 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
Mar 19, 2025We propose a new algorithm for fine-tuning large language models using reinforcement learning. Tapered Off-Policy REINFORCE (TOPR) uses an asymmetric, tapered variant of importance sampling to speed up learning while maintaining stable learning dynamics, even without the use of KL regularization. TOPR can be applied in a fully offline fashion, allows the handling of positive and negative examples in a unified framework, and benefits from the implementational simplicity that is typical of Monte Carlo algorithms. We demonstrate the effectiveness of our approach with a series of experiments on the GSM8K and MATH reasoning benchmarks, finding performance gains for training both a model for solution generation and as a generative verifier. We show that properly leveraging positive and negative examples alike in the off-policy regime simultaneously increases test-time accuracy and training data efficiency, all the while avoiding the ``wasted inference'' that comes with discarding negative examples. We find that this advantage persists over multiple iterations of training and can be amplified by dataset curation techniques, enabling us to match 70B-parameter model performance with 8B language models. As a corollary to this work, we find that REINFORCE's baseline parameter plays an important and unexpected role in defining dataset composition in the presence of negative examples, and is consequently critical in driving off-policy performance.
Mitigating Downstream Model Risks via Model Provenance
Oct 03, 2024
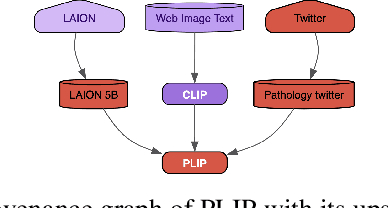

Research and industry are rapidly advancing the innovation and adoption of foundation model-based systems, yet the tools for managing these models have not kept pace. Understanding the provenance and lineage of models is critical for researchers, industry, regulators, and public trust. While model cards and system cards were designed to provide transparency, they fall short in key areas: tracing model genealogy, enabling machine readability, offering reliable centralized management systems, and fostering consistent creation incentives. This challenge mirrors issues in software supply chain security, but AI/ML remains at an earlier stage of maturity. Addressing these gaps requires industry-standard tooling that can be adopted by foundation model publishers, open-source model innovators, and major distribution platforms. We propose a machine-readable model specification format to simplify the creation of model records, thereby reducing error-prone human effort, notably when a new model inherits most of its design from a foundation model. Our solution explicitly traces relationships between upstream and downstream models, enhancing transparency and traceability across the model lifecycle. To facilitate the adoption, we introduce the unified model record (UMR) repository , a semantically versioned system that automates the publication of model records to multiple formats (PDF, HTML, LaTeX) and provides a hosted web interface (https://modelrecord.com/). This proof of concept aims to set a new standard for managing foundation models, bridging the gap between innovation and responsible model management.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024



Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
On the Privacy of Selection Mechanisms with Gaussian Noise
Feb 09, 2024



Report Noisy Max and Above Threshold are two classical differentially private (DP) selection mechanisms. Their output is obtained by adding noise to a sequence of low-sensitivity queries and reporting the identity of the query whose (noisy) answer satisfies a certain condition. Pure DP guarantees for these mechanisms are easy to obtain when Laplace noise is added to the queries. On the other hand, when instantiated using Gaussian noise, standard analyses only yield approximate DP guarantees despite the fact that the outputs of these mechanisms lie in a discrete space. In this work, we revisit the analysis of Report Noisy Max and Above Threshold with Gaussian noise and show that, under the additional assumption that the underlying queries are bounded, it is possible to provide pure ex-ante DP bounds for Report Noisy Max and pure ex-post DP bounds for Above Threshold. The resulting bounds are tight and depend on closed-form expressions that can be numerically evaluated using standard methods. Empirically we find these lead to tighter privacy accounting in the high privacy, low data regime. Further, we propose a simple privacy filter for composing pure ex-post DP guarantees, and use it to derive a fully adaptive Gaussian Sparse Vector Technique mechanism. Finally, we provide experiments on mobility and energy consumption datasets demonstrating that our Sparse Vector Technique is practically competitive with previous approaches and requires less hyper-parameter tuning.
Filling gaps in trustworthy development of AI
Dec 14, 2021The range of application of artificial intelligence (AI) is vast, as is the potential for harm. Growing awareness of potential risks from AI systems has spurred action to address those risks, while eroding confidence in AI systems and the organizations that develop them. A 2019 study found over 80 organizations that published and adopted "AI ethics principles'', and more have joined since. But the principles often leave a gap between the "what" and the "how" of trustworthy AI development. Such gaps have enabled questionable or ethically dubious behavior, which casts doubts on the trustworthiness of specific organizations, and the field more broadly. There is thus an urgent need for concrete methods that both enable AI developers to prevent harm and allow them to demonstrate their trustworthiness through verifiable behavior. Below, we explore mechanisms (drawn from arXiv:2004.07213) for creating an ecosystem where AI developers can earn trust - if they are trustworthy. Better assessment of developer trustworthiness could inform user choice, employee actions, investment decisions, legal recourse, and emerging governance regimes.
Actor Critic with Differentially Private Critic
Oct 14, 2019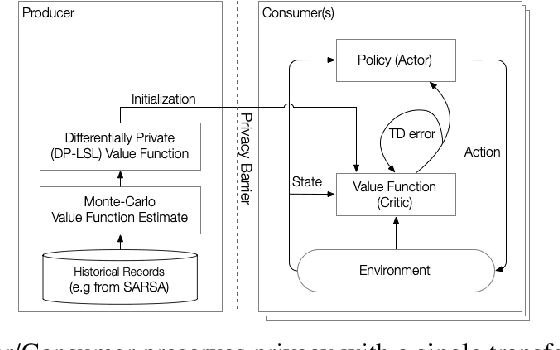

Reinforcement learning algorithms are known to be sample inefficient, and often performance on one task can be substantially improved by leveraging information (e.g., via pre-training) on other related tasks. In this work, we propose a technique to achieve such knowledge transfer in cases where agent trajectories contain sensitive or private information, such as in the healthcare domain. Our approach leverages a differentially private policy evaluation algorithm to initialize an actor-critic model and improve the effectiveness of learning in downstream tasks. We empirically show this technique increases sample efficiency in resource-constrained control problems while preserving the privacy of trajectories collected in an upstream task.
Neural Transfer Learning for Cry-based Diagnosis of Perinatal Asphyxia
Jul 02, 2019
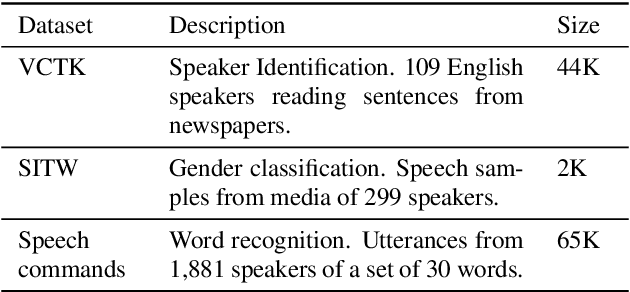
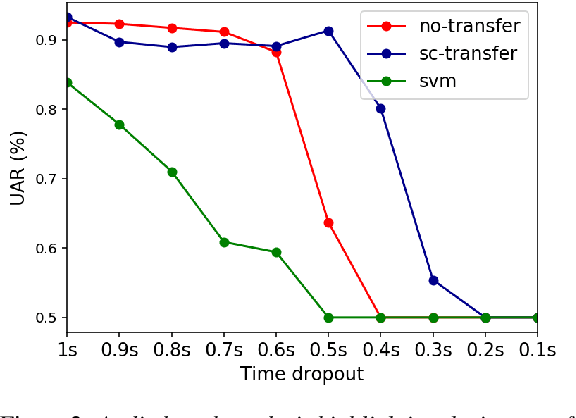
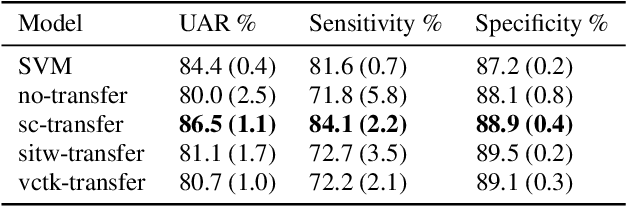
Despite continuing medical advances, the rate of newborn morbidity and mortality globally remains high, with over 6 million casualties every year. The prediction of pathologies affecting newborns based on their cry is thus of significant clinical interest, as it would facilitate the development of accessible, low-cost diagnostic tools\cut{ based on wearables and smartphones}. However, the inadequacy of clinically annotated datasets of infant cries limits progress on this task. This study explores a neural transfer learning approach to developing accurate and robust models for identifying infants that have suffered from perinatal asphyxia. In particular, we explore the hypothesis that representations learned from adult speech could inform and improve performance of models developed on infant speech. Our experiments show that models based on such representation transfer are resilient to different types and degrees of noise, as well as to signal loss in time and frequency domains.