Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor Critic with Differentially Private Critic
Paper and Code
Oct 14, 2019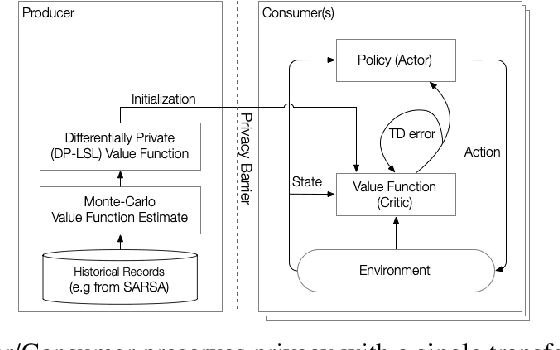

Reinforcement learning algorithms are known to be sample inefficient, and often performance on one task can be substantially improved by leveraging information (e.g., via pre-training) on other related tasks. In this work, we propose a technique to achieve such knowledge transfer in cases where agent trajectories contain sensitive or private information, such as in the healthcare domain. Our approach leverages a differentially private policy evaluation algorithm to initialize an actor-critic model and improve the effectiveness of learning in downstream tasks. We empirically show this technique increases sample efficiency in resource-constrained control problems while preserving the privacy of trajectories collected in an upstream task.
* 6 Pages, Presented at the Privacy in Machine Learning Workshop,
NeurIPS 2019
View paper on