 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA column generation algorithm with dynamic constraint aggregation for minimum sum-of-squares clustering
Oct 08, 2024The minimum sum-of-squares clustering problem (MSSC), also known as $k$-means clustering, refers to the problem of partitioning $n$ data points into $k$ clusters, with the objective of minimizing the total sum of squared Euclidean distances between each point and the center of its assigned cluster. We propose an efficient algorithm for solving large-scale MSSC instances, which combines column generation (CG) with dynamic constraint aggregation (DCA) to effectively reduce the number of constraints considered in the CG master problem. DCA was originally conceived to reduce degeneracy in set partitioning problems by utilizing an aggregated restricted master problem obtained from a partition of the set partitioning constraints into disjoint clusters. In this work, we explore the use of DCA within a CG algorithm for MSSC exact solution. Our method is fine-tuned by a series of ablation studies on DCA design choices, and is demonstrated to significantly outperform existing state-of-the-art exact approaches available in the literature.
Language Models for Novelty Detection in System Call Traces
Sep 05, 2023

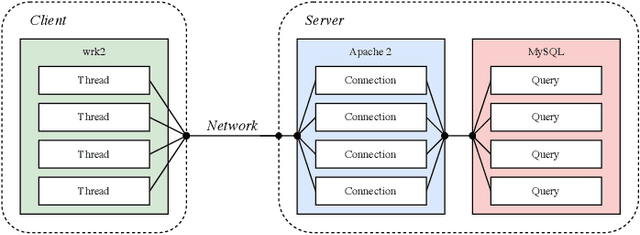

Due to the complexity of modern computer systems, novel and unexpected behaviors frequently occur. Such deviations are either normal occurrences, such as software updates and new user activities, or abnormalities, such as misconfigurations, latency issues, intrusions, and software bugs. Regardless, novel behaviors are of great interest to developers, and there is a genuine need for efficient and effective methods to detect them. Nowadays, researchers consider system calls to be the most fine-grained and accurate source of information to investigate the behavior of computer systems. Accordingly, this paper introduces a novelty detection methodology that relies on a probability distribution over sequences of system calls, which can be seen as a language model. Language models estimate the likelihood of sequences, and since novelties deviate from previously observed behaviors by definition, they would be unlikely under the model. Following the success of neural networks for language models, three architectures are evaluated in this work: the widespread LSTM, the state-of-the-art Transformer, and the lower-complexity Longformer. However, large neural networks typically require an enormous amount of data to be trained effectively, and to the best of our knowledge, no massive modern datasets of kernel traces are publicly available. This paper addresses this limitation by introducing a new open-source dataset of kernel traces comprising over 2 million web requests with seven distinct behaviors. The proposed methodology requires minimal expert hand-crafting and achieves an F-score and AuROC greater than 95% on most novelties while being data- and task-agnostic. The source code and trained models are publicly available on GitHub while the datasets are available on Zenodo.
Soft Attention: Does it Actually Help to Learn Social Interactions in Pedestrian Trajectory Prediction?
Jun 16, 2021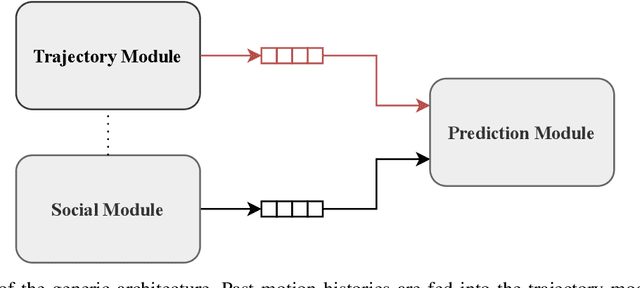

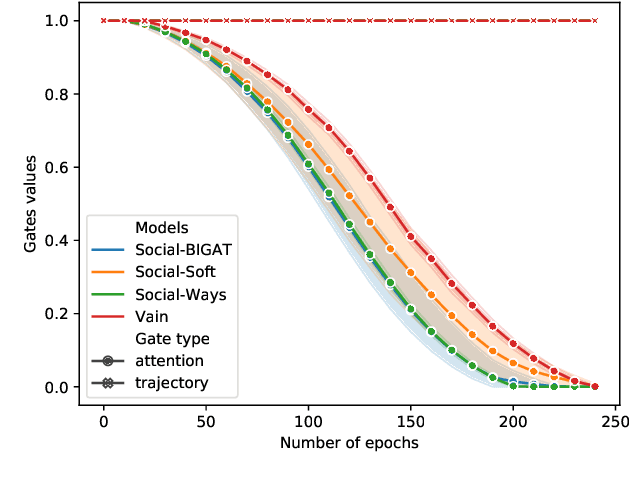
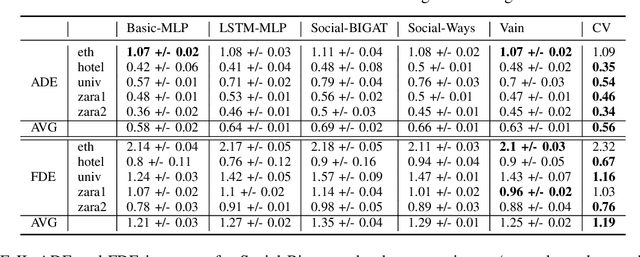
We consider the problem of predicting the future path of a pedestrian using its motion history and the motion history of the surrounding pedestrians, called social information. Since the seminal paper on Social-LSTM, deep-learning has become the main tool used to model the impact of social interactions on a pedestrian's motion. The demonstration that these models can learn social interactions relies on an ablative study of these models. The models are compared with and without their social interactions module on two standard metrics, the Average Displacement Error and Final Displacement Error. Yet, these complex models were recently outperformed by a simple constant-velocity approach. This questions if they actually allow to model social interactions as well as the validity of the proof. In this paper, we focus on the deep-learning models with a soft-attention mechanism for social interaction modeling and study whether they use social information at prediction time. We conduct two experiments across four state-of-the-art approaches on the ETH and UCY datasets, which were also used in previous work. First, the models are trained by replacing the social information with random noise and compared to model trained with actual social information. Second, we use a gating mechanism along with a $L_0$ penalty, allowing models to shut down their inner components. The models consistently learn to prune their soft-attention mechanism. For both experiments, neither the course of the convergence nor the prediction performance were altered. This demonstrates that the soft-attention mechanism and therefore the social information are ignored by the models.
Exploring dual information in distance metric learning for clustering
May 26, 2021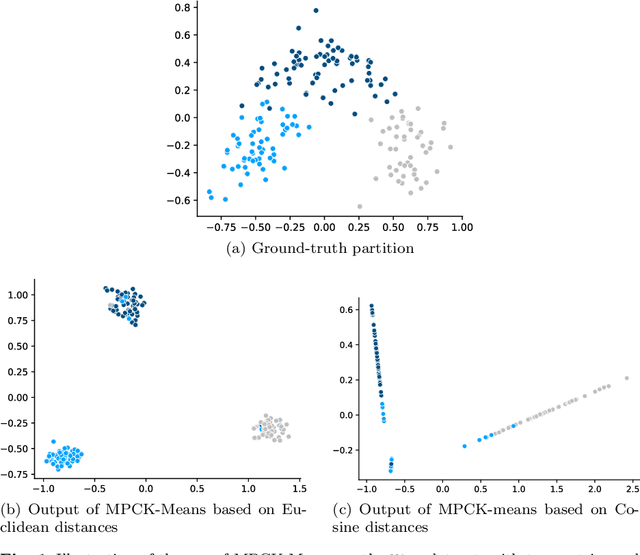

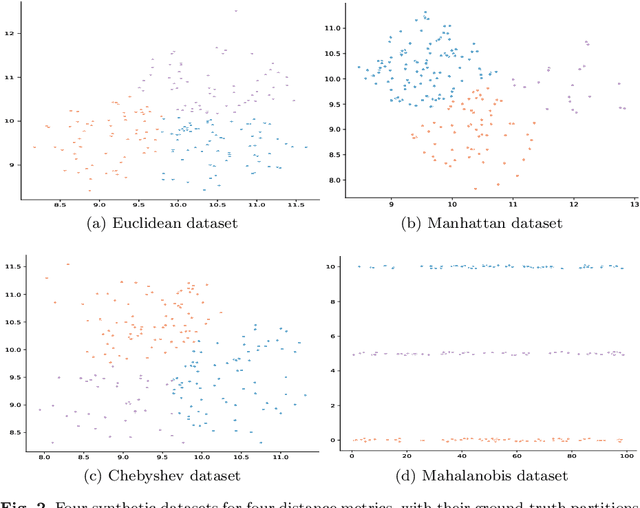

Distance metric learning algorithms aim to appropriately measure similarities and distances between data points. In the context of clustering, metric learning is typically applied with the assist of side-information provided by experts, most commonly expressed in the form of cannot-link and must-link constraints. In this setting, distance metric learning algorithms move closer pairs of data points involved in must-link constraints, while pairs of points involved in cannot-link constraints are moved away from each other. For these algorithms to be effective, it is important to use a distance metric that matches the expert knowledge, beliefs, and expectations, and the transformations made to stick to the side-information should preserve geometrical properties of the dataset. Also, it is interesting to filter the constraints provided by the experts to keep only the most useful and reject those that can harm the clustering process. To address these issues, we propose to exploit the dual information associated with the pairwise constraints of the semi-supervised clustering problem. Experiments clearly show that distance metric learning algorithms benefit from integrating this dual information.
A Practical Survey on Faster and Lighter Transformers
Mar 26, 2021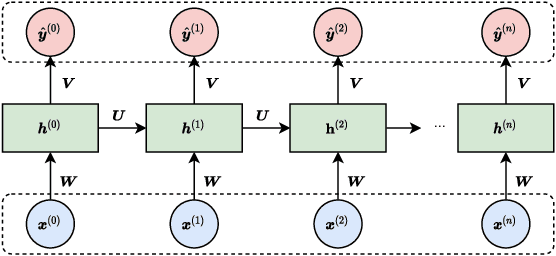
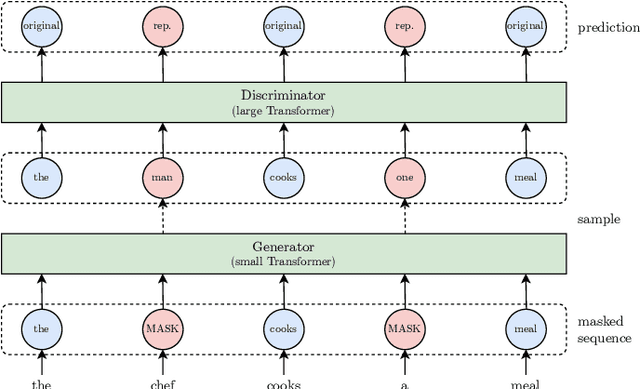
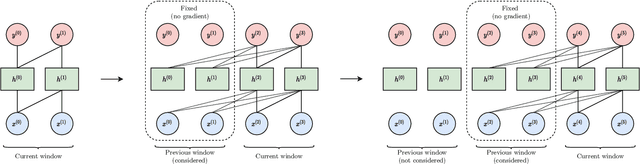
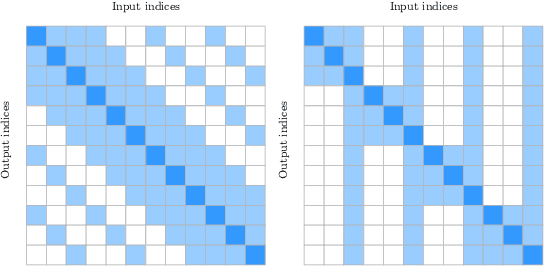
Recurrent neural networks are effective models to process sequences. However, they are unable to learn long-term dependencies because of their inherent sequential nature. As a solution, Vaswani et al. introduced the Transformer, a model solely based on the attention mechanism that is able to relate any two positions of the input sequence, hence modelling arbitrary long dependencies. The Transformer has improved the state-of-the-art across numerous sequence modelling tasks. However, its effectiveness comes at the expense of a quadratic computational and memory complexity with respect to the sequence length, hindering its adoption. Fortunately, the deep learning community has always been interested in improving the models' efficiency, leading to a plethora of solutions such as parameter sharing, pruning, mixed-precision, and knowledge distillation. Recently, researchers have directly addressed the Transformer's limitation by designing lower-complexity alternatives such as the Longformer, Reformer, Linformer, and Performer. However, due to the wide range of solutions, it has become challenging for the deep learning community to determine which methods to apply in practice to meet the desired trade-off between capacity, computation, and memory. This survey addresses this issue by investigating popular approaches to make the Transformer faster and lighter and by providing a comprehensive explanation of the methods' strengths, limitations, and underlying assumptions.
Heuristics for optimizing 3D mapping missions over swarm-powered ad hoc clouds
Mar 11, 2021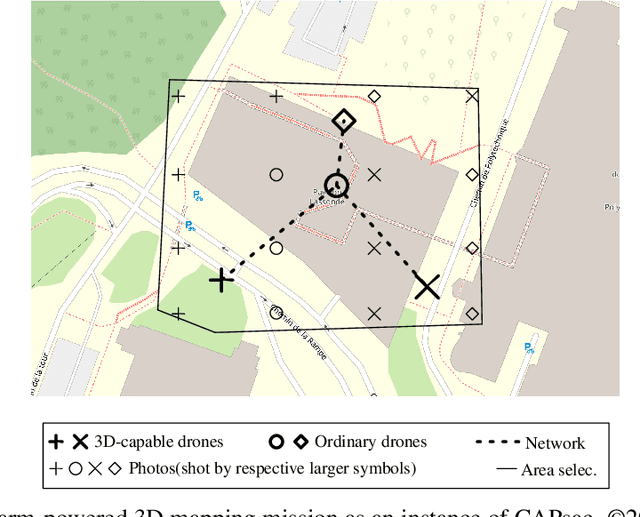



Drones have been getting more and more popular in many economy sectors. Both scientific and industrial communities aim at making the impact of drones even more disruptive by empowering collaborative autonomous behaviors -- also known as swarming behaviors -- within fleets of multiple drones. In swarming-powered 3D mapping missions, unmanned aerial vehicles typically collect the aerial pictures of the target area whereas the 3D reconstruction process is performed in a centralized manner. However, such approaches do not leverage computational and storage resources from the swarm members.We address the optimization of a swarm-powered distributed 3D mapping mission for a real-life humanitarian emergency response application through the exploitation of a swarm-powered ad hoc cloud. Producing the relevant 3D maps in a timely manner, even when the cloud connectivity is not available, is crucial to increase the chances of success of the operation. In this work, we present a mathematical programming heuristic based on decomposition and a variable neighborhood search heuristic to minimize the completion time of the 3D reconstruction process necessary in such missions. Our computational results reveal that the proposed heuristics either quickly reach optimality or improve the best known solutions for almost all tested realistic instances comprising up to 1000 images and fifteen drones.
On Improving Deep Learning Trace Analysis with System Call Arguments
Mar 11, 2021Kernel traces are sequences of low-level events comprising a name and multiple arguments, including a timestamp, a process id, and a return value, depending on the event. Their analysis helps uncover intrusions, identify bugs, and find latency causes. However, their effectiveness is hindered by omitting the event arguments. To remedy this limitation, we introduce a general approach to learning a representation of the event names along with their arguments using both embedding and encoding. The proposed method is readily applicable to most neural networks and is task-agnostic. The benefit is quantified by conducting an ablation study on three groups of arguments: call-related, process-related, and time-related. Experiments were conducted on a novel web request dataset and validated on a second dataset collected on pre-production servers by Ciena, our partnering company. By leveraging additional information, we were able to increase the performance of two widely-used neural networks, an LSTM and a Transformer, by up to 11.3% on two unsupervised language modelling tasks. Such tasks may be used to detect anomalies, pre-train neural networks to improve their performance, and extract a contextual representation of the events.
Automatic Cause Detection of Performance Problems in Web Applications
Mar 08, 2021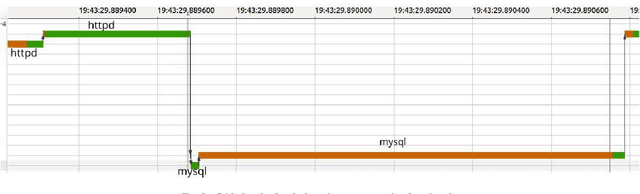
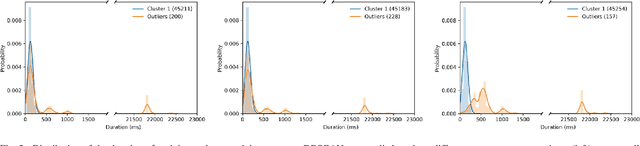
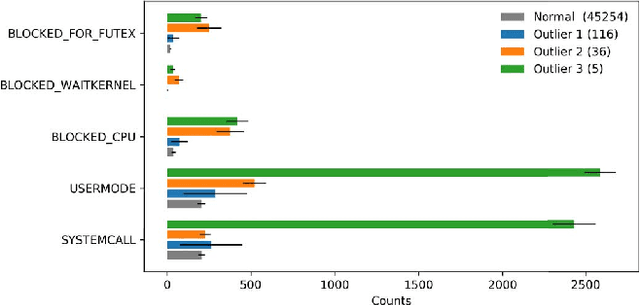
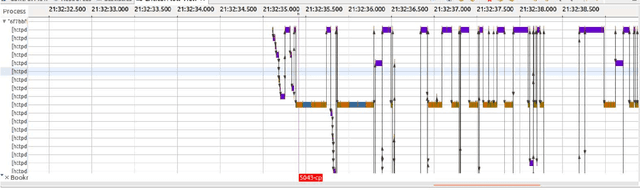
The execution of similar units can be compared by their internal behaviors to determine the causes of their potential performance issues. For instance, by examining the internal behaviors of different fast or slow web requests more closely and by clustering and comparing their internal executions, one can determine what causes some requests to run slowly or behave in unexpected ways. In this paper, we propose a method of extracting the internal behavior of web requests as well as introduce a pipeline that detects performance issues in web requests and provides insights into their root causes. First, low-level and fine-grained information regarding each request is gathered by tracing both the user space and the kernel space. Second, further information is extracted and fed into an outlier detector. Finally, these outliers are then clustered by their behavior, and each group is analyzed separately. Experiments revealed that this pipeline is indeed able to detect slow web requests and provide additional insights into their true root causes. Notably, we were able to identify a real PHP cache contention using the proposed approach.
* 8 pages, 7 figures, IEEE ISSREW 2019
Empirical comparison between autoencoders and traditional dimensionality reduction methods
Mar 08, 2021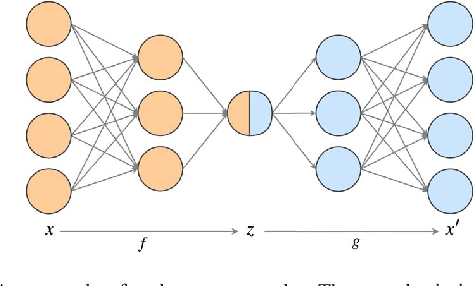
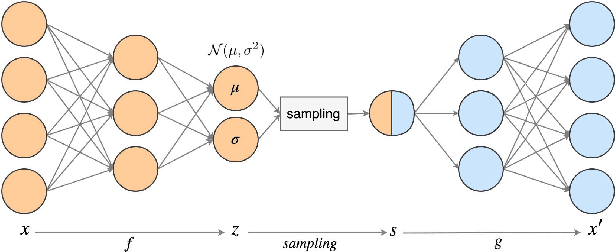
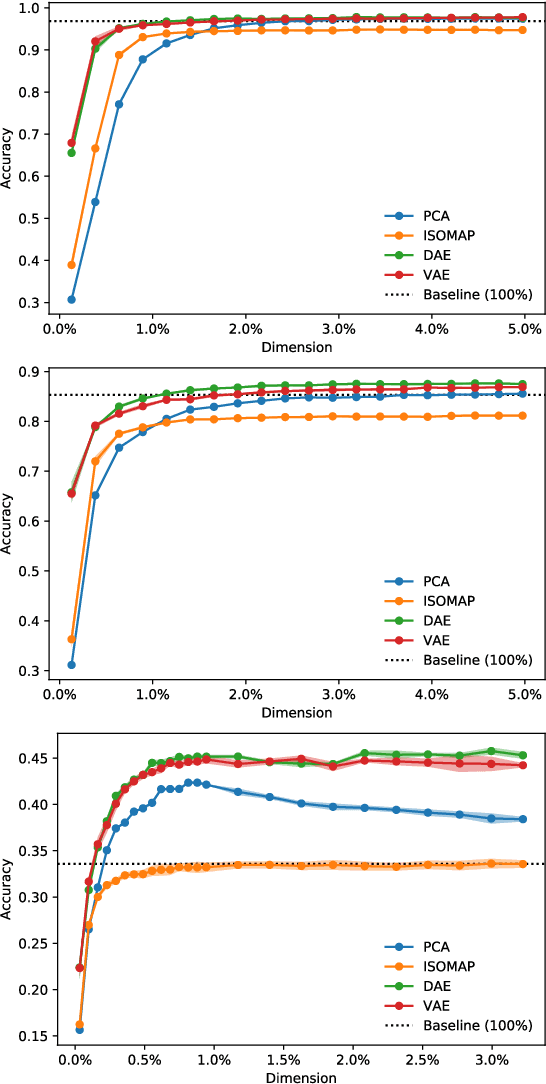
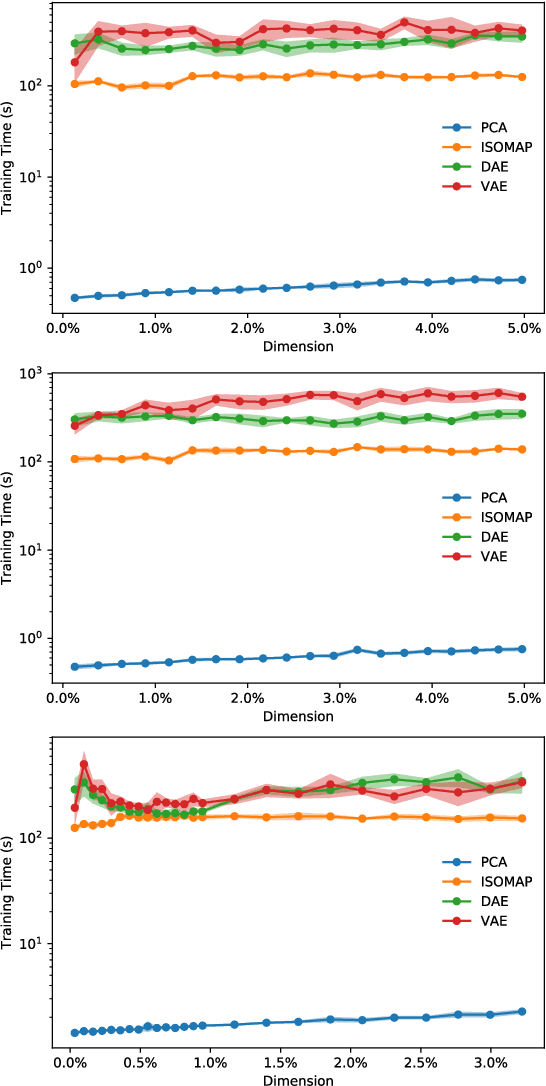
In order to process efficiently ever-higher dimensional data such as images, sentences, or audio recordings, one needs to find a proper way to reduce the dimensionality of such data. In this regard, SVD-based methods including PCA and Isomap have been extensively used. Recently, a neural network alternative called autoencoder has been proposed and is often preferred for its higher flexibility. This work aims to show that PCA is still a relevant technique for dimensionality reduction in the context of classification. To this purpose, we evaluated the performance of PCA compared to Isomap, a deep autoencoder, and a variational autoencoder. Experiments were conducted on three commonly used image datasets: MNIST, Fashion-MNIST, and CIFAR-10. The four different dimensionality reduction techniques were separately employed on each dataset to project data into a low-dimensional space. Then a k-NN classifier was trained on each projection with a cross-validated random search over the number of neighbours. Interestingly, our experiments revealed that k-NN achieved comparable accuracy on PCA and both autoencoders' projections provided a big enough dimension. However, PCA computation time was two orders of magnitude faster than its neural network counterparts.
* 4 pages, 4 figures, IEEE AIKE 2019