 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroken Chains: The Cost of Incomplete Reasoning in LLMs
Feb 16, 2026Reasoning-specialized models like OpenAI's 5.1 and DeepSeek-V3.2 allocate substantial inference compute to extended chain-of-thought (CoT) traces, yet reasoning tokens incur significant costs. How do different reasoning modalities of code, natural language, hybrid, or none do perform under token constraints? We introduce a framework that constrains models to reason exclusively through code, comments, both, or neither, then systematically ablates token budgets to 10\%, 30\%, 50\%, and 70\% of optimal. We evaluate four frontier models (GPT-5.1, Gemini 3 Flash, DeepSeek-V3.2, Grok 4.1) across mathematical benchmarks (AIME, GSM8K, HMMT). Our findings reveal: (1) \textbf{truncated reasoning can hurt} as DeepSeek-V3.2 achieves 53\% with no reasoning but only 17\% with truncated CoT at 50\% budget; (2) \textbf{code degrades gracefully} as Gemini's comments collapse to 0\% while code maintains 43-47\%; (3) \textbf{hybrid reasoning underperforms} single modalities; (4) \textbf{robustness is model-dependent} as Grok maintains 80-90\% at 30\% budget where OpenAI and DeepSeek collapse to 7-27\%. These results suggest incomplete reasoning chains actively mislead models, with implications for deploying reasoning-specialized systems under resource constraints.
Beyond the Safety Bundle: Auditing the Helpful and Harmless Dataset
Nov 12, 2024In an effort to mitigate the harms of large language models (LLMs), learning from human feedback (LHF) has been used to steer LLMs towards outputs that are intended to be both less harmful and more helpful. Despite the widespread adoption of LHF in practice, the quality of this feedback and its effectiveness as a safety mitigation technique remain unclear. This study addresses these issues by auditing the widely-used Helpful and Harmless (HH) dataset by Anthropic. Our work includes: (1) a thorough investigation of the dataset's content through both manual and automated evaluation; (2) experiments demonstrating the dataset's impact on models' safety; and (3) an analysis of the 100 most influential papers citing this dataset. Through our audit, we showcase how conceptualization failures and quality issues identified in the HH dataset can create additional harms by leading to disparate safety behaviors across demographic groups. Our findings highlight the need for more nuanced, context-sensitive approaches to safety mitigation in LLMs.
Combining Domain and Alignment Vectors to Achieve Better Knowledge-Safety Trade-offs in LLMs
Nov 11, 2024



There is a growing interest in training domain-expert LLMs that excel in specific technical fields compared to their general-purpose instruction-tuned counterparts. However, these expert models often experience a loss in their safety abilities in the process, making them capable of generating harmful content. As a solution, we introduce an efficient and effective merging-based alignment method called \textsc{MergeAlign} that interpolates the domain and alignment vectors, creating safer domain-specific models while preserving their utility. We apply \textsc{MergeAlign} on Llama3 variants that are experts in medicine and finance, obtaining substantial alignment improvements with minimal to no degradation on domain-specific benchmarks. We study the impact of model merging through model similarity metrics and contributions of individual models being merged. We hope our findings open new research avenues and inspire more efficient development of safe expert LLMs.
Trust No Bot: Discovering Personal Disclosures in Human-LLM Conversations in the Wild
Jul 16, 2024

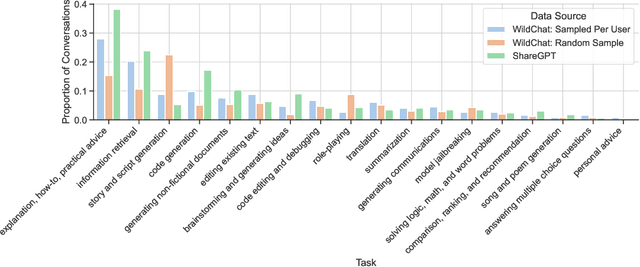

Measuring personal disclosures made in human-chatbot interactions can provide a better understanding of users' AI literacy and facilitate privacy research for large language models (LLMs). We run an extensive, fine-grained analysis on the personal disclosures made by real users to commercial GPT models, investigating the leakage of personally identifiable and sensitive information. To understand the contexts in which users disclose to chatbots, we develop a taxonomy of tasks and sensitive topics, based on qualitative and quantitative analysis of naturally occurring conversations. We discuss these potential privacy harms and observe that: (1) personally identifiable information (PII) appears in unexpected contexts such as in translation or code editing (48% and 16% of the time, respectively) and (2) PII detection alone is insufficient to capture the sensitive topics that are common in human-chatbot interactions, such as detailed sexual preferences or specific drug use habits. We believe that these high disclosure rates are of significant importance for researchers and data curators, and we call for the design of appropriate nudging mechanisms to help users moderate their interactions.
Towards More Realistic Extraction Attacks: An Adversarial Perspective
Jul 02, 2024Language models are prone to memorizing large parts of their training data, making them vulnerable to extraction attacks. Existing research on these attacks remains limited in scope, often studying isolated trends rather than the real-world interactions with these models. In this paper, we revisit extraction attacks from an adversarial perspective, exploiting the brittleness of language models. We find significant churn in extraction attack trends, i.e., even minor, unintuitive changes to the prompt, or targeting smaller models and older checkpoints, can exacerbate the risks of extraction by up to $2-4 \times$. Moreover, relying solely on the widely accepted verbatim match underestimates the extent of extracted information, and we provide various alternatives to more accurately capture the true risks of extraction. We conclude our discussion with data deduplication, a commonly suggested mitigation strategy, and find that while it addresses some memorization concerns, it remains vulnerable to the same escalation of extraction risks against a real-world adversary. Our findings highlight the necessity of acknowledging an adversary's true capabilities to avoid underestimating extraction risks.
Efficient Causal Graph Discovery Using Large Language Models
Feb 05, 2024



We propose a novel framework that leverages LLMs for full causal graph discovery. While previous LLM-based methods have used a pairwise query approach, this requires a quadratic number of queries which quickly becomes impractical for larger causal graphs. In contrast, the proposed framework uses a breadth-first search (BFS) approach which allows it to use only a linear number of queries. We also show that the proposed method can easily incorporate observational data when available, to improve performance. In addition to being more time and data-efficient, the proposed framework achieves state-of-the-art results on real-world causal graphs of varying sizes. The results demonstrate the effectiveness and efficiency of the proposed method in discovering causal relationships, showcasing its potential for broad applicability in causal graph discovery tasks across different domains.
Scotch: An Efficient Secure Computation Framework for Secure Aggregation
Jan 19, 2022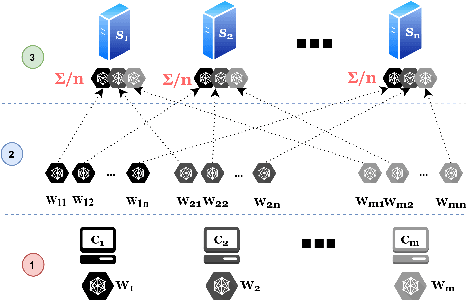


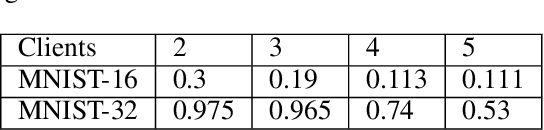
Federated learning enables multiple data owners to jointly train a machine learning model without revealing their private datasets. However, a malicious aggregation server might use the model parameters to derive sensitive information about the training dataset used. To address such leakage, differential privacy and cryptographic techniques have been investigated in prior work, but these often result in large communication overheads or impact model performance. To mitigate this centralization of power, we propose \textsc{Scotch}, a decentralized \textit{m-party} secure-computation framework for federated aggregation that deploys MPC primitives, such as \textit{secret sharing}. Our protocol is simple, efficient, and provides strict privacy guarantees against curious aggregators or colluding data-owners with minimal communication overheads compared to other existing \textit{state-of-the-art} privacy-preserving federated learning frameworks. We evaluate our framework by performing extensive experiments on multiple datasets with promising results. \textsc{Scotch} can train the standard MLP NN with the training dataset split amongst 3 participating users and 3 aggregating servers with 96.57\% accuracy on MNIST, and 98.40\% accuracy on the Extended MNIST (digits) dataset, while providing various optimizations.