 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Knowledge for Cross-Domain User Preference Modeling
Mar 10, 2026We demonstrate that user preferences can be represented and predicted across topical domains using large-scale social modeling. Given information about popular entities favored by a user, we project the user into a social embedding space learned from a large-scale sample of the Twitter (now X) network. By representing both users and popular entities in a joint social space, we can assess the relevance of candidate entities (e.g., music artists) using cosine similarity within this embedding space. A comprehensive evaluation using link prediction experiments shows that this method achieves effective personalization in zero-shot setting, when no user feedback is available for entities in the target domain, yielding substantial improvements over a strong popularity-based baseline. In-depth analysis further illustrates that socio-demographic factors encoded in the social embeddings are correlated with user preferences across domains. Finally, we argue and demonstrate that the proposed approach can facilitate social modeling of end users using large language models (LLMs).
The X Types -- Mapping the Semantics of the Twitter Sphere
Sep 22, 2024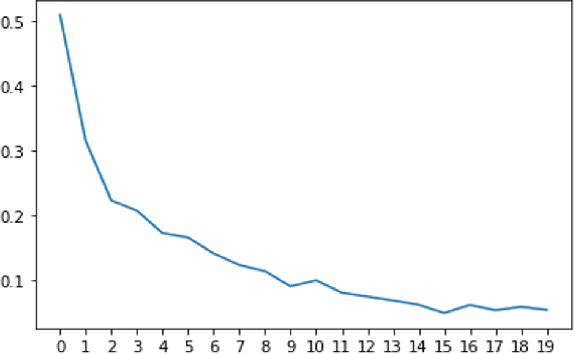
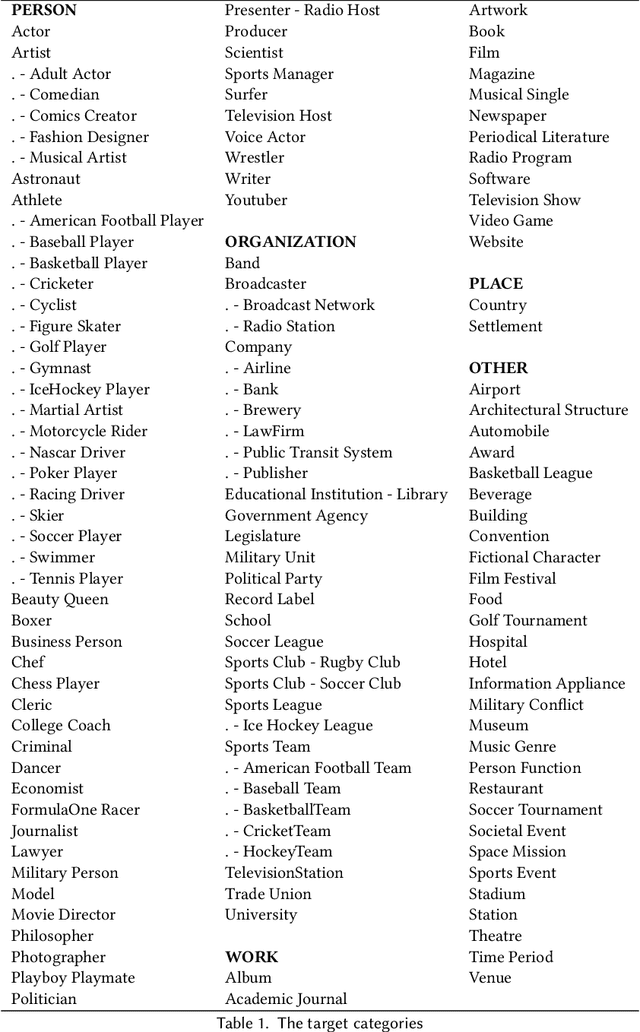
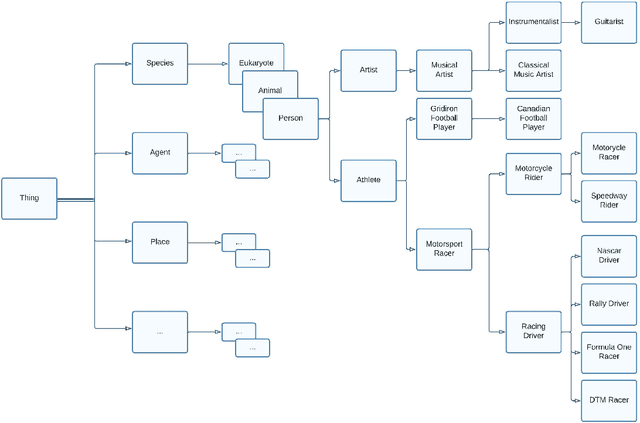

Social networks form a valuable source of world knowledge, where influential entities correspond to popular accounts. Unlike factual knowledge bases (KBs), which maintain a semantic ontology, structured semantic information is not available on social media. In this work, we consider a social KB of roughly 200K popular Twitter accounts, which denotes entities of interest. We elicit semantic information about those entities. In particular, we associate them with a fine-grained set of 136 semantic types, e.g., determine whether a given entity account belongs to a politician, or a musical artist. In the lack of explicit type information in Twitter, we obtain semantic labels for a subset of the accounts via alignment with the KBs of DBpedia and Wikidata. Given the labeled dataset, we finetune a transformer-based text encoder to generate semantic embeddings of the entities based on the contents of their accounts. We then exploit this evidence alongside network-based embeddings to predict the entities semantic types. In our experiments, we show high type prediction performance on the labeled dataset. Consequently, we apply our type classification model to all of the entity accounts in the social KB. Our analysis of the results offers insights about the global semantics of the Twitter sphere. We discuss downstream applications that should benefit from semantic type information and the semantic embeddings of social entities generated in this work. In particular, we demonstrate enhanced performance on the key task of entity similarity assessment using this information.
Generative AI for Hate Speech Detection: Evaluation and Findings
Nov 16, 2023Automatic hate speech detection using deep neural models is hampered by the scarcity of labeled datasets, leading to poor generalization. To mitigate this problem, generative AI has been utilized to generate large amounts of synthetic hate speech sequences from available labeled examples, leveraging the generated data in finetuning large pre-trained language models (LLMs). In this chapter, we provide a review of relevant methods, experimental setups and evaluation of this approach. In addition to general LLMs, such as BERT, RoBERTa and ALBERT, we apply and evaluate the impact of train set augmentation with generated data using LLMs that have been already adapted for hate detection, including RoBERTa-Toxicity, HateBERT, HateXplain, ToxDect, and ToxiGen. An empirical study corroborates our previous findings, showing that this approach improves hate speech generalization, boosting recall performance across data distributions. In addition, we explore and compare the performance of the finetuned LLMs with zero-shot hate detection using a GPT-3.5 model. Our results demonstrate that while better generalization is achieved using the GPT-3.5 model, it achieves mediocre recall and low precision on most datasets. It is an open question whether the sensitivity of models such as GPT-3.5, and onward, can be improved using similar techniques of text generation.
Social World Knowledge: Modeling and Applications
Jun 28, 2023Social world knowledge is a key ingredient in effective communication and information processing by humans and machines alike. As of today, there exist many knowledge bases that represent factual world knowledge. Yet, there is no resource that is designed to capture social aspects of world knowledge. We believe that this work makes an important step towards the formulation and construction of such a resource. We introduce SocialVec, a general framework for eliciting low-dimensional entity embeddings from the social contexts in which they occur in social networks. In this framework, entities correspond to highly popular accounts which invoke general interest. We assume that entities that individual users tend to co-follow are socially related, and use this definition of social context to learn the entity embeddings. Similar to word embeddings which facilitate tasks that involve text semantics, we expect the learned social entity embeddings to benefit multiple tasks of social flavor. In this work, we elicited the social embeddings of roughly 200K entities from a sample of 1.3M Twitter users and the accounts that they follow. We employ and gauge the resulting embeddings on two tasks of social importance. First, we assess the political bias of news sources in terms of entity similarity in the social embedding space. Second, we predict the personal traits of individual Twitter users based on the social embeddings of entities that they follow. In both cases, we show advantageous or competitive performance using our approach compared with task-specific baselines. We further show that existing entity embedding schemes, which are fact-based, fail to capture social aspects of knowledge. We make the learned social entity embeddings available to the research community to support further exploration of social world knowledge and its applications.
Detecting and Characterizing Political Incivility on Social Media
May 24, 2023
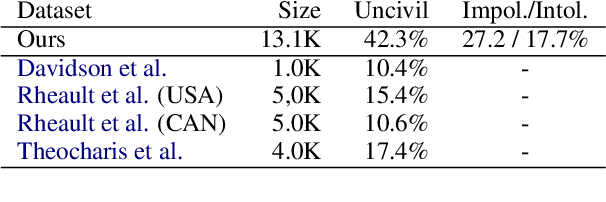
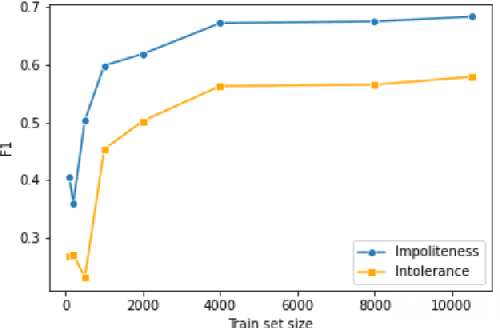

Researchers of political communication study the impact and perceptions of political incivility on social media. Yet, so far, relatively few works attempted to automatically detect and characterize political incivility. In our work, we study political incivility in Twitter, presenting several research contributions. First, we present state-of-the-art incivility detection results using a large dataset, which we collected and labeled via crowd sourcing. Importantly, we distinguish between uncivil political speech that is impolite and intolerant anti-democratic discourse. Applying political incivility detection at large-scale, we derive insights regarding the prevalence of this phenomenon across users, and explore the network characteristics of users who are susceptible to disseminating uncivil political content online. Finally, we propose an approach for modeling social context information about the tweet author alongside the tweet content, showing that this leads to significantly improved performance on the task of political incivility detection. This result holds promise for related tasks, such as hate speech and stance detection.
Character-level HyperNetworks for Hate Speech Detection
Nov 11, 2021
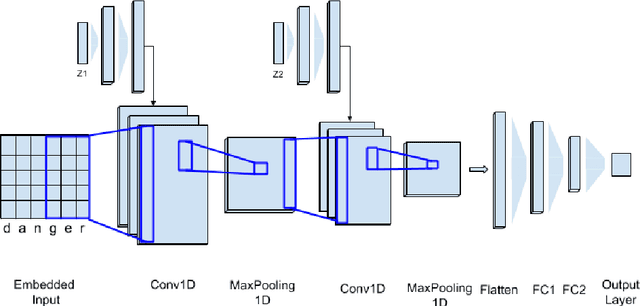

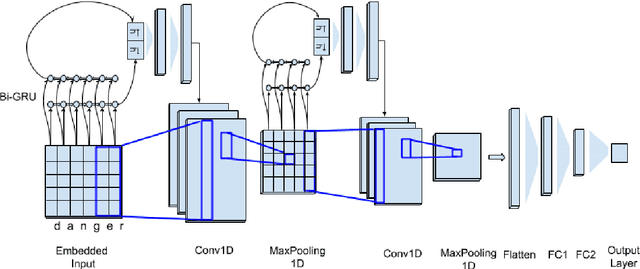
The massive spread of hate speech, hateful content targeted at specific subpopulations, is a problem of critical social importance. Automated methods for hate speech detection typically employ state-of-the-art deep learning (DL)-based text classifiers-very large pre-trained neural language models of over 100 million parameters, adapting these models to the task of hate speech detection using relevant labeled datasets. Unfortunately, there are only numerous labeled datasets of limited size that are available for this purpose. We make several contributions with high potential for advancing this state of affairs. We present HyperNetworks for hate speech detection, a special class of DL networks whose weights are regulated by a small-scale auxiliary network. These architectures operate at character-level, as opposed to word-level, and are several magnitudes of order smaller compared to the popular DL classifiers. We further show that training hate detection classifiers using large amounts of automatically generated examples in a procedure named as it data augmentation is beneficial in general, yet this practice especially boosts the performance of the proposed HyperNetworks. In fact, we achieve performance that is comparable or better than state-of-the-art language models, which are pre-trained and orders of magnitude larger, using this approach, as evaluated using five public hate speech datasets.
SocialVec: Social Entity Embeddings
Nov 05, 2021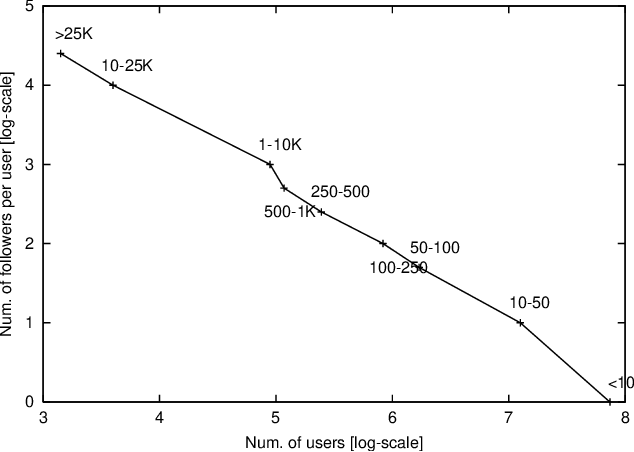

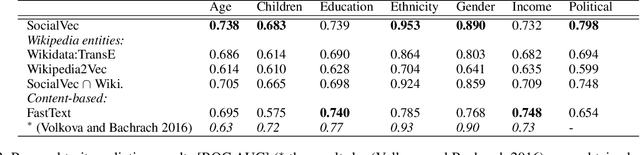
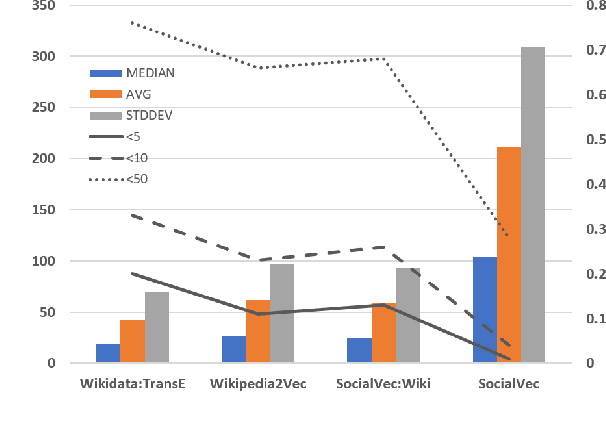
This paper introduces SocialVec, a general framework for eliciting social world knowledge from social networks, and applies this framework to Twitter. SocialVec learns low-dimensional embeddings of popular accounts, which represent entities of general interest, based on their co-occurrences patterns within the accounts followed by individual users, thus modeling entity similarity in socio-demographic terms. Similar to word embeddings, which facilitate tasks that involve text processing, we expect social entity embeddings to benefit tasks of social flavor. We have learned social embeddings for roughly 200,000 popular accounts from a sample of the Twitter network that includes more than 1.3 million users and the accounts that they follow, and evaluate the resulting embeddings on two different tasks. The first task involves the automatic inference of personal traits of users from their social media profiles. In another study, we exploit SocialVec embeddings for gauging the political bias of news sources in Twitter. In both cases, we prove SocialVec embeddings to be advantageous compared with existing entity embedding schemes. We will make the SocialVec entity embeddings publicly available to support further exploration of social world knowledge as reflected in Twitter.
Person Entity Profiling Framework: Identifying, Integrating and Visualizing Online Freely Available Entity-Related Information
Oct 02, 2021
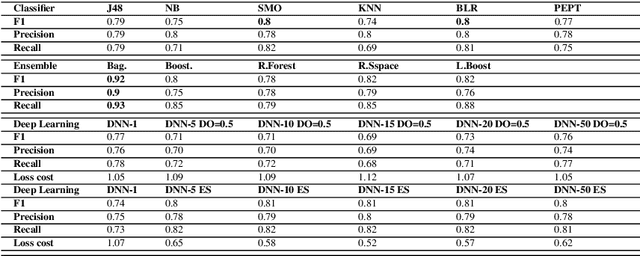
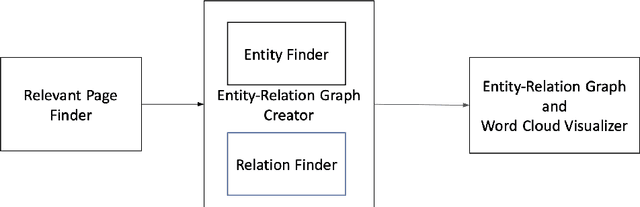

When we consider our CV, it is full of entities that we are or were associated with and that define us in some way(s). Such entities include where we studied, where we worked, who we collaborated with on a project or on a paper etc. Entities we are linked to are part of who we are and may reveal about what we are interested in. Hence, we can view any CV as a graph of interlinked entities, where nodes are entities and edges are relations between them. This study proposes a novel entity search framework that in response to a real-time query about an entity, searches, crawls, analyzes and consolidates relevant information that is freely available on the Web about the entity of interest, culminating in the generation a profile of the searched entity. Unlike typical entity search settings, in which a ranked list of entities related to the target entity over a pre-specified relation is processed, we present and visualize rich information about the entity of interest as a typed entity-relation graph without an apriori definition of the types of related entities and relations. This view is structured and compact, making it easy to understand as well as interpret. It enables the user to learn not only about the entity in question, but also about related entities, thereby obtaining a better understanding of the entity in question. We evaluated each of the frameworks components separately and then performed an overall evaluation of the framework, its visualization and the interest of users in the results. The results show that the proposed framework performs entity searches, related entity identification and relation identification very well and that it satisfies users needs.
Fight Fire with Fire: Fine-tuning Hate Detectors using Large Samples of Generated Hate Speech
Sep 01, 2021
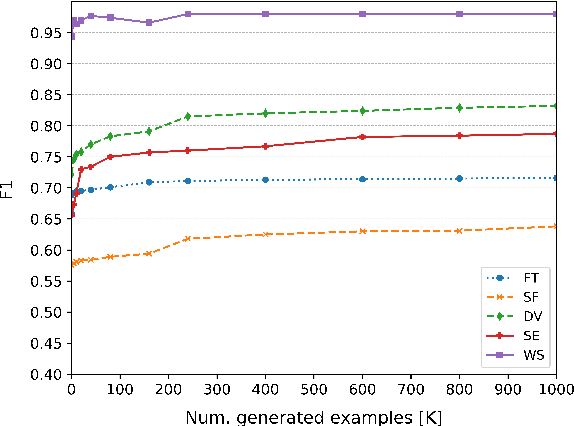
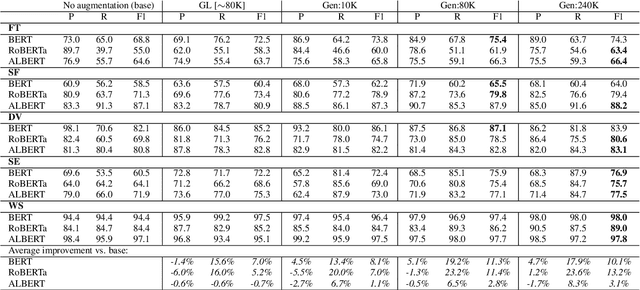
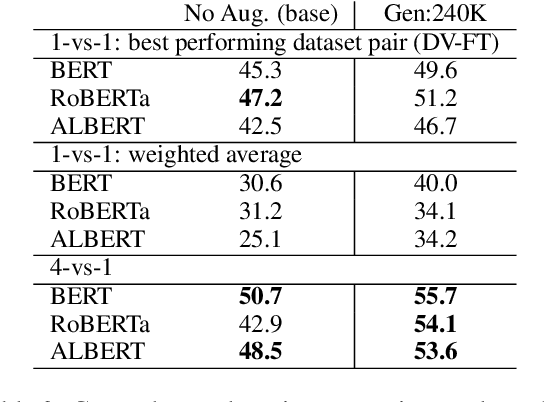
Automatic hate speech detection is hampered by the scarcity of labeled datasetd, leading to poor generalization. We employ pretrained language models (LMs) to alleviate this data bottleneck. We utilize the GPT LM for generating large amounts of synthetic hate speech sequences from available labeled examples, and leverage the generated data in fine-tuning large pretrained LMs on hate detection. An empirical study using the models of BERT, RoBERTa and ALBERT, shows that this approach improves generalization significantly and consistently within and across data distributions. In fact, we find that generating relevant labeled hate speech sequences is preferable to using out-of-domain, and sometimes also within-domain, human-labeled examples.
What's the best place for an AI conference, Vancouver or ______: Why completing comparative questions is difficult
Apr 05, 2021
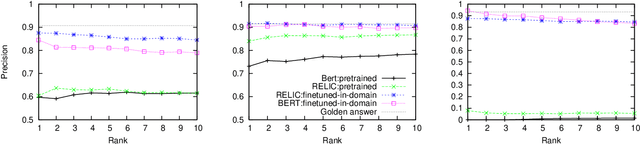

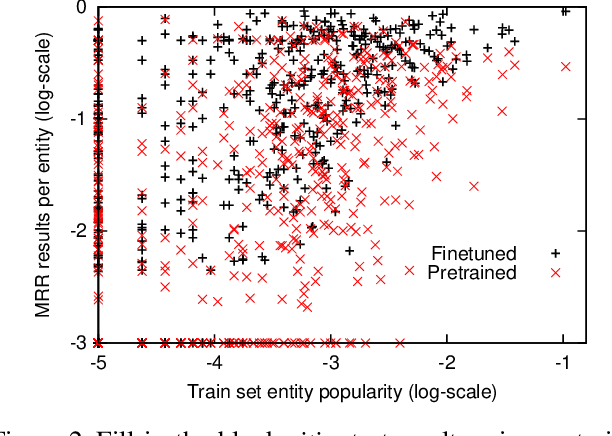
Although large neural language models (LMs) like BERT can be finetuned to yield state-of-the-art results on many NLP tasks, it is often unclear what these models actually learn. Here we study using such LMs to fill in entities in human-authored comparative questions, like ``Which country is older, India or ______?'' -- i.e., we study the ability of neural LMs to ask (not answer) reasonable questions. We show that accuracy in this fill-in-the-blank task is well-correlated with human judgements of whether a question is reasonable, and that these models can be trained to achieve nearly human-level performance in completing comparative questions in three different subdomains. However, analysis shows that what they learn fails to model any sort of broad notion of which entities are semantically comparable or similar -- instead the trained models are very domain-specific, and performance is highly correlated with co-occurrences between specific entities observed in the training set. This is true both for models that are pretrained on general text corpora, as well as models trained on a large corpus of comparison questions. Our study thus reinforces recent results on the difficulty of making claims about a deep model's world knowledge or linguistic competence based on performance on specific benchmark problems. We make our evaluation datasets publicly available to foster future research on complex understanding and reasoning in such models at standards of human interaction.