 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Logic Networks for Interpretable Classification
Aug 11, 2025Traditional neural networks have an impressive classification performance, but what they learn cannot be inspected, verified or extracted. Neural Logic Networks on the other hand have an interpretable structure that enables them to learn a logical mechanism relating the inputs and outputs with AND and OR operations. We generalize these networks with NOT operations and biases that take into account unobserved data and develop a rigorous logical and probabilistic modeling in terms of concept combinations to motivate their use. We also propose a novel factorized IF-THEN rule structure for the model as well as a modified learning algorithm. Our method improves the state-of-the-art in Boolean networks discovery and is able to learn relevant, interpretable rules in tabular classification, notably on an example from the medical field where interpretability has tangible value.
Addressing the cold start problem in privacy preserving content-based recommender systems using hypercube graphs
Oct 13, 2023



The initial interaction of a user with a recommender system is problematic because, in such a so-called cold start situation, the recommender system has very little information about the user, if any. Moreover, in collaborative filtering, users need to share their preferences with the service provider by rating items while in content-based filtering there is no need for such information sharing. We have recently shown that a content-based model that uses hypercube graphs can determine user preferences with a very limited number of ratings while better preserving user privacy. In this paper, we confirm these findings on the basis of experiments with more than 1,000 users in the restaurant and movie domains. We show that the proposed method outperforms standard machine learning algorithms when the number of available ratings is at most 10, which often happens, and is competitive with larger training sets. In addition, training is simple and does not require large computational efforts.
A machine learning framework for neighbor generation in metaheuristic search
Dec 22, 2022



This paper presents a methodology for integrating machine learning techniques into metaheuristics for solving combinatorial optimization problems. Namely, we propose a general machine learning framework for neighbor generation in metaheuristic search. We first define an efficient neighborhood structure constructed by applying a transformation to a selected subset of variables from the current solution. Then, the key of the proposed methodology is to generate promising neighbors by selecting a proper subset of variables that contains a descent of the objective in the solution space. To learn a good variable selection strategy, we formulate the problem as a classification task that exploits structural information from the characteristics of the problem and from high-quality solutions. We validate our methodology on two metaheuristic applications: a Tabu Search scheme for solving a Wireless Network Optimization problem and a Large Neighborhood Search heuristic for solving Mixed-Integer Programs. The experimental results show that our approach is able to achieve a satisfactory trade-off between the exploration of a larger solution space and the exploitation of high-quality solution regions on both applications.
Exploring dual information in distance metric learning for clustering
May 26, 2021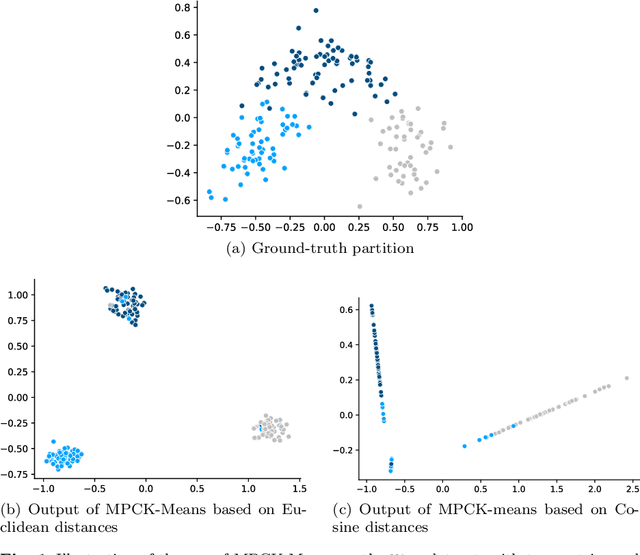

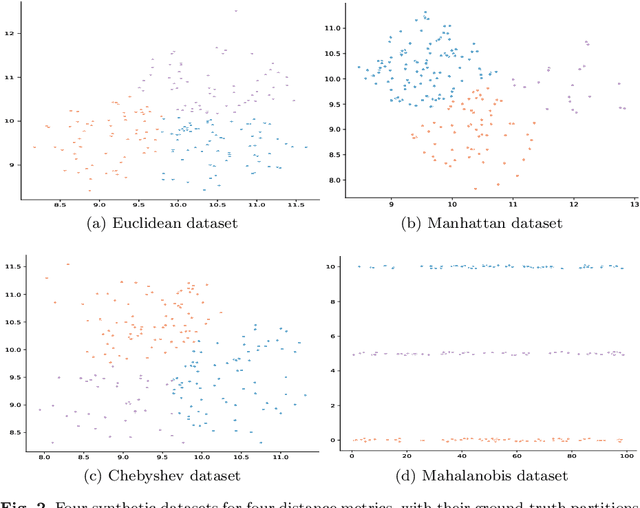

Distance metric learning algorithms aim to appropriately measure similarities and distances between data points. In the context of clustering, metric learning is typically applied with the assist of side-information provided by experts, most commonly expressed in the form of cannot-link and must-link constraints. In this setting, distance metric learning algorithms move closer pairs of data points involved in must-link constraints, while pairs of points involved in cannot-link constraints are moved away from each other. For these algorithms to be effective, it is important to use a distance metric that matches the expert knowledge, beliefs, and expectations, and the transformations made to stick to the side-information should preserve geometrical properties of the dataset. Also, it is interesting to filter the constraints provided by the experts to keep only the most useful and reject those that can harm the clustering process. To address these issues, we propose to exploit the dual information associated with the pairwise constraints of the semi-supervised clustering problem. Experiments clearly show that distance metric learning algorithms benefit from integrating this dual information.