 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
Mar 19, 2025We propose a new algorithm for fine-tuning large language models using reinforcement learning. Tapered Off-Policy REINFORCE (TOPR) uses an asymmetric, tapered variant of importance sampling to speed up learning while maintaining stable learning dynamics, even without the use of KL regularization. TOPR can be applied in a fully offline fashion, allows the handling of positive and negative examples in a unified framework, and benefits from the implementational simplicity that is typical of Monte Carlo algorithms. We demonstrate the effectiveness of our approach with a series of experiments on the GSM8K and MATH reasoning benchmarks, finding performance gains for training both a model for solution generation and as a generative verifier. We show that properly leveraging positive and negative examples alike in the off-policy regime simultaneously increases test-time accuracy and training data efficiency, all the while avoiding the ``wasted inference'' that comes with discarding negative examples. We find that this advantage persists over multiple iterations of training and can be amplified by dataset curation techniques, enabling us to match 70B-parameter model performance with 8B language models. As a corollary to this work, we find that REINFORCE's baseline parameter plays an important and unexpected role in defining dataset composition in the presence of negative examples, and is consequently critical in driving off-policy performance.
Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy
Nov 21, 2023We introduce a machine learning approach to determine the transition dynamics of silicon atoms on a single layer of carbon atoms, when stimulated by the electron beam of a scanning transmission electron microscope (STEM). Our method is data-centric, leveraging data collected on a STEM. The data samples are processed and filtered to produce symbolic representations, which we use to train a neural network to predict transition probabilities. These learned transition dynamics are then leveraged to guide a single silicon atom throughout the lattice to pre-determined target destinations. We present empirical analyses that demonstrate the efficacy and generality of our approach.
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks
Apr 25, 2023Auxiliary tasks improve the representations learned by deep reinforcement learning agents. Analytically, their effect is reasonably well understood; in practice, however, their primary use remains in support of a main learning objective, rather than as a method for learning representations. This is perhaps surprising given that many auxiliary tasks are defined procedurally, and hence can be treated as an essentially infinite source of information about the environment. Based on this observation, we study the effectiveness of auxiliary tasks for learning rich representations, focusing on the setting where the number of tasks and the size of the agent's network are simultaneously increased. For this purpose, we derive a new family of auxiliary tasks based on the successor measure. These tasks are easy to implement and have appealing theoretical properties. Combined with a suitable off-policy learning rule, the result is a representation learning algorithm that can be understood as extending Mahadevan & Maggioni (2007)'s proto-value functions to deep reinforcement learning -- accordingly, we call the resulting object proto-value networks. Through a series of experiments on the Arcade Learning Environment, we demonstrate that proto-value networks produce rich features that may be used to obtain performance comparable to established algorithms, using only linear approximation and a small number (~4M) of interactions with the environment's reward function.
A Novel Stochastic Gradient Descent Algorithm for Learning Principal Subspaces
Dec 08, 2022
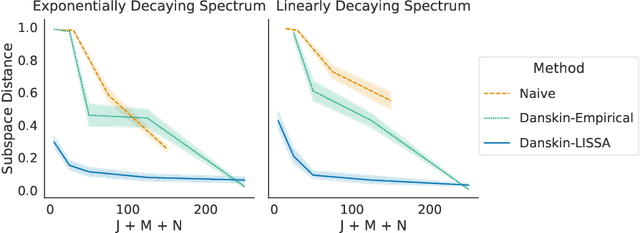


Many machine learning problems encode their data as a matrix with a possibly very large number of rows and columns. In several applications like neuroscience, image compression or deep reinforcement learning, the principal subspace of such a matrix provides a useful, low-dimensional representation of individual data. Here, we are interested in determining the $d$-dimensional principal subspace of a given matrix from sample entries, i.e. from small random submatrices. Although a number of sample-based methods exist for this problem (e.g. Oja's rule \citep{oja1982simplified}), these assume access to full columns of the matrix or particular matrix structure such as symmetry and cannot be combined as-is with neural networks \citep{baldi1989neural}. In this paper, we derive an algorithm that learns a principal subspace from sample entries, can be applied when the approximate subspace is represented by a neural network, and hence can be scaled to datasets with an effectively infinite number of rows and columns. Our method consists in defining a loss function whose minimizer is the desired principal subspace, and constructing a gradient estimate of this loss whose bias can be controlled. We complement our theoretical analysis with a series of experiments on synthetic matrices, the MNIST dataset \citep{lecun2010mnist} and the reinforcement learning domain PuddleWorld \citep{sutton1995generalization} demonstrating the usefulness of our approach.
Multi-path Neural Networks for On-device Multi-domain Visual Classification
Oct 10, 2020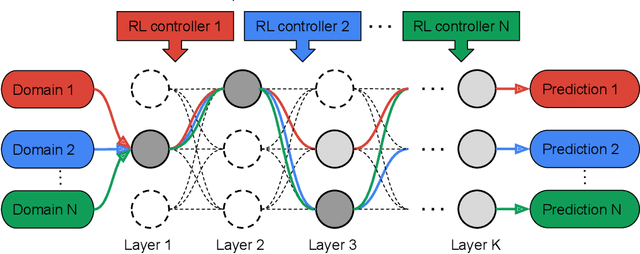
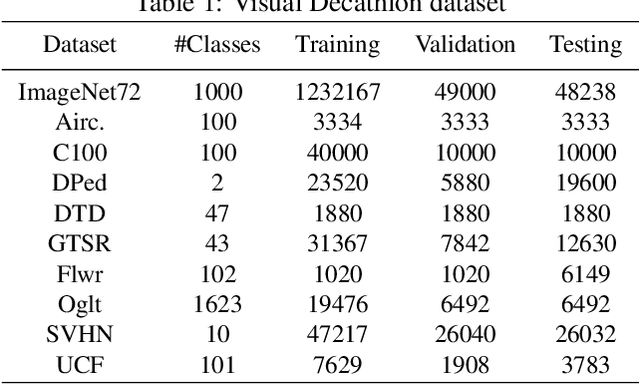
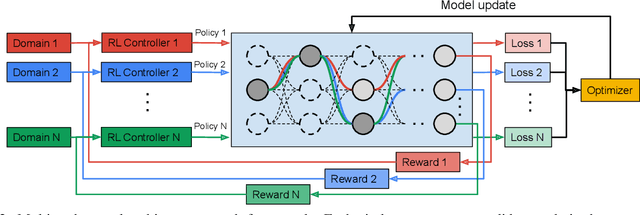
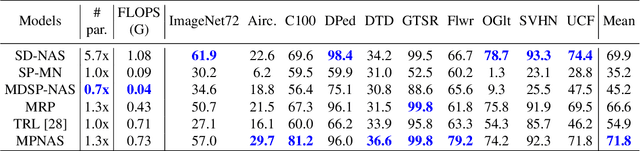
Learning multiple domains/tasks with a single model is important for improving data efficiency and lowering inference cost for numerous vision tasks, especially on resource-constrained mobile devices. However, hand-crafting a multi-domain/task model can be both tedious and challenging. This paper proposes a novel approach to automatically learn a multi-path network for multi-domain visual classification on mobile devices. The proposed multi-path network is learned from neural architecture search by applying one reinforcement learning controller for each domain to select the best path in the super-network created from a MobileNetV3-like search space. An adaptive balanced domain prioritization algorithm is proposed to balance optimizing the joint model on multiple domains simultaneously. The determined multi-path model selectively shares parameters across domains in shared nodes while keeping domain-specific parameters within non-shared nodes in individual domain paths. This approach effectively reduces the total number of parameters and FLOPS, encouraging positive knowledge transfer while mitigating negative interference across domains. Extensive evaluations on the Visual Decathlon dataset demonstrate that the proposed multi-path model achieves state-of-the-art performance in terms of accuracy, model size, and FLOPS against other approaches using MobileNetV3-like architectures. Furthermore, the proposed method improves average accuracy over learning single-domain models individually, and reduces the total number of parameters and FLOPS by 78% and 32% respectively, compared to the approach that simply bundles single-domain models for multi-domain learning.