 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Full Waveform Inversion by Deep Compressed Learning
Jan 03, 2026We propose and test a method to reduce the dimensionality of Full Waveform Inversion (FWI) inputs as computational cost mitigation approach. Given modern seismic acquisition systems, the data (as input for FWI) required for an industrial-strength case is in the teraflop level of storage, therefore solving complex subsurface cases or exploring multiple scenarios with FWI become prohibitive. The proposed method utilizes a deep neural network with a binarized sensing layer that learns by compressed learning a succinct but consequential seismic acquisition layout from a large corpus of subsurface models. Thus, given a large seismic data set to invert, the trained network selects a smaller subset of the data, then by using representation learning, an autoencoder computes latent representations of the data, followed by K-means clustering of the latent representations to further select the most relevant data for FWI. Effectively, this approach can be seen as a hierarchical selection. The proposed approach consistently outperforms random data sampling, even when utilizing only 10% of the data for 2D FWI, these results pave the way to accelerating FWI in large scale 3D inversion.
Generative AI for Hate Speech Detection: Evaluation and Findings
Nov 16, 2023Automatic hate speech detection using deep neural models is hampered by the scarcity of labeled datasets, leading to poor generalization. To mitigate this problem, generative AI has been utilized to generate large amounts of synthetic hate speech sequences from available labeled examples, leveraging the generated data in finetuning large pre-trained language models (LLMs). In this chapter, we provide a review of relevant methods, experimental setups and evaluation of this approach. In addition to general LLMs, such as BERT, RoBERTa and ALBERT, we apply and evaluate the impact of train set augmentation with generated data using LLMs that have been already adapted for hate detection, including RoBERTa-Toxicity, HateBERT, HateXplain, ToxDect, and ToxiGen. An empirical study corroborates our previous findings, showing that this approach improves hate speech generalization, boosting recall performance across data distributions. In addition, we explore and compare the performance of the finetuned LLMs with zero-shot hate detection using a GPT-3.5 model. Our results demonstrate that while better generalization is achieved using the GPT-3.5 model, it achieves mediocre recall and low precision on most datasets. It is an open question whether the sensitivity of models such as GPT-3.5, and onward, can be improved using similar techniques of text generation.
Deep Compressed Learning for 3D Seismic Inversion
Oct 31, 2023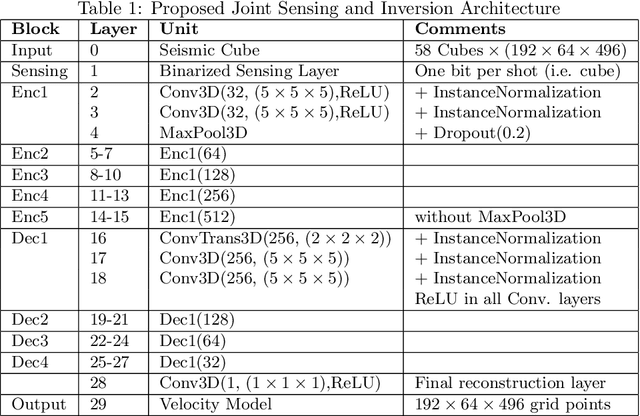
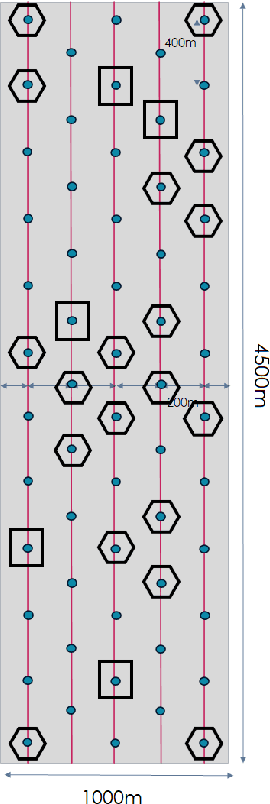
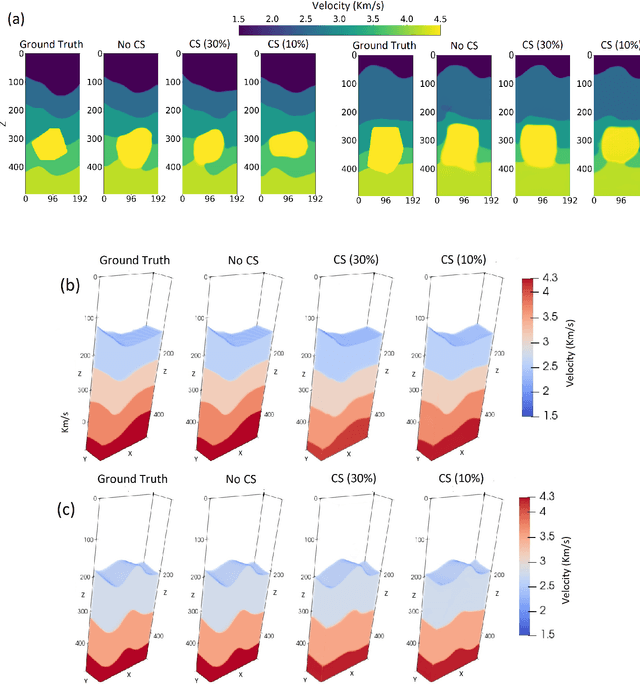
We consider the problem of 3D seismic inversion from pre-stack data using a very small number of seismic sources. The proposed solution is based on a combination of compressed-sensing and machine learning frameworks, known as compressed-learning. The solution jointly optimizes a dimensionality reduction operator and a 3D inversion encoder-decoder implemented by a deep convolutional neural network (DCNN). Dimensionality reduction is achieved by learning a sparse binary sensing layer that selects a small subset of the available sources, then the selected data is fed to a DCNN to complete the regression task. The end-to-end learning process provides a reduction by an order-of-magnitude in the number of seismic records used during training, while preserving the 3D reconstruction quality comparable to that obtained by using the entire dataset.
An F-ratio-Based Method for Estimating the Number of Active Sources in MEG
Jun 09, 2023



Magnetoencephalography (MEG) is a powerful technique for studying the human brain function. However, accurately estimating the number of sources that contribute to the MEG recordings remains a challenging problem due to the low signal-to-noise ratio (SNR), the presence of correlated sources, inaccuracies in head modeling, and variations in individual anatomy. To address these issues, our study introduces a robust method for accurately estimating the number of active sources in the brain based on the F-ratio statistical approach, which allows for a comparison between a full model with a higher number of sources and a reduced model with fewer sources. Using this approach, we developed a formal statistical procedure that sequentially increases the number of sources in the multiple dipole localization problem until all sources are found. Our results revealed that the selection of thresholds plays a critical role in determining the method`s overall performance, and appropriate thresholds needed to be adjusted for the number of sources and SNR levels, while they remained largely invariant to different inter-source correlations, modeling inaccuracies, and different cortical anatomies. By identifying optimal thresholds and validating our F-ratio-based method in simulated, real phantom, and human MEG data, we demonstrated the superiority of our F-ratio-based method over existing state-of-the-art statistical approaches, such as the Akaike Information Criterion (AIC) and Minimum Description Length (MDL). Overall, when tuned for optimal selection of thresholds, our method offers researchers a precise tool to estimate the true number of active brain sources and accurately model brain function.
Encoder-Decoder Architecture for 3D Seismic Inversion
Jul 29, 2022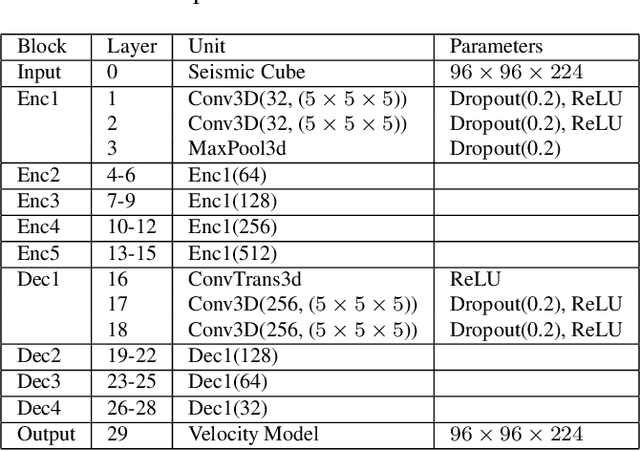
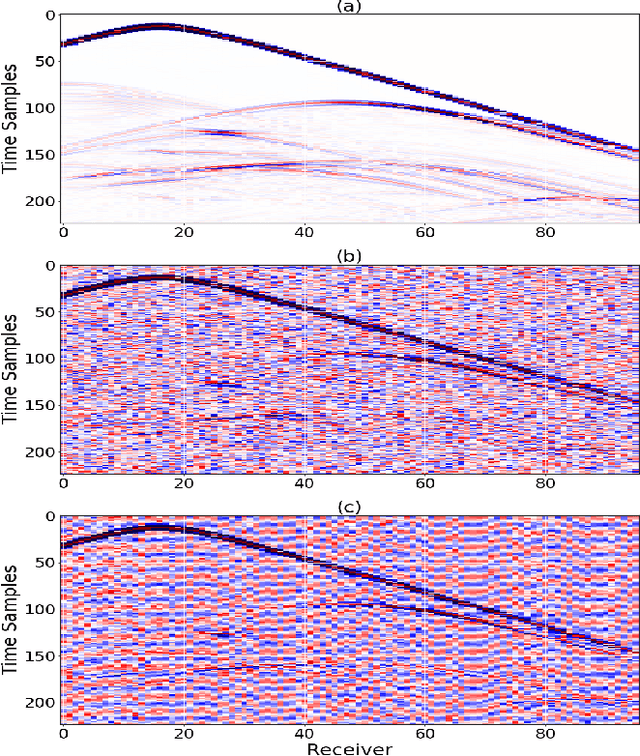

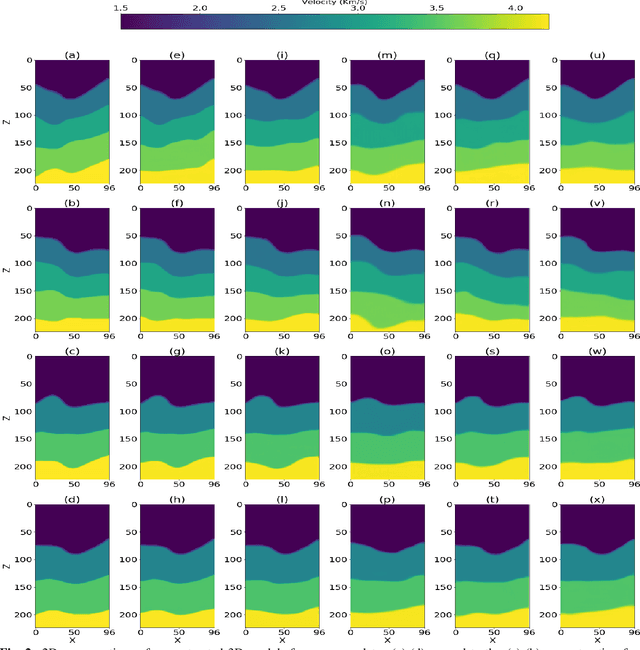
Inverting seismic data to build 3D geological structures is a challenging task due to the overwhelming amount of acquired seismic data, and the very-high computational load due to iterative numerical solutions of the wave equation, as required by industry-standard tools such as Full Waveform Inversion (FWI). For example, in an area with surface dimensions of 4.5km $\times$ 4.5km, hundreds of seismic shot-gather cubes are required for 3D model reconstruction, leading to Terabytes of recorded data. This paper presents a deep learning solution for the reconstruction of realistic 3D models in the presence of field noise recorded in seismic surveys. We implement and analyze a convolutional encoder-decoder architecture that efficiently processes the entire collection of hundreds of seismic shot-gather cubes. The proposed solution demonstrates that realistic 3D models can be reconstructed with a structural similarity index measure (SSIM) of 0.8554 (out of 1.0) in the presence of field noise at 10dB signal-to-noise ratio.
Brain Source Localization by Alternating Projection
Feb 02, 2022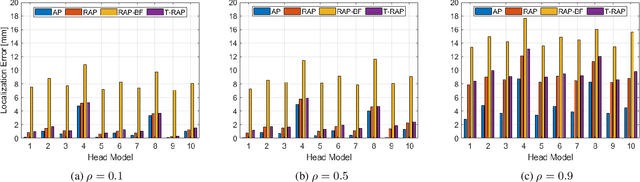
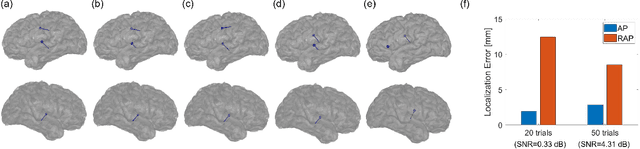
We present a novel solution to the problem of localizing magnetoencephalography (MEG) and electroencephalography (EEG) brain signals. The solution is sequential and iterative, and is based on minimizing the least-squares criterion by the Alternating Projection algorithm. Results from simulated and experimental MEG data from a human subject demonstrated robust performance, with consistently superior localization accuracy than scanning methods belonging to the beamformer and multiple-signal classification (MUSIC) families. Importantly, the proposed solution is more robust to forward model errors resulting from head rotations and translations, with a significant advantage in highly correlated sources.
Character-level HyperNetworks for Hate Speech Detection
Nov 11, 2021
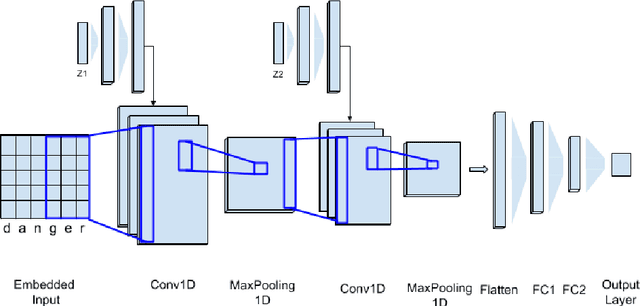

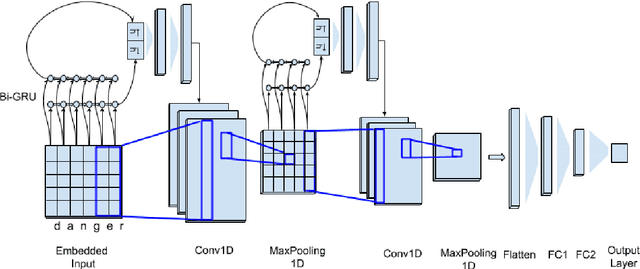
The massive spread of hate speech, hateful content targeted at specific subpopulations, is a problem of critical social importance. Automated methods for hate speech detection typically employ state-of-the-art deep learning (DL)-based text classifiers-very large pre-trained neural language models of over 100 million parameters, adapting these models to the task of hate speech detection using relevant labeled datasets. Unfortunately, there are only numerous labeled datasets of limited size that are available for this purpose. We make several contributions with high potential for advancing this state of affairs. We present HyperNetworks for hate speech detection, a special class of DL networks whose weights are regulated by a small-scale auxiliary network. These architectures operate at character-level, as opposed to word-level, and are several magnitudes of order smaller compared to the popular DL classifiers. We further show that training hate detection classifiers using large amounts of automatically generated examples in a procedure named as it data augmentation is beneficial in general, yet this practice especially boosts the performance of the proposed HyperNetworks. In fact, we achieve performance that is comparable or better than state-of-the-art language models, which are pre-trained and orders of magnitude larger, using this approach, as evaluated using five public hate speech datasets.
Fight Fire with Fire: Fine-tuning Hate Detectors using Large Samples of Generated Hate Speech
Sep 01, 2021
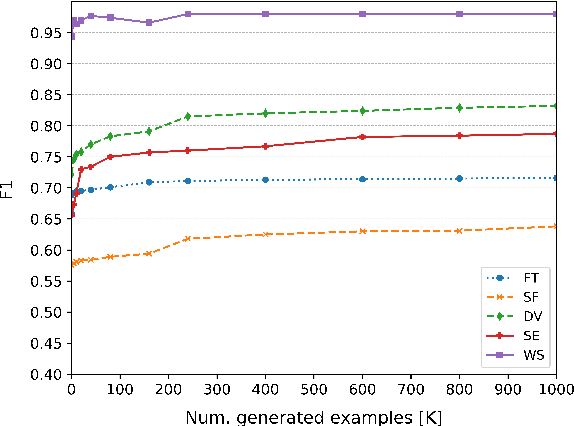
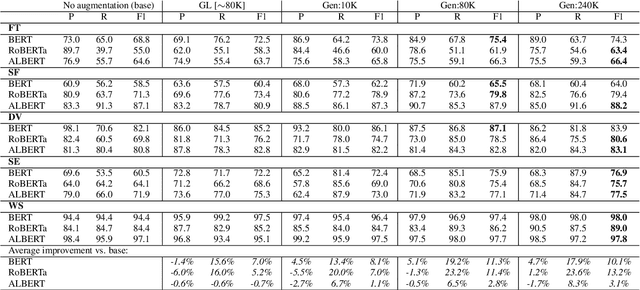
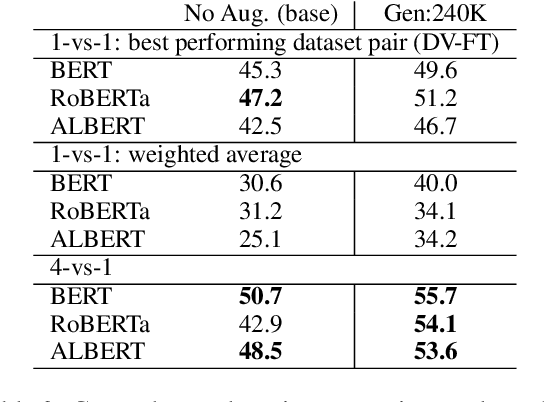
Automatic hate speech detection is hampered by the scarcity of labeled datasetd, leading to poor generalization. We employ pretrained language models (LMs) to alleviate this data bottleneck. We utilize the GPT LM for generating large amounts of synthetic hate speech sequences from available labeled examples, and leverage the generated data in fine-tuning large pretrained LMs on hate detection. An empirical study using the models of BERT, RoBERTa and ALBERT, shows that this approach improves generalization significantly and consistently within and across data distributions. In fact, we find that generating relevant labeled hate speech sequences is preferable to using out-of-domain, and sometimes also within-domain, human-labeled examples.
Towards Hate Speech Detection at Large via Deep Generative Modeling
May 13, 2020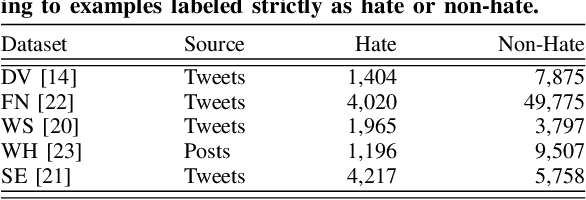



Hate speech detection is a critical problem in social media platforms, being often accused for enabling the spread of hatred and igniting physical violence. Hate speech detection requires overwhelming resources including high-performance computing for online posts and tweets monitoring as well as thousands of human experts for daily screening of suspected posts or tweets. Recently, Deep Learning (DL)-based solutions have been proposed for automatic detection of hate speech, using modest-sized training datasets of few thousands of hate speech sequences. While these methods perform well on the specific datasets, their ability to detect new hate speech sequences is limited and has not been investigated. Being a data-driven approach, it is well known that DL surpasses other methods whenever a scale-up in train dataset size and diversity is achieved. Therefore, we first present a dataset of 1 million realistic hate and non-hate sequences, produced by a deep generative language model. We further utilize the generated dataset to train a well-studied DL-based hate speech detector, and demonstrate consistent and significant performance improvements across five public hate speech datasets. Therefore, the proposed solution enables high sensitivity detection of a very large variety of hate speech sequences, paving the way to a fully automatic solution.
Deep Learning of Compressed Sensing Operators with Structural Similarity Loss
Jun 25, 2019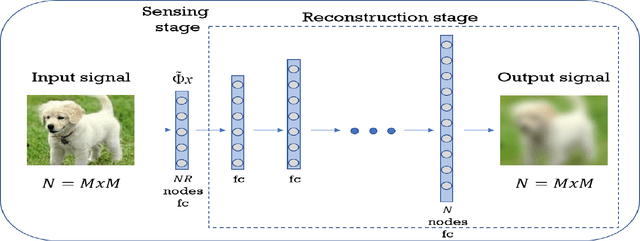

Compressed sensing (CS) is a signal processing framework for efficiently reconstructing a signal from a small number of measurements, obtained by linear projections of the signal. In this paper we present an end-to-end deep learning approach for CS, in which a fully-connected network performs both the linear sensing and non-linear reconstruction stages. During the training phase, the sensing matrix and the non-linear reconstruction operator are jointly optimized using Structural similarity index (SSIM) as loss rather than the standard Mean Squared Error (MSE) loss. We compare the proposed approach with state-of-the-art in terms of reconstruction quality under both losses, i.e. SSIM score and MSE score.