 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
Mar 19, 2025We propose a new algorithm for fine-tuning large language models using reinforcement learning. Tapered Off-Policy REINFORCE (TOPR) uses an asymmetric, tapered variant of importance sampling to speed up learning while maintaining stable learning dynamics, even without the use of KL regularization. TOPR can be applied in a fully offline fashion, allows the handling of positive and negative examples in a unified framework, and benefits from the implementational simplicity that is typical of Monte Carlo algorithms. We demonstrate the effectiveness of our approach with a series of experiments on the GSM8K and MATH reasoning benchmarks, finding performance gains for training both a model for solution generation and as a generative verifier. We show that properly leveraging positive and negative examples alike in the off-policy regime simultaneously increases test-time accuracy and training data efficiency, all the while avoiding the ``wasted inference'' that comes with discarding negative examples. We find that this advantage persists over multiple iterations of training and can be amplified by dataset curation techniques, enabling us to match 70B-parameter model performance with 8B language models. As a corollary to this work, we find that REINFORCE's baseline parameter plays an important and unexpected role in defining dataset composition in the presence of negative examples, and is consequently critical in driving off-policy performance.
Fast Convergence of Softmax Policy Mirror Ascent
Nov 18, 2024Natural policy gradient (NPG) is a common policy optimization algorithm and can be viewed as mirror ascent in the space of probabilities. Recently, Vaswani et al. [2021] introduced a policy gradient method that corresponds to mirror ascent in the dual space of logits. We refine this algorithm, removing its need for a normalization across actions and analyze the resulting method (referred to as SPMA). For tabular MDPs, we prove that SPMA with a constant step-size matches the linear convergence of NPG and achieves a faster convergence than constant step-size (accelerated) softmax policy gradient. To handle large state-action spaces, we extend SPMA to use a log-linear policy parameterization. Unlike that for NPG, generalizing SPMA to the linear function approximation (FA) setting does not require compatible function approximation. Unlike MDPO, a practical generalization of NPG, SPMA with linear FA only requires solving convex softmax classification problems. We prove that SPMA achieves linear convergence to the neighbourhood of the optimal value function. We extend SPMA to handle non-linear FA and evaluate its empirical performance on the MuJoCo and Atari benchmarks. Our results demonstrate that SPMA consistently achieves similar or better performance compared to MDPO, PPO and TRPO.
fPLSA: Learning Semantic Structures in Document Collections Using Foundation Models
Oct 07, 2024



Humans have the ability to learn new tasks by inferring high-level concepts from existing solution, then manipulating these concepts in lieu of the raw data. Can we automate this process by deriving latent semantic structures in a document collection using foundation models? We introduce fPLSA, a foundation-model-based Probabilistic Latent Semantic Analysis (PLSA) method that iteratively clusters and tags document segments based on document-level contexts. These tags can be used to model the structure of given documents and for hierarchical sampling of new texts. Our experiments on story writing, math, and multi-step reasoning datasets demonstrate that fPLSA tags help reconstruct the original texts better than existing tagging methods. Moreover, when used for hierarchical sampling, fPLSA produces more diverse outputs with a higher likelihood of hitting the correct answer than direct sampling and hierarchical sampling with existing tagging methods.
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
Oct 02, 2024



Large language models (LLMs) are increasingly applied to complex reasoning tasks that require executing several complex steps before receiving any reward. Properly assigning credit to these steps is essential for enhancing model performance. Proximal Policy Optimization (PPO), a state-of-the-art reinforcement learning (RL) algorithm used for LLM finetuning, employs value networks to tackle credit assignment. However, value networks face challenges in predicting the expected cumulative rewards accurately in complex reasoning tasks, often leading to high-variance updates and suboptimal performance. In this work, we systematically evaluate the efficacy of value networks and reveal their significant shortcomings in reasoning-heavy LLM tasks, showing that they barely outperform a random baseline when comparing alternative steps. To address this, we propose VinePPO, a straightforward approach that leverages the flexibility of language environments to compute unbiased Monte Carlo-based estimates, bypassing the need for large value networks. Our method consistently outperforms PPO and other RL-free baselines across MATH and GSM8K datasets with fewer gradient updates (up to 9x), less wall-clock time (up to 3.0x). These results emphasize the importance of accurate credit assignment in RL finetuning of LLM and demonstrate VinePPO's potential as a superior alternative.
Improving Context-Aware Preference Modeling for Language Models
Jul 20, 2024



While finetuning language models from pairwise preferences has proven remarkably effective, the underspecified nature of natural language presents critical challenges. Direct preference feedback is uninterpretable, difficult to provide where multidimensional criteria may apply, and often inconsistent, either because it is based on incomplete instructions or provided by diverse principals. To address these challenges, we consider the two-step preference modeling procedure that first resolves the under-specification by selecting a context, and then evaluates preference with respect to the chosen context. We decompose reward modeling error according to these two steps, which suggests that supervising context in addition to context-specific preference may be a viable approach to aligning models with diverse human preferences. For this to work, the ability of models to evaluate context-specific preference is critical. To this end, we contribute context-conditioned preference datasets and accompanying experiments that investigate the ability of language models to evaluate context-specific preference. We use our datasets to (1) show that existing preference models benefit from, but fail to fully consider, added context, (2) finetune a context-aware reward model with context-specific performance exceeding that of GPT-4 and Llama 3 70B on tested datasets, and (3) investigate the value of context-aware preference modeling.
Towards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024


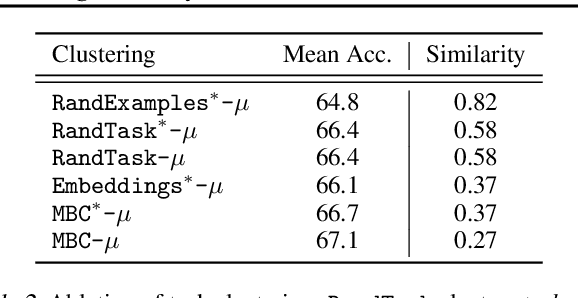
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Language-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024



We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023



We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
Unraveling the Interconnected Axes of Heterogeneity in Machine Learning for Democratic and Inclusive Advancements
Jun 11, 2023The growing utilization of machine learning (ML) in decision-making processes raises questions about its benefits to society. In this study, we identify and analyze three axes of heterogeneity that significantly influence the trajectory of ML products. These axes are i) values, culture and regulations, ii) data composition, and iii) resource and infrastructure capacity. We demonstrate how these axes are interdependent and mutually influence one another, emphasizing the need to consider and address them jointly. Unfortunately, the current research landscape falls short in this regard, often failing to adopt a holistic approach. We examine the prevalent practices and methodologies that skew these axes in favor of a selected few, resulting in power concentration, homogenized control, and increased dependency. We discuss how this fragmented study of the three axes poses a significant challenge, leading to an impractical solution space that lacks reflection of real-world scenarios. Addressing these issues is crucial to ensure a more comprehensive understanding of the interconnected nature of society and to foster the democratic and inclusive development of ML systems that are more aligned with real-world complexities and its diverse requirements.
Decision-Aware Actor-Critic with Function Approximation and Theoretical Guarantees
May 24, 2023Actor-critic (AC) methods are widely used in reinforcement learning (RL) and benefit from the flexibility of using any policy gradient method as the actor and value-based method as the critic. The critic is usually trained by minimizing the TD error, an objective that is potentially decorrelated with the true goal of achieving a high reward with the actor. We address this mismatch by designing a joint objective for training the actor and critic in a decision-aware fashion. We use the proposed objective to design a generic, AC algorithm that can easily handle any function approximation. We explicitly characterize the conditions under which the resulting algorithm guarantees monotonic policy improvement, regardless of the choice of the policy and critic parameterization. Instantiating the generic algorithm results in an actor that involves maximizing a sequence of surrogate functions (similar to TRPO, PPO) and a critic that involves minimizing a closely connected objective. Using simple bandit examples, we provably establish the benefit of the proposed critic objective over the standard squared error. Finally, we empirically demonstrate the benefit of our decision-aware actor-critic framework on simple RL problems.