 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Aware Device Scheduling for Federated Edge Learning
Paper and Code
Feb 18, 2021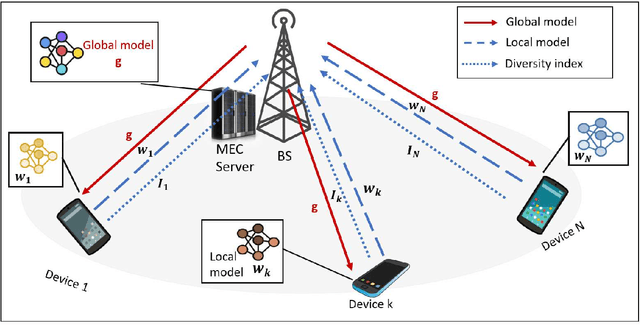


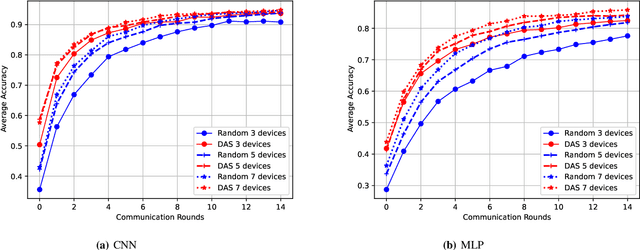
Federated Edge Learning (FEEL) involves the collaborative training of machine learning models among edge devices, with the orchestration of a server in a wireless edge network. Due to frequent model updates, FEEL needs to be adapted to the limited communication bandwidth, scarce energy of edge devices, and the statistical heterogeneity of edge devices' data distributions. Therefore, a careful scheduling of a subset of devices for training and uploading models is necessary. In contrast to previous work in FEEL where the data aspects are under-explored, we consider data properties at the heart of the proposed scheduling algorithm. To this end, we propose a new scheduling scheme for non-independent and-identically-distributed (non-IID) and unbalanced datasets in FEEL. As the data is the key component of the learning, we propose a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. In fact, the data collected by the devices depends on the local environment and usage pattern. Thus, the datasets vary in size and distributions among the devices. In the proposed algorithm, we consider both data and resource perspectives. In addition to minimizing the completion time of FEEL as well as the transmission energy of the participating devices, the algorithm prioritizes devices with rich and diverse datasets. We first define a general framework for the data-aware scheduling and the main axes and requirements for diversity evaluation. Then, we discuss diversity aspects and some exploitable techniques and metrics. Next, we formulate the problem and present our FEEL scheduling algorithm. Evaluations in different scenarios show that our proposed FEEL scheduling algorithm can help achieve high accuracy in few rounds with a reduced cost.