 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeither Valid nor Reliable? Investigating the Use of LLMs as Judges
Aug 25, 2025
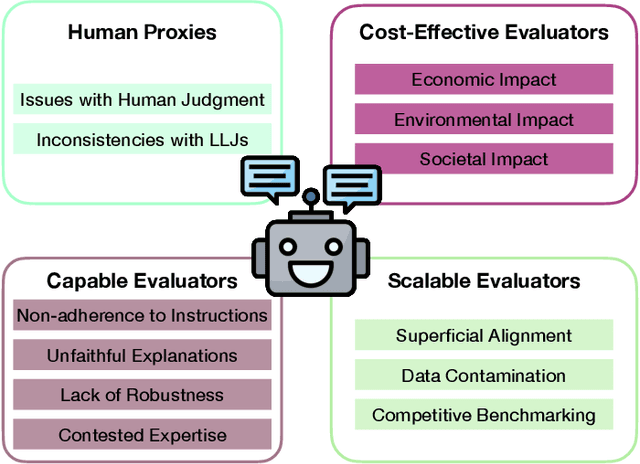


Evaluating natural language generation (NLG) systems remains a core challenge of natural language processing (NLP), further complicated by the rise of large language models (LLMs) that aims to be general-purpose. Recently, large language models as judges (LLJs) have emerged as a promising alternative to traditional metrics, but their validity remains underexplored. This position paper argues that the current enthusiasm around LLJs may be premature, as their adoption has outpaced rigorous scrutiny of their reliability and validity as evaluators. Drawing on measurement theory from the social sciences, we identify and critically assess four core assumptions underlying the use of LLJs: their ability to act as proxies for human judgment, their capabilities as evaluators, their scalability, and their cost-effectiveness. We examine how each of these assumptions may be challenged by the inherent limitations of LLMs, LLJs, or current practices in NLG evaluation. To ground our analysis, we explore three applications of LLJs: text summarization, data annotation, and safety alignment. Finally, we highlight the need for more responsible evaluation practices in LLJs evaluation, to ensure that their growing role in the field supports, rather than undermines, progress in NLG.
Fairness in Federated Learning: Fairness for Whom?
May 27, 2025Fairness in federated learning has emerged as a rapidly growing area of research, with numerous works proposing formal definitions and algorithmic interventions. Yet, despite this technical progress, fairness in FL is often defined and evaluated in ways that abstract away from the sociotechnical contexts in which these systems are deployed. In this paper, we argue that existing approaches tend to optimize narrow system level metrics, such as performance parity or contribution-based rewards, while overlooking how harms arise throughout the FL lifecycle and how they impact diverse stakeholders. We support this claim through a critical analysis of the literature, based on a systematic annotation of papers for their fairness definitions, design decisions, evaluation practices, and motivating use cases. Our analysis reveals five recurring pitfalls: 1) fairness framed solely through the lens of server client architecture, 2) a mismatch between simulations and motivating use-cases and contexts, 3) definitions that conflate protecting the system with protecting its users, 4) interventions that target isolated stages of the lifecycle while neglecting upstream and downstream effects, 5) and a lack of multi-stakeholder alignment where multiple fairness definitions can be relevant at once. Building on these insights, we propose a harm centered framework that links fairness definitions to concrete risks and stakeholder vulnerabilities. We conclude with recommendations for more holistic, context-aware, and accountable fairness research in FL.
Beyond the Safety Bundle: Auditing the Helpful and Harmless Dataset
Nov 12, 2024In an effort to mitigate the harms of large language models (LLMs), learning from human feedback (LHF) has been used to steer LLMs towards outputs that are intended to be both less harmful and more helpful. Despite the widespread adoption of LHF in practice, the quality of this feedback and its effectiveness as a safety mitigation technique remain unclear. This study addresses these issues by auditing the widely-used Helpful and Harmless (HH) dataset by Anthropic. Our work includes: (1) a thorough investigation of the dataset's content through both manual and automated evaluation; (2) experiments demonstrating the dataset's impact on models' safety; and (3) an analysis of the 100 most influential papers citing this dataset. Through our audit, we showcase how conceptualization failures and quality issues identified in the HH dataset can create additional harms by leading to disparate safety behaviors across demographic groups. Our findings highlight the need for more nuanced, context-sensitive approaches to safety mitigation in LLMs.
From Representational Harms to Quality-of-Service Harms: A Case Study on Llama 2 Safety Safeguards
Mar 21, 2024



Recent progress in large language models (LLMs) has led to their widespread adoption in various domains. However, these advancements have also introduced additional safety risks and raised concerns regarding their detrimental impact on already marginalized populations. Despite growing mitigation efforts to develop safety safeguards, such as supervised safety-oriented fine-tuning and leveraging safe reinforcement learning from human feedback, multiple concerns regarding the safety and ingrained biases in these models remain. Furthermore, previous work has demonstrated that models optimized for safety often display exaggerated safety behaviors, such as a tendency to refrain from responding to certain requests as a precautionary measure. As such, a clear trade-off between the helpfulness and safety of these models has been documented in the literature. In this paper, we further investigate the effectiveness of safety measures by evaluating models on already mitigated biases. Using the case of Llama 2 as an example, we illustrate how LLMs' safety responses can still encode harmful assumptions. To do so, we create a set of non-toxic prompts, which we then use to evaluate Llama models. Through our new taxonomy of LLMs responses to users, we observe that the safety/helpfulness trade-offs are more pronounced for certain demographic groups which can lead to quality-of-service harms for marginalized populations.