 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPeP: Benchmarking Continual Pretraining for Protein Language Models
Mar 03, 2026Protein language models (pLMs) have recently gained significant attention for their ability to uncover relationships between sequence, structure, and function from evolutionary statistics, thereby accelerating therapeutic drug discovery. These models learn from large protein databases that are continuously updated by the biology community and whose dynamic nature motivates the application of continual learning, not only to keep up with the ever-growing data, but also as an opportunity to take advantage of the temporal meta-information that is created during this process. As a result, we introduce the Continual Pretraining of Protein Language Models (CoPeP) benchmark, a novel benchmark for evaluating continual learning approaches on pLMs. Specifically, we curate a sequence of protein datasets derived from the UniProt Knowledgebase spanning a decade and define metrics to assess pLM performance across 31 protein understanding tasks. We evaluate several methods from the continual learning literature, including replay, unlearning, and plasticity-based methods, some of which have never been applied to models and data of this scale. Our findings reveal that incorporating temporal meta-information improves perplexity by up to 7% even when compared to training on data from all tasks jointly. Moreover, even at scale, several continual learning methods outperform naive continual pretraining. The CoPeP benchmark offers an exciting opportunity to study these methods at scale in an impactful real-world application.
Structure-Aligned Protein Language Model
May 22, 2025Protein language models (pLMs) pre-trained on vast protein sequence databases excel at various downstream tasks but lack the structural knowledge essential for many biological applications. To address this, we integrate structural insights from pre-trained protein graph neural networks (pGNNs) into pLMs through a latent-level contrastive learning task. This task aligns residue representations from pLMs with those from pGNNs across multiple proteins, enriching pLMs with inter-protein structural knowledge. Additionally, we incorporate a physical-level task that infuses intra-protein structural knowledge by optimizing pLMs to predict structural tokens. The proposed dual-task framework effectively incorporates both inter-protein and intra-protein structural knowledge into pLMs. Given the variability in the quality of protein structures in PDB, we further introduce a residue loss selection module, which uses a small model trained on high-quality structures to select reliable yet challenging residue losses for the pLM to learn. Applying our structure alignment method to the state-of-the-art ESM2 and AMPLIFY results in notable performance gains across a wide range of tasks, including a 12.7% increase in ESM2 contact prediction. The data, code, and resulting SaESM2 and SaAMPLIFY models will be released on Hugging Face.
NeoBERT: A Next-Generation BERT
Feb 26, 2025
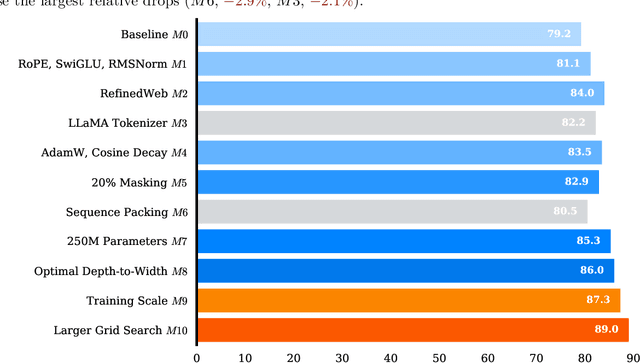


Recent innovations in architecture, pre-training, and fine-tuning have led to the remarkable in-context learning and reasoning abilities of large auto-regressive language models such as LLaMA and DeepSeek. In contrast, encoders like BERT and RoBERTa have not seen the same level of progress despite being foundational for many downstream NLP applications. To bridge this gap, we introduce NeoBERT, a next-generation encoder that redefines the capabilities of bidirectional models by integrating state-of-the-art advancements in architecture, modern data, and optimized pre-training methodologies. NeoBERT is designed for seamless adoption: it serves as a plug-and-play replacement for existing base models, relies on an optimal depth-to-width ratio, and leverages an extended context length of 4,096 tokens. Despite its compact 250M parameter footprint, it achieves state-of-the-art results on the massive MTEB benchmark, outperforming BERT large, RoBERTa large, NomicBERT, and ModernBERT under identical fine-tuning conditions. In addition, we rigorously evaluate the impact of each modification on GLUE and design a uniform fine-tuning and evaluation framework for MTEB. We release all code, data, checkpoints, and training scripts to accelerate research and real-world adoption.
Combining Domain and Alignment Vectors to Achieve Better Knowledge-Safety Trade-offs in LLMs
Nov 11, 2024



There is a growing interest in training domain-expert LLMs that excel in specific technical fields compared to their general-purpose instruction-tuned counterparts. However, these expert models often experience a loss in their safety abilities in the process, making them capable of generating harmful content. As a solution, we introduce an efficient and effective merging-based alignment method called \textsc{MergeAlign} that interpolates the domain and alignment vectors, creating safer domain-specific models while preserving their utility. We apply \textsc{MergeAlign} on Llama3 variants that are experts in medicine and finance, obtaining substantial alignment improvements with minimal to no degradation on domain-specific benchmarks. We study the impact of model merging through model similarity metrics and contributions of individual models being merged. We hope our findings open new research avenues and inspire more efficient development of safe expert LLMs.
Exploring Quantization for Efficient Pre-Training of Transformer Language Models
Jul 16, 2024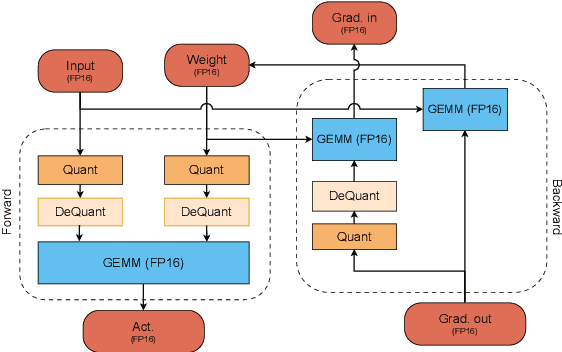

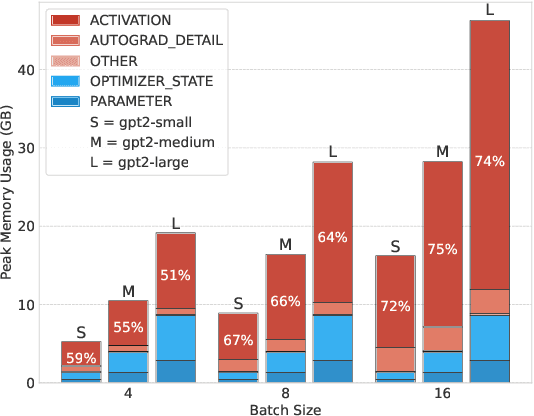

The increasing scale of Transformer models has led to an increase in their pre-training computational requirements. While quantization has proven to be effective after pre-training and during fine-tuning, applying quantization in Transformers during pre-training has remained largely unexplored at scale for language modeling. This study aims to explore the impact of quantization for efficient pre-training of Transformers, with a focus on linear layer components. By systematically applying straightforward linear quantization to weights, activations, gradients, and optimizer states, we assess its effects on model efficiency, stability, and performance during training. By offering a comprehensive recipe of effective quantization strategies to be applied during the pre-training of Transformers, we promote high training efficiency from scratch while retaining language modeling ability. Code is available at https://github.com/chandar-lab/EfficientLLMs.
A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques
Jun 07, 2024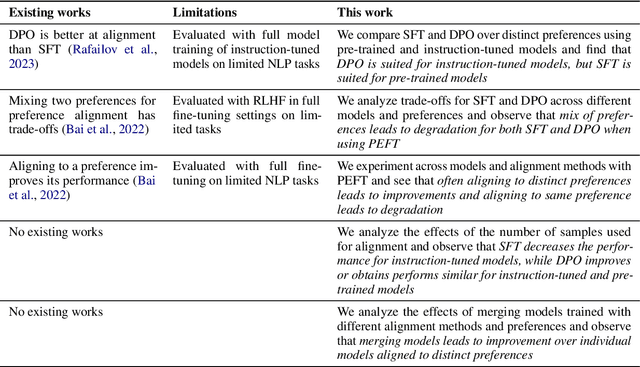
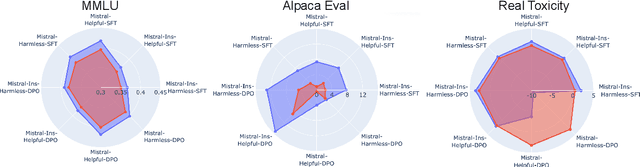
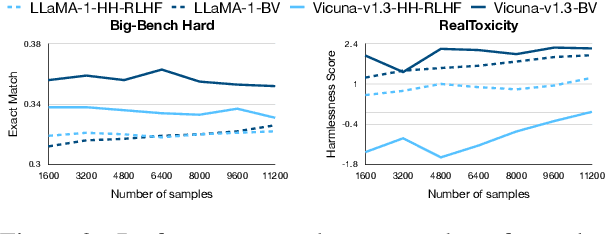
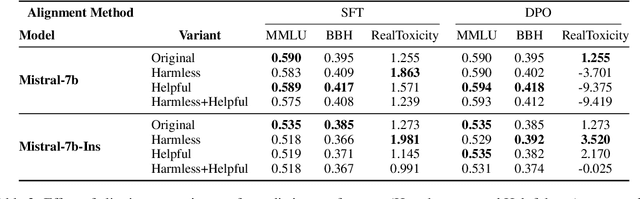
Large language models are first pre-trained on trillions of tokens and then instruction-tuned or aligned to specific preferences. While pre-training remains out of reach for most researchers due to the compute required, fine-tuning has become affordable thanks to parameter-efficient methods such as LoRA and QLoRA. Alignment is known to be sensitive to the many factors involved, including the quantity and quality of data, the alignment method, and the adapter rank. However, there has not yet been an extensive study of their effect on downstream performance. To address this gap, we conduct an in-depth investigation of the impact of popular choices for three crucial axes: (i) the alignment dataset (HH-RLHF and BeaverTails), (ii) the alignment technique (SFT and DPO), and (iii) the model (LLaMA-1, Vicuna-v1.3, Mistral-7b, and Mistral-7b-Instruct). Our extensive setup spanning over 300 experiments reveals consistent trends and unexpected findings. We observe how more informative data helps with preference alignment, cases where supervised fine-tuning outperforms preference optimization, and how aligning to a distinct preference boosts performance on downstream tasks. Through our in-depth analyses, we put forward key guidelines to help researchers perform more effective parameter-efficient LLM alignment.
Predicting the Impact of Model Expansion through the Minima Manifold: A Loss Landscape Perspective
May 24, 2024



The optimal model for a given task is often challenging to determine, requiring training multiple models from scratch which becomes prohibitive as dataset and model sizes grow. A more efficient alternative is to reuse smaller pre-trained models by expanding them, however, this is not widely adopted as how this impacts training dynamics remains poorly understood. While prior works have introduced statistics to measure these effects, they remain flawed. To rectify this, we offer a new approach for understanding and quantifying the impact of expansion through the lens of the loss landscape, which has been shown to contain a manifold of linearly connected minima. Building on this new perspective, we propose a metric to study the impact of expansion by estimating the size of the manifold. Experimental results show a clear relationship between gains in performance and manifold size, enabling the comparison of candidate models and presenting a first step towards expanding models more reliably based on geometric properties of the loss landscape.
Language Models for Novelty Detection in System Call Traces
Sep 05, 2023

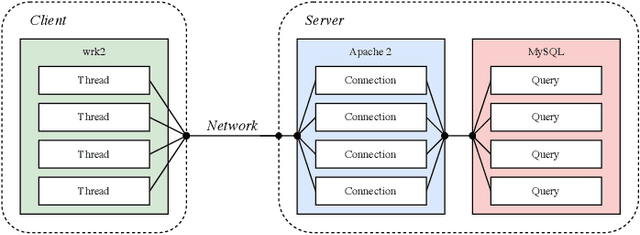

Due to the complexity of modern computer systems, novel and unexpected behaviors frequently occur. Such deviations are either normal occurrences, such as software updates and new user activities, or abnormalities, such as misconfigurations, latency issues, intrusions, and software bugs. Regardless, novel behaviors are of great interest to developers, and there is a genuine need for efficient and effective methods to detect them. Nowadays, researchers consider system calls to be the most fine-grained and accurate source of information to investigate the behavior of computer systems. Accordingly, this paper introduces a novelty detection methodology that relies on a probability distribution over sequences of system calls, which can be seen as a language model. Language models estimate the likelihood of sequences, and since novelties deviate from previously observed behaviors by definition, they would be unlikely under the model. Following the success of neural networks for language models, three architectures are evaluated in this work: the widespread LSTM, the state-of-the-art Transformer, and the lower-complexity Longformer. However, large neural networks typically require an enormous amount of data to be trained effectively, and to the best of our knowledge, no massive modern datasets of kernel traces are publicly available. This paper addresses this limitation by introducing a new open-source dataset of kernel traces comprising over 2 million web requests with seven distinct behaviors. The proposed methodology requires minimal expert hand-crafting and achieves an F-score and AuROC greater than 95% on most novelties while being data- and task-agnostic. The source code and trained models are publicly available on GitHub while the datasets are available on Zenodo.
A Practical Survey on Faster and Lighter Transformers
Mar 26, 2021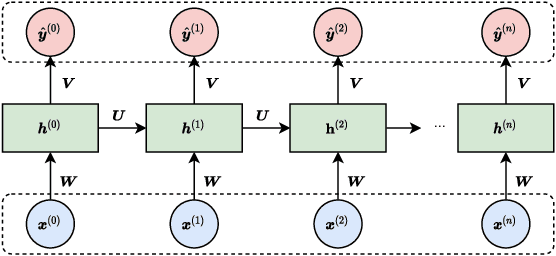
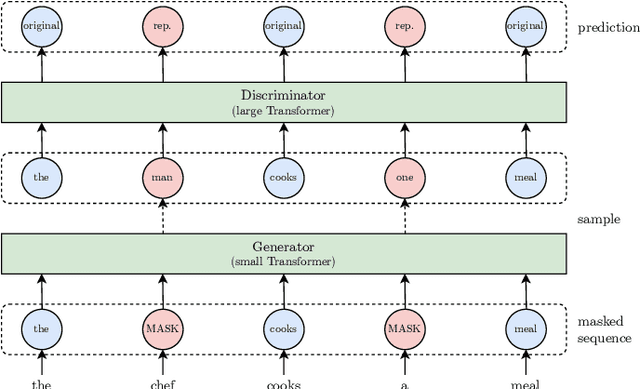
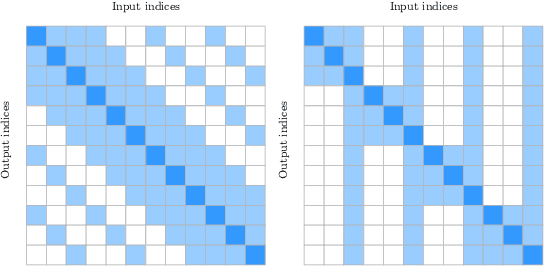
Recurrent neural networks are effective models to process sequences. However, they are unable to learn long-term dependencies because of their inherent sequential nature. As a solution, Vaswani et al. introduced the Transformer, a model solely based on the attention mechanism that is able to relate any two positions of the input sequence, hence modelling arbitrary long dependencies. The Transformer has improved the state-of-the-art across numerous sequence modelling tasks. However, its effectiveness comes at the expense of a quadratic computational and memory complexity with respect to the sequence length, hindering its adoption. Fortunately, the deep learning community has always been interested in improving the models' efficiency, leading to a plethora of solutions such as parameter sharing, pruning, mixed-precision, and knowledge distillation. Recently, researchers have directly addressed the Transformer's limitation by designing lower-complexity alternatives such as the Longformer, Reformer, Linformer, and Performer. However, due to the wide range of solutions, it has become challenging for the deep learning community to determine which methods to apply in practice to meet the desired trade-off between capacity, computation, and memory. This survey addresses this issue by investigating popular approaches to make the Transformer faster and lighter and by providing a comprehensive explanation of the methods' strengths, limitations, and underlying assumptions.
On Improving Deep Learning Trace Analysis with System Call Arguments
Mar 11, 2021Kernel traces are sequences of low-level events comprising a name and multiple arguments, including a timestamp, a process id, and a return value, depending on the event. Their analysis helps uncover intrusions, identify bugs, and find latency causes. However, their effectiveness is hindered by omitting the event arguments. To remedy this limitation, we introduce a general approach to learning a representation of the event names along with their arguments using both embedding and encoding. The proposed method is readily applicable to most neural networks and is task-agnostic. The benefit is quantified by conducting an ablation study on three groups of arguments: call-related, process-related, and time-related. Experiments were conducted on a novel web request dataset and validated on a second dataset collected on pre-production servers by Ciena, our partnering company. By leveraging additional information, we were able to increase the performance of two widely-used neural networks, an LSTM and a Transformer, by up to 11.3% on two unsupervised language modelling tasks. Such tasks may be used to detect anomalies, pre-train neural networks to improve their performance, and extract a contextual representation of the events.