 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimal-Dual Sequential Subspace Optimization for Saddle-point Problems
Aug 20, 2020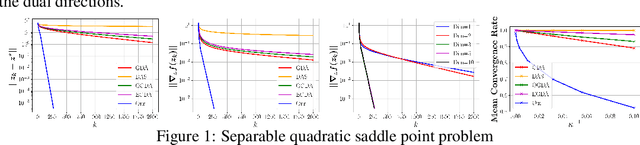
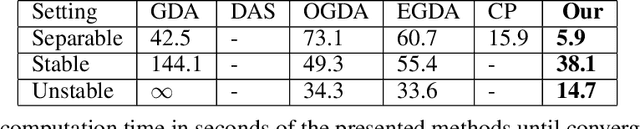
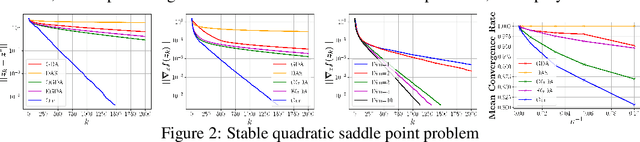
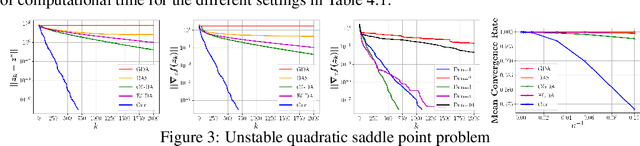
We introduce a new sequential subspace optimization method for large-scale saddle-point problems. It solves iteratively a sequence of auxiliary saddle-point problems in low-dimensional subspaces, spanned by directions derived from first-order information over the primal \emph{and} dual variables. Proximal regularization is further deployed to stabilize the optimization process. Experimental results demonstrate significantly better convergence relative to popular first-order methods. We analyze the influence of the subspace on the convergence of the algorithm, and assess its performance in various deterministic optimization scenarios, such as bi-linear games, ADMM-based constrained optimization and generative adversarial networks.
PILOT: Physics-Informed Learned Optimal Trajectories for Accelerated MRI
Oct 03, 2019

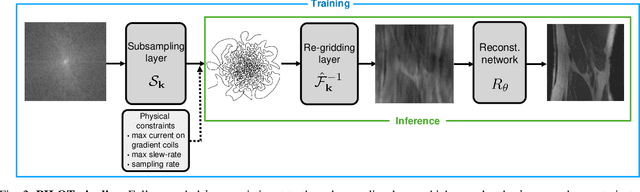
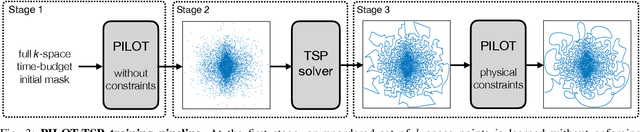
Magnetic Resonance Imaging (MRI) has long been considered to be among "the gold standards" of diagnostic medical imaging. The long acquisition times, however, render MRI prone to motion artifacts, let alone their adverse contribution to the relative high costs of MRI examination. Over the last few decades, multiple studies have focused on the development of both physical and post-processing methods for accelerated acquisition of MRI scans. These two approaches, however, have so far been addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of concurrent learning-based design of data acquisition and image reconstruction schemes. In this work, we propose a novel approach to the learning of optimal schemes for conjoint acquisition and reconstruction of MRI scans, with the optimization carried out simultaneously with respect to the time-efficiency of data acquisition and the quality of resulting reconstructions. To be of a practical value, the schemes are encoded in the form of general k-space trajectories, whose associated magnetic gradients are constrained to obey a set of predefined hardware requirements (as defined in terms of, e.g., peak currents and maximum slew rates of magnetic gradients). With this proviso in mind, we propose a novel algorithm for the end-to-end training of a combined acquisition-reconstruction pipeline using a deep neural network with differentiable forward- and back-propagation operators. We also demonstrate the effectiveness of the proposed solution in application to both image reconstruction and image segmentation, reporting substantial improvements in terms of acceleration factors as well as the quality of these end tasks.
Texture and Structure Two-view Classification of Images
Aug 25, 2019
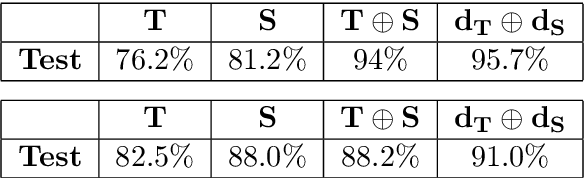

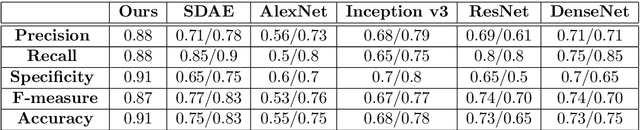
Textural and structural features can be regraded as "two-view" feature sets. Inspired by the recent progress in multi-view learning, we propose a novel two-view classification method that models each feature set and optimizes the process of merging these views efficiently. Examples of implementation of this approach in classification of real-world data are presented, with special emphasis on medical images. We firstly decompose fully-textured images into two layers of representation, corresponding to natural stochastic textures (NST) and structural layer, respectively. The structural, edge-and-curve-type, information is mostly represented by the local spatial phase, whereas, the pure NST has random phase and is characterized by Gaussianity and self-similarity. Therefore, the NST is modeled by the 2D self-similar process, fractional Brownian motion (fBm). The Hurst parameter, characteristic of fBm, specifies the roughness or irregularity of the texture. This leads us to its estimation and implementation along other features extracted from the structure layer, to build the "two-view" features sets used in our classification scheme. A shallow neural net (NN) is exploited to execute the process of merging these feature sets, in a straightforward and efficient manner.
Self-supervised learning of inverse problem solvers in medical imaging
May 22, 2019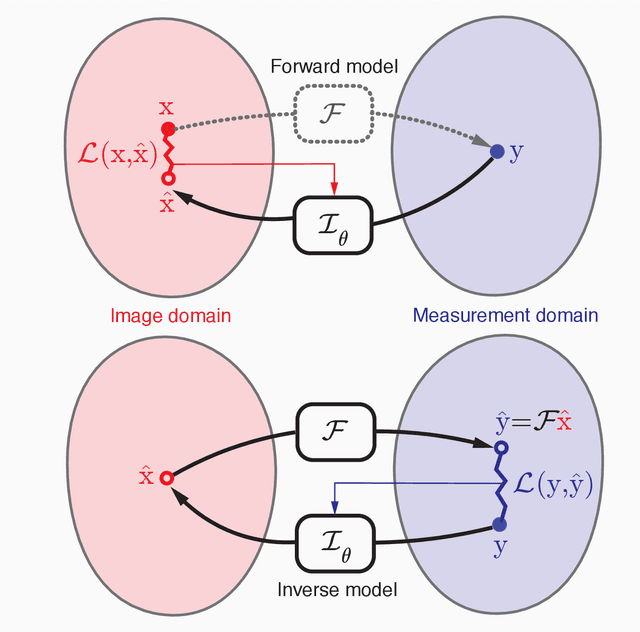
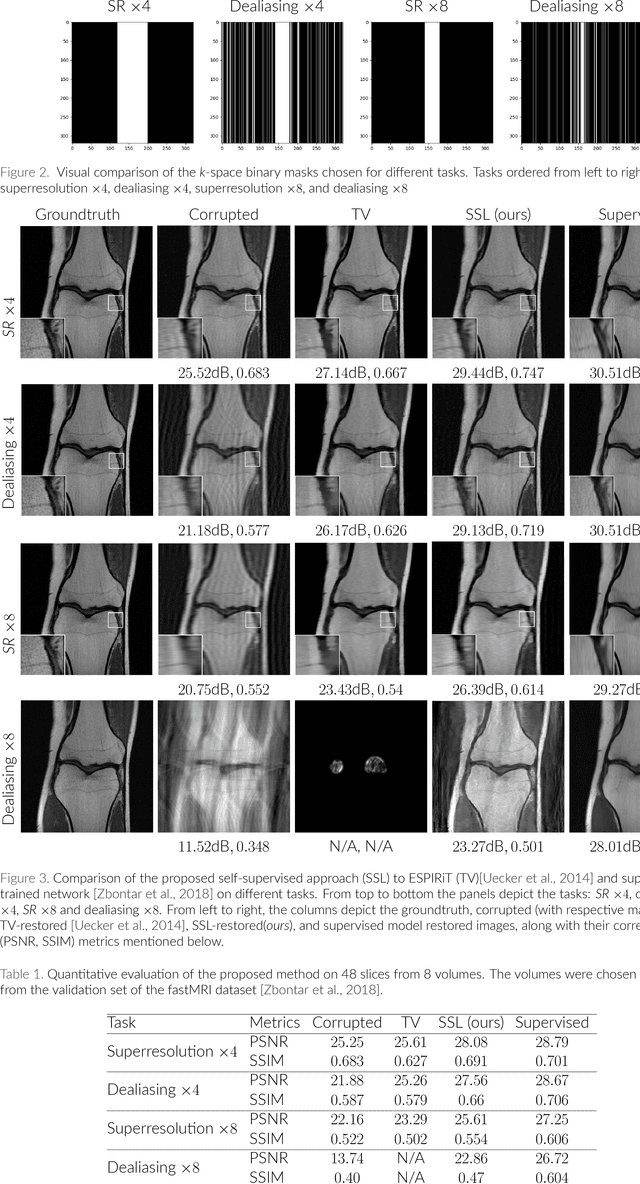
In the past few years, deep learning-based methods have demonstrated enormous success for solving inverse problems in medical imaging. In this work, we address the following question:\textit{Given a set of measurements obtained from real imaging experiments, what is the best way to use a learnable model and the physics of the modality to solve the inverse problem and reconstruct the latent image?} Standard supervised learning based methods approach this problem by collecting data sets of known latent images and their corresponding measurements. However, these methods are often impractical due to the lack of availability of appropriately sized training sets, and, more generally, due to the inherent difficulty in measuring the "groundtruth" latent image. In light of this, we propose a self-supervised approach to training inverse models in medical imaging in the absence of aligned data. Our method only requiring access to the measurements and the forward model at training. We showcase its effectiveness on inverse problems arising in accelerated magnetic resonance imaging (MRI).
Learning Fast Magnetic Resonance Imaging
May 22, 2019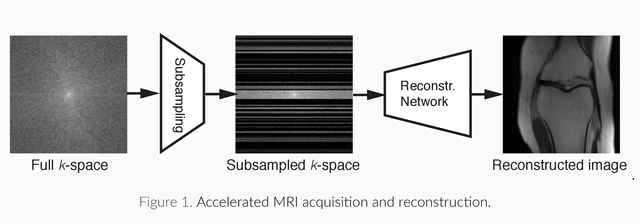

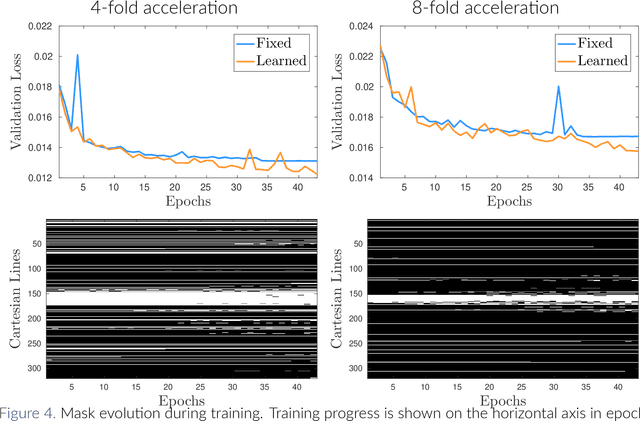
Magnetic Resonance Imaging (MRI) is considered today the golden-standard modality for soft tissues. The long acquisition times, however, make it more prone to motion artifacts as well as contribute to the relatively high costs of this examination. Over the years, multiple studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MRI, however, these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of the simultaneous learning-based design of the acquisition and reconstruction schemes manifesting significant improvement in the reconstruction quality with a constrained time budget. Inspired by these successes, in this work, we propose to learn accelerated MR acquisition schemes (in the form of Cartesian trajectories) jointly with the image reconstruction operator. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using the learned Cartesian trajectories at different speed up rates.
Learning beamforming in ultrasound imaging
Dec 19, 2018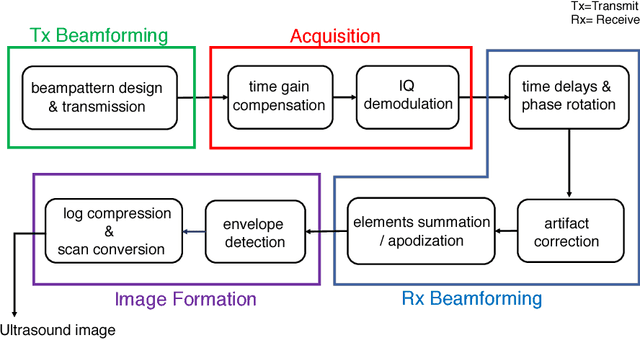



Medical ultrasound (US) is a widespread imaging modality owing its popularity to cost efficiency, portability, speed, and lack of harmful ionizing radiation. In this paper, we demonstrate that replacing the traditional ultrasound processing pipeline with a data-driven, learnable counterpart leads to significant improvement in image quality. Moreover, we demonstrate that greater improvement can be achieved through a learning-based design of the transmitted beam patterns simultaneously with learning an image reconstruction pipeline. We evaluate our method on an in-vivo first-harmonic cardiac ultrasound dataset acquired from volunteers and demonstrate the significance of the learned pipeline and transmit beam patterns on the image quality when compared to standard transmit and receive beamformers used in high frame-rate US imaging. We believe that the presented methodology provides a fundamentally different perspective on the classical problem of ultrasound beam pattern design.
High frame-rate cardiac ultrasound imaging with deep learning
Aug 23, 2018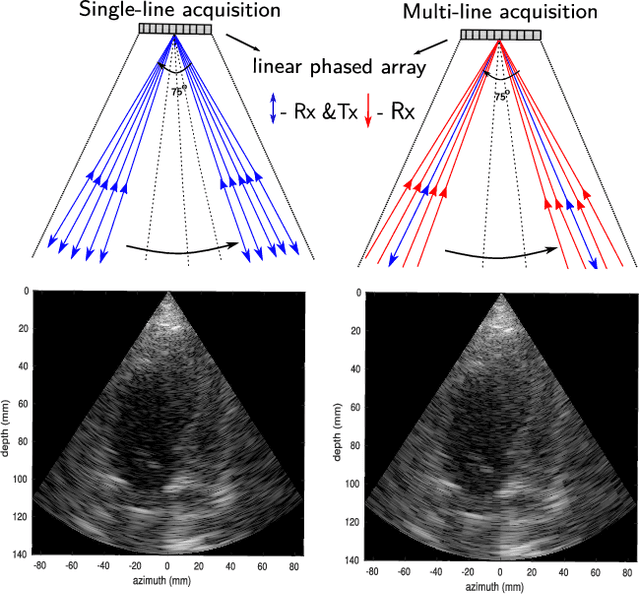

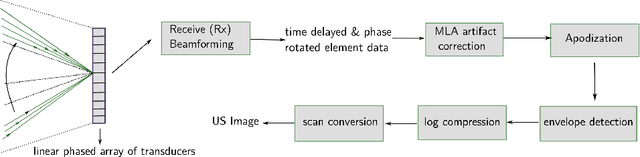

Cardiac ultrasound imaging requires a high frame rate in order to capture rapid motion. This can be achieved by multi-line acquisition (MLA), where several narrow-focused received lines are obtained from each wide-focused transmitted line. This shortens the acquisition time at the expense of introducing block artifacts. In this paper, we propose a data-driven learning-based approach to improve the MLA image quality. We train an end-to-end convolutional neural network on pairs of real ultrasound cardiac data, acquired through MLA and the corresponding single-line acquisition (SLA). The network achieves a significant improvement in image quality for both $5-$ and $7-$line MLA resulting in a decorrelation measure similar to that of SLA while having the frame rate of MLA.
High quality ultrasonic multi-line transmission through deep learning
Aug 23, 2018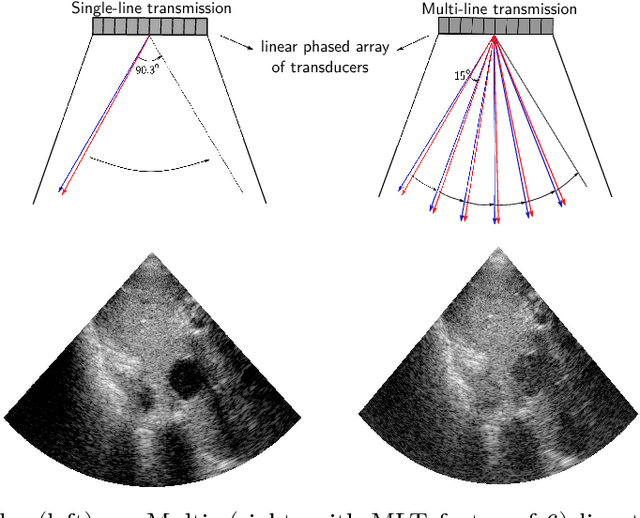
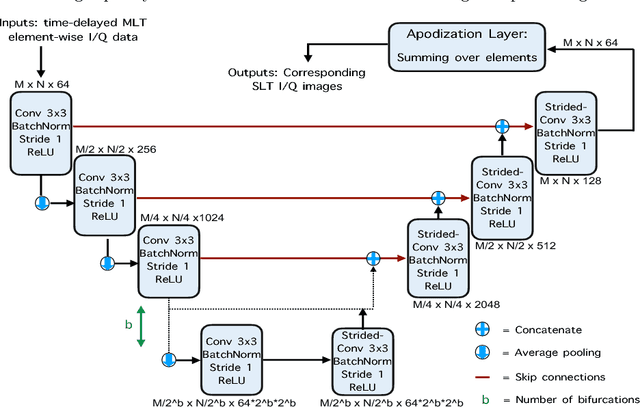
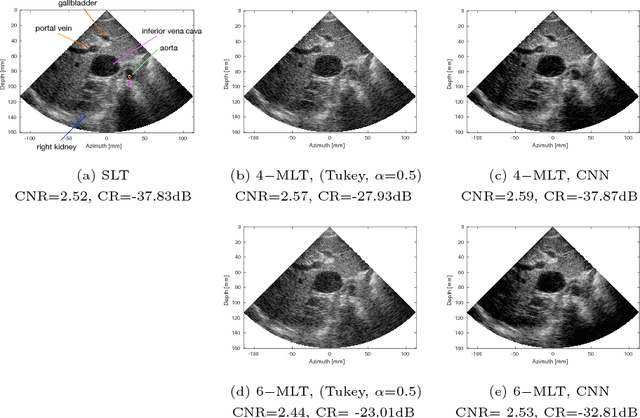
Frame rate is a crucial consideration in cardiac ultrasound imaging and 3D sonography. Several methods have been proposed in the medical ultrasound literature aiming at accelerating the image acquisition. In this paper, we consider one such method called \textit{multi-line transmission} (MLT), in which several evenly separated focused beams are transmitted simultaneously. While MLT reduces the acquisition time, it comes at the expense of a heavy loss of contrast due to the interactions between the beams (cross-talk artifact). In this paper, we introduce a data-driven method to reduce the artifacts arising in MLT. To this end, we propose to train an end-to-end convolutional neural network consisting of correction layers followed by a constant apodization layer. The network is trained on pairs of raw data obtained through MLT and the corresponding \textit{single-line transmission} (SLT) data. Experimental evaluation demonstrates significant improvement both in the visual image quality and in objective measures such as contrast ratio and contrast-to-noise ratio, while preserving resolution unlike traditional apodization-based methods. We show that the proposed method is able to generalize well across different patients and anatomies on real and phantom data.
Towards CT-quality Ultrasound Imaging using Deep Learning
Oct 17, 2017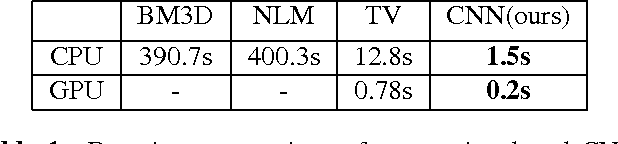



The cost-effectiveness and practical harmlessness of ultrasound imaging have made it one of the most widespread tools for medical diagnosis. Unfortunately, the beam-forming based image formation produces granular speckle noise, blurring, shading and other artifacts. To overcome these effects, the ultimate goal would be to reconstruct the tissue acoustic properties by solving a full wave propagation inverse problem. In this work, we make a step towards this goal, using Multi-Resolution Convolutional Neural Networks (CNN). As a result, we are able to reconstruct CT-quality images from the reflected ultrasound radio-frequency(RF) data obtained by simulation from real CT scans of a human body. We also show that CNN is able to imitate existing computationally heavy despeckling methods, thereby saving orders of magnitude in computations and making them amenable to real-time applications.
End to End Deep Neural Network Frequency Demodulation of Speech Signals
Oct 07, 2017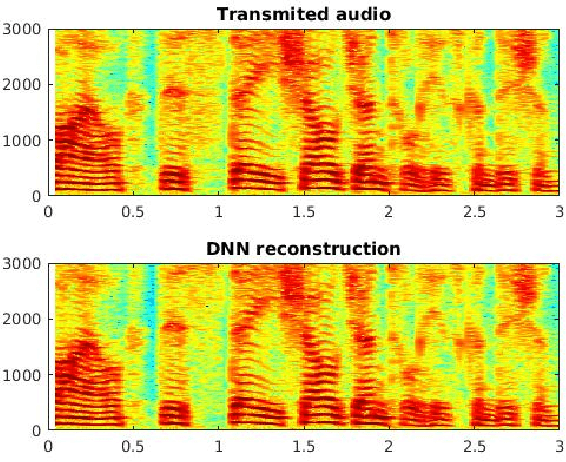
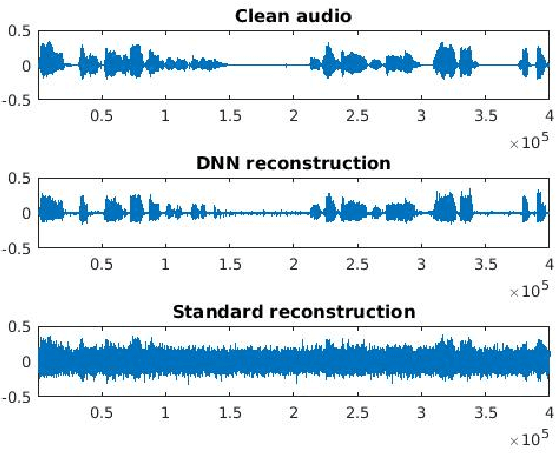
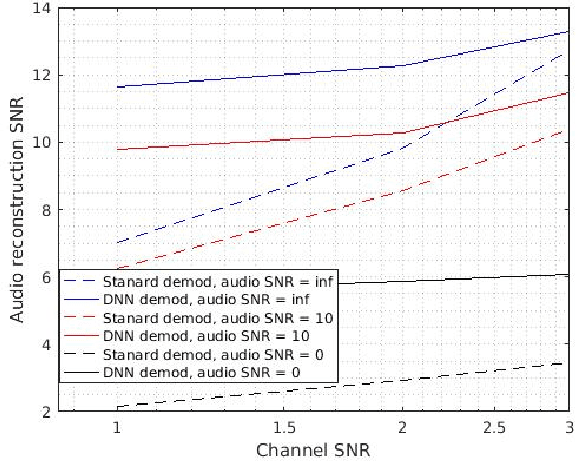
Frequency modulation (FM) is a form of radio broadcasting which is widely used nowadays and has been for almost a century. We suggest a software-defined-radio (SDR) receiver for FM demodulation that adopts an end-to-end learning based approach and utilizes the prior information of transmitted speech message in the demodulation process. The receiver detects and enhances speech from the in-phase and quadrature components of its base band version. The new system yields high performance detection for both acoustical disturbances, and communication channel noise and is foreseen to out-perform the established methods for low signal to noise ratio (SNR) conditions in both mean square error and in perceptual evaluation of speech quality score.