 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Federated Learning: Fairness for Whom?
May 27, 2025Fairness in federated learning has emerged as a rapidly growing area of research, with numerous works proposing formal definitions and algorithmic interventions. Yet, despite this technical progress, fairness in FL is often defined and evaluated in ways that abstract away from the sociotechnical contexts in which these systems are deployed. In this paper, we argue that existing approaches tend to optimize narrow system level metrics, such as performance parity or contribution-based rewards, while overlooking how harms arise throughout the FL lifecycle and how they impact diverse stakeholders. We support this claim through a critical analysis of the literature, based on a systematic annotation of papers for their fairness definitions, design decisions, evaluation practices, and motivating use cases. Our analysis reveals five recurring pitfalls: 1) fairness framed solely through the lens of server client architecture, 2) a mismatch between simulations and motivating use-cases and contexts, 3) definitions that conflate protecting the system with protecting its users, 4) interventions that target isolated stages of the lifecycle while neglecting upstream and downstream effects, 5) and a lack of multi-stakeholder alignment where multiple fairness definitions can be relevant at once. Building on these insights, we propose a harm centered framework that links fairness definitions to concrete risks and stakeholder vulnerabilities. We conclude with recommendations for more holistic, context-aware, and accountable fairness research in FL.
Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025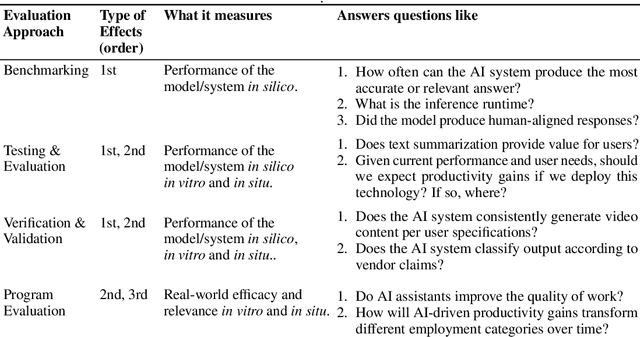

Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
The Curious Case of Arbitrariness in Machine Learning
Jan 24, 2025Algorithmic modelling relies on limited information in data to extrapolate outcomes for unseen scenarios, often embedding an element of arbitrariness in its decisions. A perspective on this arbitrariness that has recently gained interest is multiplicity-the study of arbitrariness across a set of "good models", i.e., those likely to be deployed in practice. In this work, we systemize the literature on multiplicity by: (a) formalizing the terminology around model design choices and their contribution to arbitrariness, (b) expanding the definition of multiplicity to incorporate underrepresented forms beyond just predictions and explanations, (c) clarifying the distinction between multiplicity and other traditional lenses of arbitrariness, i.e., uncertainty and variance, and (d) distilling the benefits and potential risks of multiplicity into overarching trends, situating it within the broader landscape of responsible AI. We conclude by identifying open research questions and highlighting emerging trends in this young but rapidly growing area of research.
Mitigating Disparate Impact of Differential Privacy in Federated Learning through Robust Clustering
May 29, 2024Federated Learning (FL) is a decentralized machine learning (ML) approach that keeps data localized and often incorporates Differential Privacy (DP) to enhance privacy guarantees. Similar to previous work on DP in ML, we observed that differentially private federated learning (DPFL) introduces performance disparities, particularly affecting minority groups. Recent work has attempted to address performance fairness in vanilla FL through clustering, but this method remains sensitive and prone to errors, which are further exacerbated by the DP noise in DPFL. To fill this gap, in this paper, we propose a novel clustered DPFL algorithm designed to effectively identify clients' clusters in highly heterogeneous settings while maintaining high accuracy with DP guarantees. To this end, we propose to cluster clients based on both their model updates and training loss values. Our proposed approach also addresses the server's uncertainties in clustering clients' model updates by employing larger batch sizes along with Gaussian Mixture Model (GMM) to alleviate the impact of noise and potential clustering errors, especially in privacy-sensitive scenarios. We provide theoretical analysis of the effectiveness of our proposed approach. We also extensively evaluate our approach across diverse data distributions and privacy budgets and show its effectiveness in mitigating the disparate impact of DP in FL settings with a small computational cost.
From Representational Harms to Quality-of-Service Harms: A Case Study on Llama 2 Safety Safeguards
Mar 21, 2024



Recent progress in large language models (LLMs) has led to their widespread adoption in various domains. However, these advancements have also introduced additional safety risks and raised concerns regarding their detrimental impact on already marginalized populations. Despite growing mitigation efforts to develop safety safeguards, such as supervised safety-oriented fine-tuning and leveraging safe reinforcement learning from human feedback, multiple concerns regarding the safety and ingrained biases in these models remain. Furthermore, previous work has demonstrated that models optimized for safety often display exaggerated safety behaviors, such as a tendency to refrain from responding to certain requests as a precautionary measure. As such, a clear trade-off between the helpfulness and safety of these models has been documented in the literature. In this paper, we further investigate the effectiveness of safety measures by evaluating models on already mitigated biases. Using the case of Llama 2 as an example, we illustrate how LLMs' safety responses can still encode harmful assumptions. To do so, we create a set of non-toxic prompts, which we then use to evaluate Llama models. Through our new taxonomy of LLMs responses to users, we observe that the safety/helpfulness trade-offs are more pronounced for certain demographic groups which can lead to quality-of-service harms for marginalized populations.
Unraveling the Interconnected Axes of Heterogeneity in Machine Learning for Democratic and Inclusive Advancements
Jun 11, 2023The growing utilization of machine learning (ML) in decision-making processes raises questions about its benefits to society. In this study, we identify and analyze three axes of heterogeneity that significantly influence the trajectory of ML products. These axes are i) values, culture and regulations, ii) data composition, and iii) resource and infrastructure capacity. We demonstrate how these axes are interdependent and mutually influence one another, emphasizing the need to consider and address them jointly. Unfortunately, the current research landscape falls short in this regard, often failing to adopt a holistic approach. We examine the prevalent practices and methodologies that skew these axes in favor of a selected few, resulting in power concentration, homogenized control, and increased dependency. We discuss how this fragmented study of the three axes poses a significant challenge, leading to an impractical solution space that lacks reflection of real-world scenarios. Addressing these issues is crucial to ensure a more comprehensive understanding of the interconnected nature of society and to foster the democratic and inclusive development of ML systems that are more aligned with real-world complexities and its diverse requirements.
Empowering Prosumer Communities in Smart Grid with Wireless Communications and Federated Edge Learning
Apr 07, 2021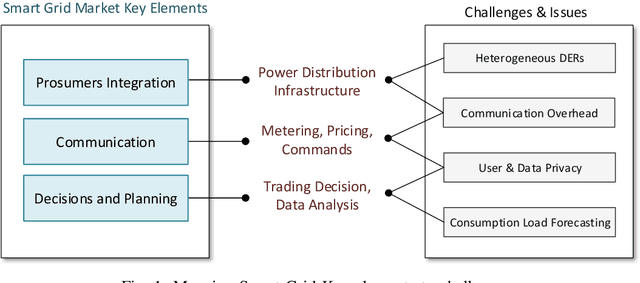
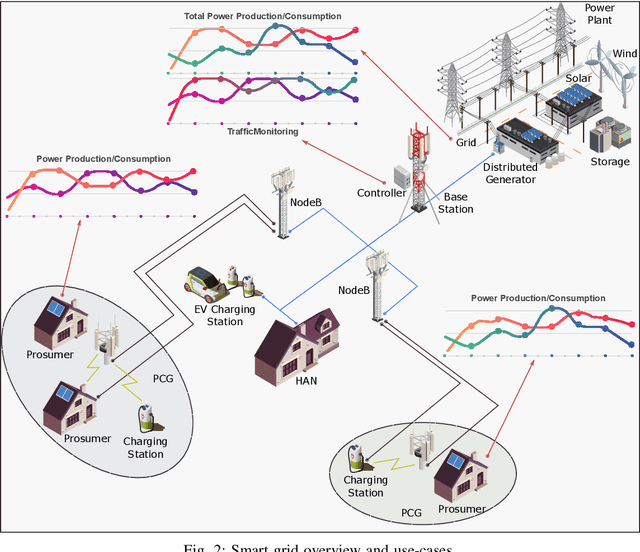
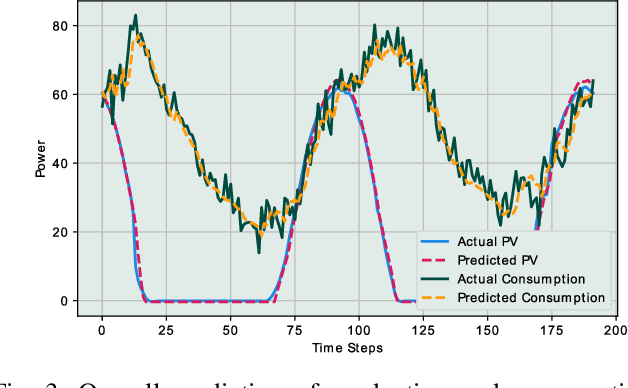
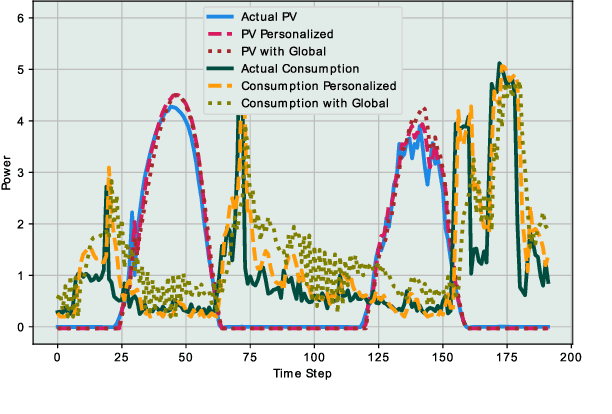
The exponential growth of distributed energy resources is enabling the transformation of traditional consumers in the smart grid into prosumers. Such transition presents a promising opportunity for sustainable energy trading. Yet, the integration of prosumers in the energy market imposes new considerations in designing unified and sustainable frameworks for efficient use of the power and communication infrastructure. Furthermore, several issues need to be tackled to adequately promote the adoption of decentralized renewable-oriented systems, such as communication overhead, data privacy, scalability, and sustainability. In this article, we present the different aspects and challenges to be addressed for building efficient energy trading markets in relation to communication and smart decision-making. Accordingly, we propose a multi-level pro-decision framework for prosumer communities to achieve collective goals. Since the individual decisions of prosumers are mainly driven by individual self-sufficiency goals, the framework prioritizes the individual prosumers' decisions and relies on 5G wireless network for fast coordination among community members. In fact, each prosumer predicts energy production and consumption to make proactive trading decisions as a response to collective-level requests. Moreover, the collaboration of the community is further extended by including the collaborative training of prediction models using Federated Learning, assisted by edge servers and prosumer home-area equipment. In addition to preserving prosumers' privacy, we show through evaluations that training prediction models using Federated Learning yields high accuracy for different energy resources while reducing the communication overhead.
Data-Aware Device Scheduling for Federated Edge Learning
Feb 18, 2021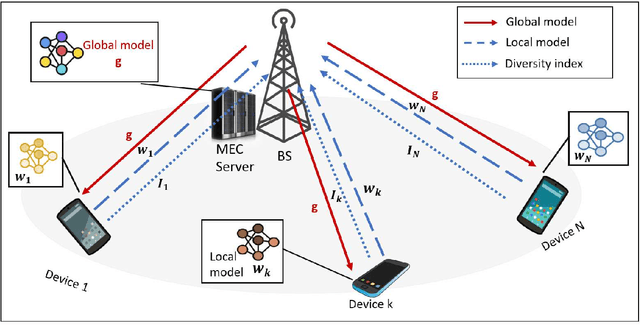


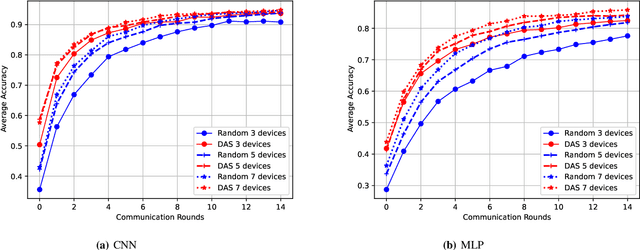
Federated Edge Learning (FEEL) involves the collaborative training of machine learning models among edge devices, with the orchestration of a server in a wireless edge network. Due to frequent model updates, FEEL needs to be adapted to the limited communication bandwidth, scarce energy of edge devices, and the statistical heterogeneity of edge devices' data distributions. Therefore, a careful scheduling of a subset of devices for training and uploading models is necessary. In contrast to previous work in FEEL where the data aspects are under-explored, we consider data properties at the heart of the proposed scheduling algorithm. To this end, we propose a new scheduling scheme for non-independent and-identically-distributed (non-IID) and unbalanced datasets in FEEL. As the data is the key component of the learning, we propose a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. In fact, the data collected by the devices depends on the local environment and usage pattern. Thus, the datasets vary in size and distributions among the devices. In the proposed algorithm, we consider both data and resource perspectives. In addition to minimizing the completion time of FEEL as well as the transmission energy of the participating devices, the algorithm prioritizes devices with rich and diverse datasets. We first define a general framework for the data-aware scheduling and the main axes and requirements for diversity evaluation. Then, we discuss diversity aspects and some exploitable techniques and metrics. Next, we formulate the problem and present our FEEL scheduling algorithm. Evaluations in different scenarios show that our proposed FEEL scheduling algorithm can help achieve high accuracy in few rounds with a reduced cost.