise across a range of tasks, including drug repurposing, drug toxicity prediction and target gene-disease prioritisation. In such a knowledge graph-based representation of drug discovery domains, crucial elements including genes, diseases and drugs are represented as entities or vertices, whilst relationships or edges between them indicate some level of interaction. For example, an edge between a disease and drug entity might represent a successful clinical trial, or an edge between two drug entities could indicate a potentially harmful interaction. In order to construct high-quality and ultimately informative knowledge graphs however, suitable data and information is of course required. In this review, we detail publicly available primary data sources containing information suitable for use in constructing various drug discovery focused knowledge graphs. We aim to help guide machine learning and knowledge graph practitioners who are interested in applying new techniques to the drug discovery field, but who may be unfamiliar with the relevant data sources. Overall we hope this review will help motivate more machine learning researchers to explore combining knowledge graphs and machine learning to help solve key and emerging questions in the drug discovery domain.
Stronger Transformers for Neural Multi-Hop Question Generation
Oct 22, 2020
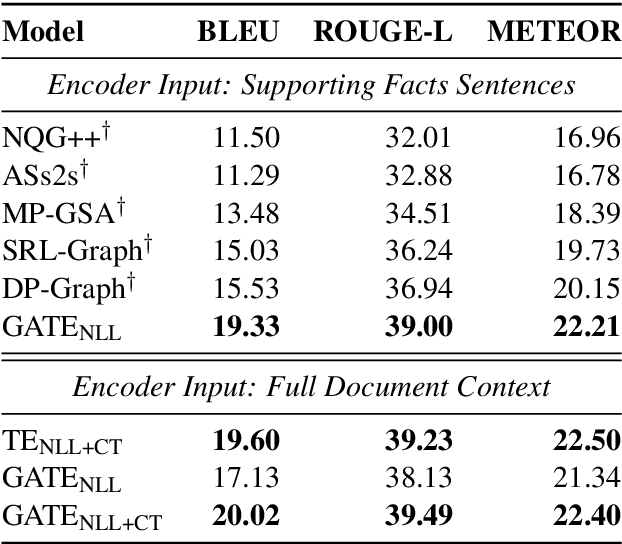

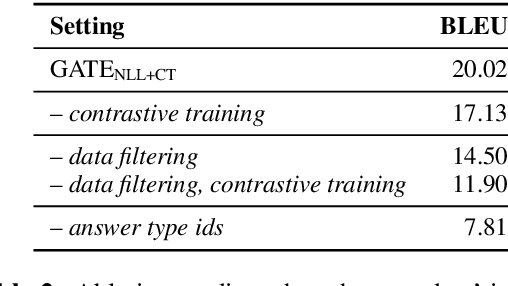
Prior work on automated question generation has almost exclusively focused on generating simple questions whose answers can be extracted from a single document. However, there is an increasing interest in developing systems that are capable of more complex multi-hop question generation, where answering the questions requires reasoning over multiple documents. In this work, we introduce a series of strong transformer models for multi-hop question generation, including a graph-augmented transformer that leverages relations between entities in the text. While prior work has emphasized the importance of graph-based models, we show that we can substantially outperform the state-of-the-art by 5 BLEU points using a standard transformer architecture. We further demonstrate that graph-based augmentations can provide complimentary improvements on top of this foundation. Interestingly, we find that several important factors--such as the inclusion of an auxiliary contrastive objective and data filtering could have larger impacts on performance. We hope that our stronger baselines and analysis provide a constructive foundation for future work in this area.
Do Syntax Trees Help Pre-trained Transformers Extract Information?
Aug 20, 2020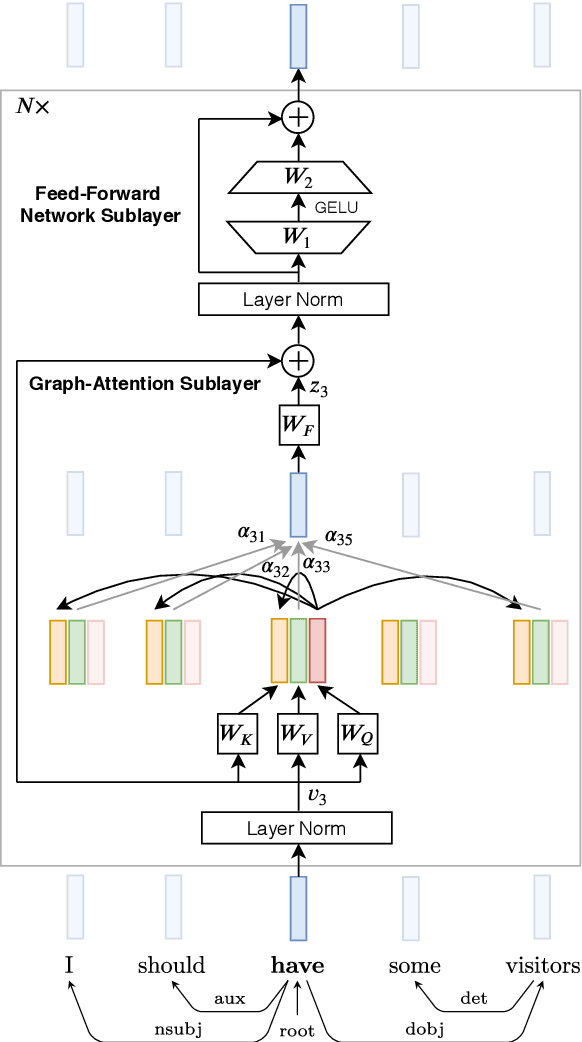
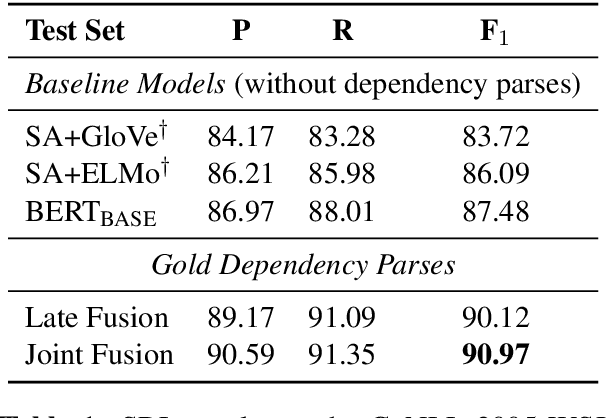
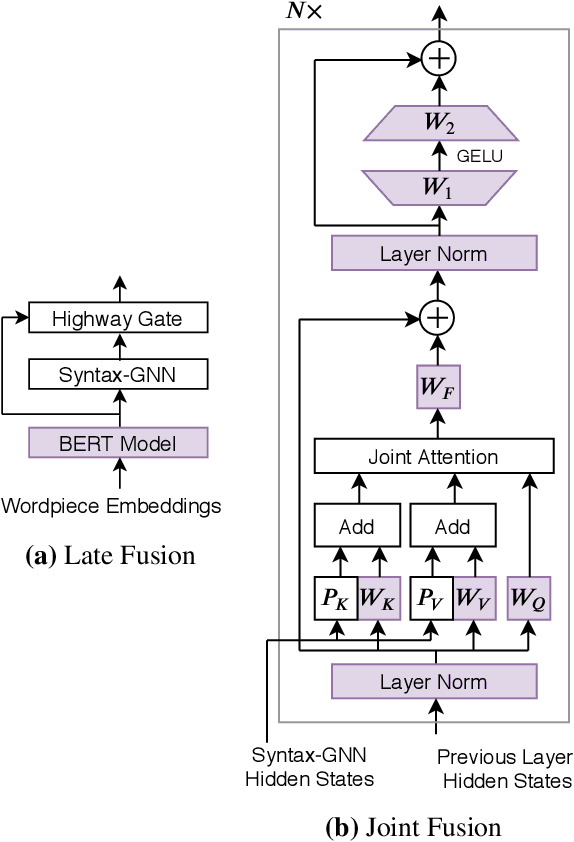
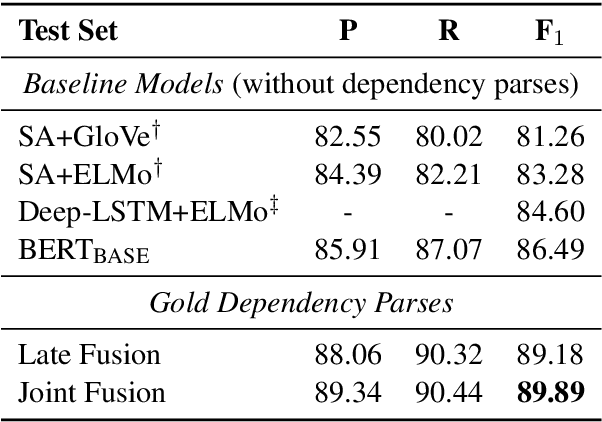
Much recent work suggests that incorporating syntax information from dependency trees can improve task-specific transformer models. However, the effect of incorporating dependency tree information into pre-trained transformer models (e.g., BERT) remains unclear, especially given recent studies highlighting how these models implicitly encode syntax. In this work, we systematically study the utility of incorporating dependency trees into pre-trained transformers on three representative information extraction tasks: semantic role labeling (SRL), named entity recognition, and relation extraction. We propose and investigate two distinct strategies for incorporating dependency structure: a late fusion approach, which applies a graph neural network on the output of a transformer, and a joint fusion approach, which infuses syntax structure into the transformer attention layers. These strategies are representative of prior work, but we introduce essential design decisions that are necessary for strong performance. Our empirical analysis demonstrates that these syntax-infused transformers obtain state-of-the-art results on SRL and relation extraction tasks. However, our analysis also reveals a critical shortcoming of these models: we find that their performance gains are highly contingent on the availability of human-annotated dependency parses, which raises important questions regarding the viability of syntax-augmented transformers in real-world applications.
A Universal Representation Transformer Layer for Few-Shot Image Classification
Jun 25, 2020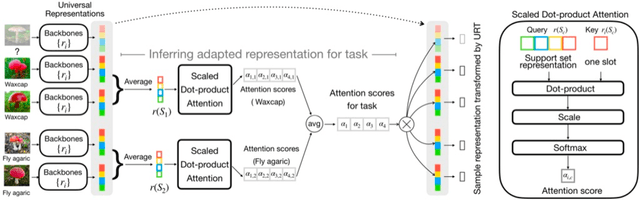



Few-shot classification aims to recognize unseen classes when presented with only a small number of samples. We consider the problem of multi-domain few-shot image classification, where unseen classes and examples come from diverse data sources. This problem has seen growing interest and has inspired the development of benchmarks such as Meta-Dataset. A key challenge in this multi-domain setting is to effectively integrate the feature representations from the diverse set of training domains. Here, we propose a Universal Representation Transformer (URT) layer, that meta-learns to leverage universal features for few-shot classification by dynamically re-weighting and composing the most appropriate domain-specific representations. In experiments, we show that URT sets a new state-of-the-art result on Meta-Dataset. Specifically, it outperforms the best previous model on three data sources or performs the same in others. We analyze variants of URT and present a visualization of the attention score heatmaps that sheds light on how the model performs cross-domain generalization. Our code is available at https://github.com/liulu112601/URT.
Actor Critic with Differentially Private Critic
Oct 14, 2019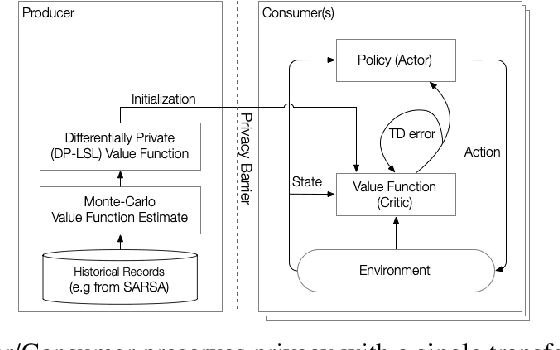

Reinforcement learning algorithms are known to be sample inefficient, and often performance on one task can be substantially improved by leveraging information (e.g., via pre-training) on other related tasks. In this work, we propose a technique to achieve such knowledge transfer in cases where agent trajectories contain sensitive or private information, such as in the healthcare domain. Our approach leverages a differentially private policy evaluation algorithm to initialize an actor-critic model and improve the effectiveness of learning in downstream tasks. We empirically show this technique increases sample efficiency in resource-constrained control problems while preserving the privacy of trajectories collected in an upstream task.
Compositional Fairness Constraints for Graph Embeddings
May 25, 2019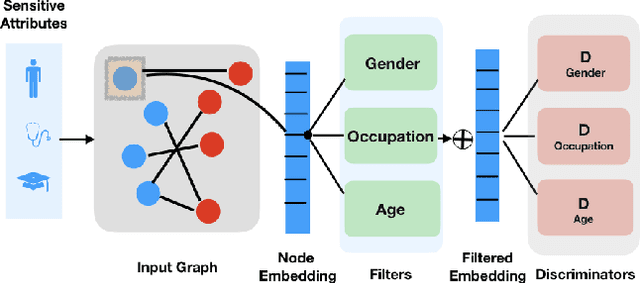



Learning high-quality node embeddings is a key building block for machine learning models that operate on graph data, such as social networks and recommender systems. However, existing graph embedding techniques are unable to cope with fairness constraints, e.g., ensuring that the learned representations do not correlate with certain attributes, such as age or gender. Here, we introduce an adversarial framework to enforce fairness constraints on graph embeddings. Our approach is {\em compositional}---meaning that it can flexibly accommodate different combinations of fairness constraints during inference. For instance, in the context of social recommendations, our framework would allow one user to request that their recommendations are invariant to both their age and gender, while also allowing another user to request invariance to just their age. Experiments on standard knowledge graph and recommender system benchmarks highlight the utility of our proposed framework.