 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Detection of Complex Quotation Patterns in Aggadic Literature
Dec 29, 2025This paper presents ACT (Allocate Connections between Texts), a novel three-stage algorithm for the automatic detection of biblical quotations in Rabbinic literature. Unlike existing text reuse frameworks that struggle with short, paraphrased, or structurally embedded quotations, ACT combines a morphology-aware alignment algorithm with a context-sensitive enrichment stage that identifies complex citation patterns such as "Wave" and "Echo" quotations. Our approach was evaluated against leading systems, including Dicta, Passim, Text-Matcher, as well as human-annotated critical editions. We further assessed three ACT configurations to isolate the contribution of each component. Results demonstrate that the full ACT pipeline (ACT-QE) outperforms all baselines, achieving an F1 score of 0.91, with superior Recall (0.89) and Precision (0.94). Notably, ACT-2, which lacks stylistic enrichment, achieves higher Recall (0.90) but suffers in Precision, while ACT-3, using longer n-grams, offers a tradeoff between coverage and specificity. In addition to improving quotation detection, ACT's ability to classify stylistic patterns across corpora opens new avenues for genre classification and intertextual analysis. This work contributes to digital humanities and computational philology by addressing the methodological gap between exhaustive machine-based detection and human editorial judgment. ACT lays a foundation for broader applications in historical textual analysis, especially in morphologically rich and citation-dense traditions like Aggadic literature.
Automatic Identification and Visualization of Group Training Activities Using Wearable Data
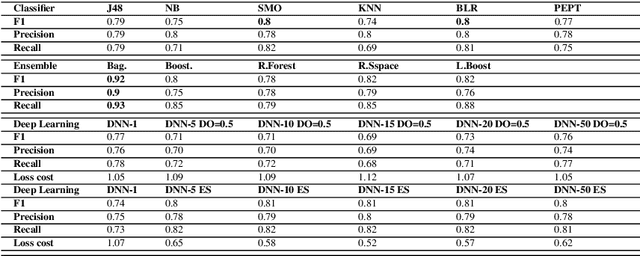
Oct 07, 2024Human Activity Recognition (HAR) identifies daily activities from time-series data collected by wearable devices like smartwatches. Recent advancements in Internet of Things (IoT), cloud computing, and low-cost sensors have broadened HAR applications across fields like healthcare, biometrics, sports, and personal fitness. However, challenges remain in efficiently processing the vast amounts of data generated by these devices and developing models that can accurately recognize a wide range of activities from continuous recordings, without relying on predefined activity training sessions. This paper presents a comprehensive framework for imputing, analyzing, and identifying activities from wearable data, specifically targeting group training scenarios without explicit activity sessions. Our approach is based on data collected from 135 soldiers wearing Garmin 55 smartwatches over six months. The framework integrates multiple data streams, handles missing data through cross-domain statistical methods, and identifies activities with high accuracy using machine learning (ML). Additionally, we utilized statistical analysis techniques to evaluate the performance of each individual within the group, providing valuable insights into their respective positions in the group in an easy-to-understand visualization. These visualizations facilitate easy understanding of performance metrics, enhancing group interactions and informing individualized training programs. We evaluate our framework through traditional train-test splits and out-of-sample scenarios, focusing on the model's generalization capabilities. Additionally, we address sleep data imputation without relying on ML, improving recovery analysis. Our findings demonstrate the potential of wearable data for accurately identifying group activities, paving the way for intelligent, data-driven training solutions.
Exploring Values in Museum Artifacts in the SPICE project: a Preliminary Study
Nov 13, 2023


This document describes the rationale, the implementation and a preliminary evaluation of a semantic reasoning tool developed in the EU H2020 SPICE project to enhance the diversity of perspectives experienced by museum visitors. The tool, called DEGARI 2.0 for values, relies on the commonsense reasoning framework TCL, and exploits an ontological model formalizingthe Haidt's theory of moral values to associate museum items with combined values and emotions. Within a museum exhibition, this tool can suggest cultural items that are associated not only with the values of already experienced or preferred objects, but also with novel items with different value stances, opening the visit experience to more inclusive interpretations of cultural content. The system has been preliminarily tested, in the context of the SPICE project, on the collection of the Hecht Museum of Haifa.
Addressing the cold start problem in privacy preserving content-based recommender systems using hypercube graphs
Oct 13, 2023



The initial interaction of a user with a recommender system is problematic because, in such a so-called cold start situation, the recommender system has very little information about the user, if any. Moreover, in collaborative filtering, users need to share their preferences with the service provider by rating items while in content-based filtering there is no need for such information sharing. We have recently shown that a content-based model that uses hypercube graphs can determine user preferences with a very limited number of ratings while better preserving user privacy. In this paper, we confirm these findings on the basis of experiments with more than 1,000 users in the restaurant and movie domains. We show that the proposed method outperforms standard machine learning algorithms when the number of available ratings is at most 10, which often happens, and is competitive with larger training sets. In addition, training is simple and does not require large computational efforts.
Person Entity Profiling Framework: Identifying, Integrating and Visualizing Online Freely Available Entity-Related Information
Oct 02, 2021
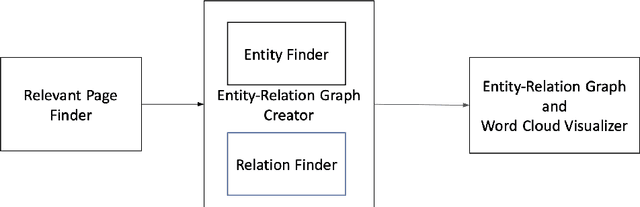

When we consider our CV, it is full of entities that we are or were associated with and that define us in some way(s). Such entities include where we studied, where we worked, who we collaborated with on a project or on a paper etc. Entities we are linked to are part of who we are and may reveal about what we are interested in. Hence, we can view any CV as a graph of interlinked entities, where nodes are entities and edges are relations between them. This study proposes a novel entity search framework that in response to a real-time query about an entity, searches, crawls, analyzes and consolidates relevant information that is freely available on the Web about the entity of interest, culminating in the generation a profile of the searched entity. Unlike typical entity search settings, in which a ranked list of entities related to the target entity over a pre-specified relation is processed, we present and visualize rich information about the entity of interest as a typed entity-relation graph without an apriori definition of the types of related entities and relations. This view is structured and compact, making it easy to understand as well as interpret. It enables the user to learn not only about the entity in question, but also about related entities, thereby obtaining a better understanding of the entity in question. We evaluated each of the frameworks components separately and then performed an overall evaluation of the framework, its visualization and the interest of users in the results. The results show that the proposed framework performs entity searches, related entity identification and relation identification very well and that it satisfies users needs.
Towards Algorithmic Transparency: A Diversity Perspective
Apr 12, 2021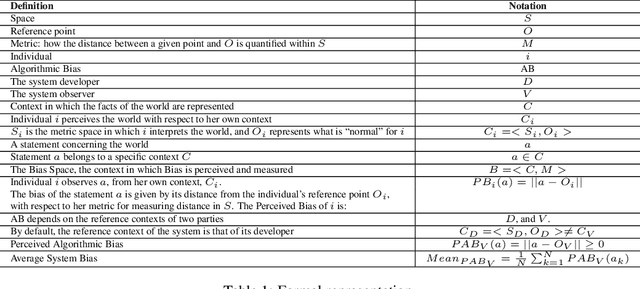
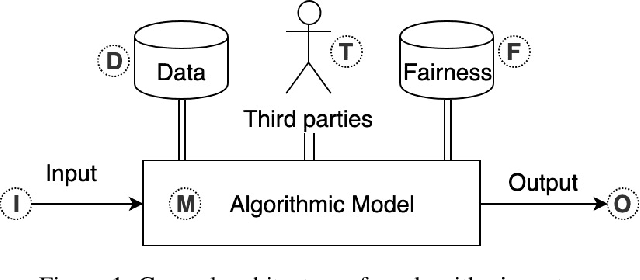
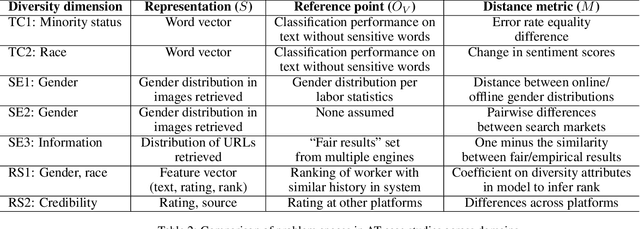
As the role of algorithmic systems and processes increases in society, so does the risk of bias, which can result in discrimination against individuals and social groups. Research on algorithmic bias has exploded in recent years, highlighting both the problems of bias, and the potential solutions, in terms of algorithmic transparency (AT). Transparency is important for facilitating fairness management as well as explainability in algorithms; however, the concept of diversity, and its relationship to bias and transparency, has been largely left out of the discussion. We reflect on the relationship between diversity and bias, arguing that diversity drives the need for transparency. Using a perspective-taking lens, which takes diversity as a given, we propose a conceptual framework to characterize the problem and solution spaces of AT, to aid its application in algorithmic systems. Example cases from three research domains are described using our framework.
Graph Based Recommendations: From Data Representation to Feature Extraction and Application
Jul 05, 2017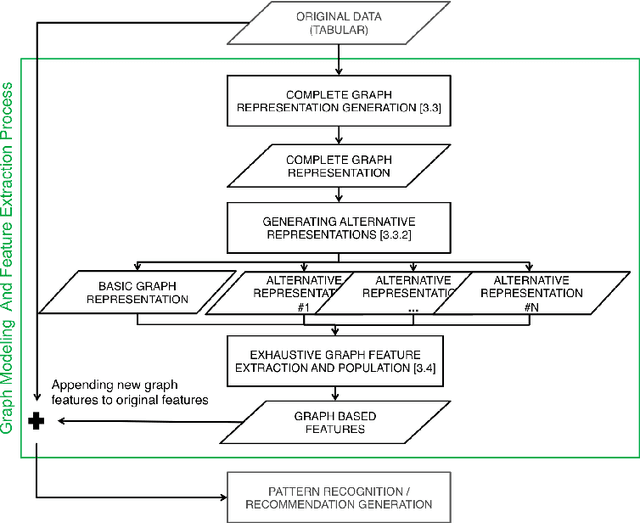

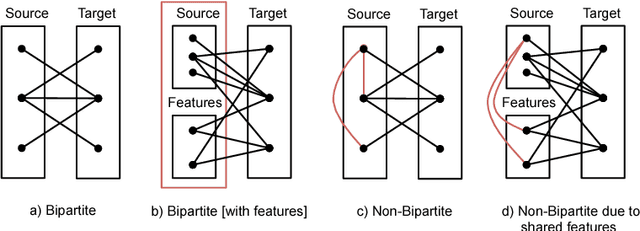

Modeling users for the purpose of identifying their preferences and then personalizing services on the basis of these models is a complex task, primarily due to the need to take into consideration various explicit and implicit signals, missing or uncertain information, contextual aspects, and more. In this study, a novel generic approach for uncovering latent preference patterns from user data is proposed and evaluated. The approach relies on representing the data using graphs, and then systematically extracting graph-based features and using them to enrich the original user models. The extracted features encapsulate complex relationships between users, items, and metadata. The enhanced user models can then serve as an input to any recommendation algorithm. The proposed approach is domain-independent (demonstrated on data from movies, music, and business recommender systems), and is evaluated using several state-of-the-art machine learning methods, on different recommendation tasks, and using different evaluation metrics. The results show a unanimous improvement in the recommendation accuracy across tasks and domains. In addition, the evaluation provides a deeper analysis regarding the performance of the approach in special scenarios, including high sparsity and variability of ratings.