 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a quantitative assessment of neurodegeneration in Alzheimer's disease
Nov 06, 2020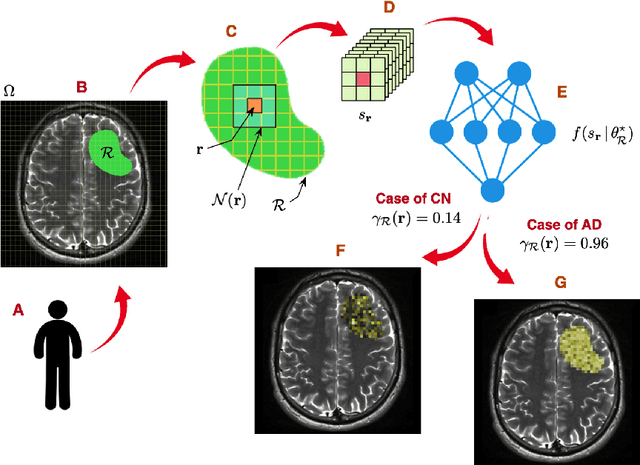

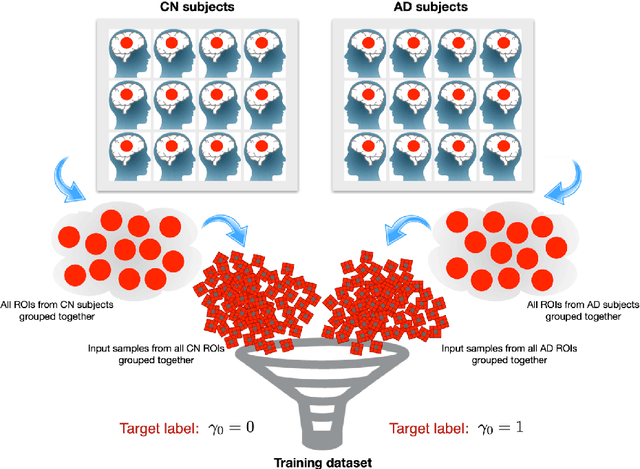

Alzheimer's disease (AD) is an irreversible neurodegenerative disorder that progressively destroys memory and other cognitive domains of the brain. While effective therapeutic management of AD is still in development, it seems reasonable to expect their prospective outcomes to depend on the severity of baseline pathology. For this reason, substantial research efforts have been invested in the development of effective means of non-invasive diagnosis of AD at its earliest possible stages. In pursuit of the same objective, the present paper addresses the problem of the quantitative diagnosis of AD by means of Diffusion Magnetic Resonance Imaging (dMRI). In particular, the paper introduces the notion of a pathology specific imaging contrast (PSIC), which, in addition to supplying a valuable diagnostic score, can serve as a means of visual representation of the spatial extent of neurodegeneration. The values of PSIC are computed by a dedicated deep neural network (DNN), which has been specially adapted to the processing of dMRI signals. Once available, such values can be used for several important purposes, including stratification of study subjects. In particular, experiments confirm the DNN-based classification can outperform a wide range of alternative approaches in application to the basic problem of stratification of cognitively normal (CN) and AD subjects. Notwithstanding its preliminary nature, this result suggests a strong rationale for further extension and improvement of the explorative methodology described in this paper.
Towards learned optimal q-space sampling in diffusion MRI
Sep 07, 2020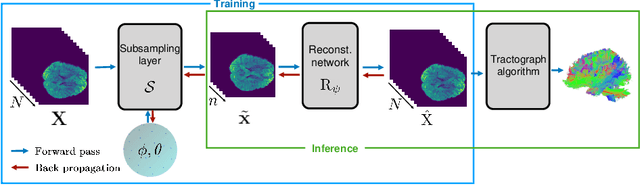

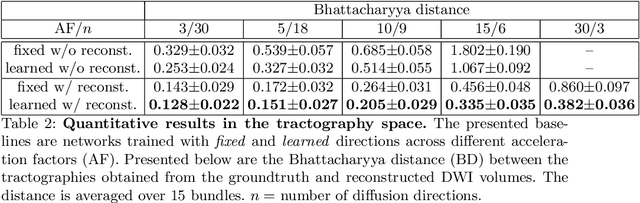

Fiber tractography is an important tool of computational neuroscience that enables reconstructing the spatial connectivity and organization of white matter of the brain. Fiber tractography takes advantage of diffusion Magnetic Resonance Imaging (dMRI) which allows measuring the apparent diffusivity of cerebral water along different spatial directions. Unfortunately, collecting such data comes at the price of reduced spatial resolution and substantially elevated acquisition times, which limits the clinical applicability of dMRI. This problem has been thus far addressed using two principal strategies. Most of the efforts have been extended towards improving the quality of signal estimation for any, yet fixed sampling scheme (defined through the choice of diffusion-encoding gradients). On the other hand, optimization over the sampling scheme has also proven to be effective. Inspired by the previous results, the present work consolidates the above strategies into a unified estimation framework, in which the optimization is carried out with respect to both estimation model and sampling design {\it concurrently}. The proposed solution offers substantial improvements in the quality of signal estimation as well as the accuracy of ensuing analysis by means of fiber tractography. While proving the optimality of the learned estimation models would probably need more extensive evaluation, we nevertheless claim that the learned sampling schemes can be of immediate use, offering a way to improve the dMRI analysis without the necessity of deploying the neural network used for their estimation. We present a comprehensive comparative analysis based on the Human Connectome Project data. Code and learned sampling designs aviliable at https://github.com/tomer196/Learned_dMRI.
PILOT: Physics-Informed Learned Optimal Trajectories for Accelerated MRI
Oct 03, 2019

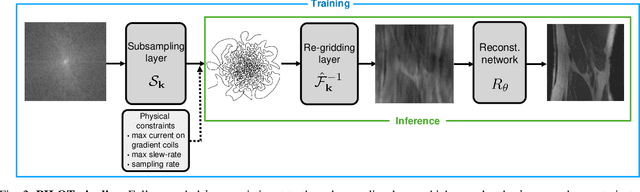
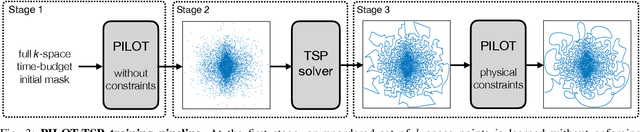
Magnetic Resonance Imaging (MRI) has long been considered to be among "the gold standards" of diagnostic medical imaging. The long acquisition times, however, render MRI prone to motion artifacts, let alone their adverse contribution to the relative high costs of MRI examination. Over the last few decades, multiple studies have focused on the development of both physical and post-processing methods for accelerated acquisition of MRI scans. These two approaches, however, have so far been addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of concurrent learning-based design of data acquisition and image reconstruction schemes. In this work, we propose a novel approach to the learning of optimal schemes for conjoint acquisition and reconstruction of MRI scans, with the optimization carried out simultaneously with respect to the time-efficiency of data acquisition and the quality of resulting reconstructions. To be of a practical value, the schemes are encoded in the form of general k-space trajectories, whose associated magnetic gradients are constrained to obey a set of predefined hardware requirements (as defined in terms of, e.g., peak currents and maximum slew rates of magnetic gradients). With this proviso in mind, we propose a novel algorithm for the end-to-end training of a combined acquisition-reconstruction pipeline using a deep neural network with differentiable forward- and back-propagation operators. We also demonstrate the effectiveness of the proposed solution in application to both image reconstruction and image segmentation, reporting substantial improvements in terms of acceleration factors as well as the quality of these end tasks.
Self-supervised learning of inverse problem solvers in medical imaging
May 22, 2019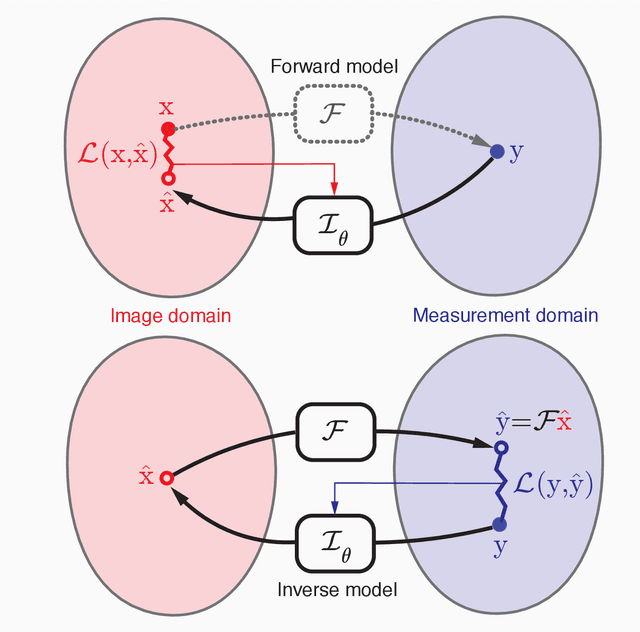
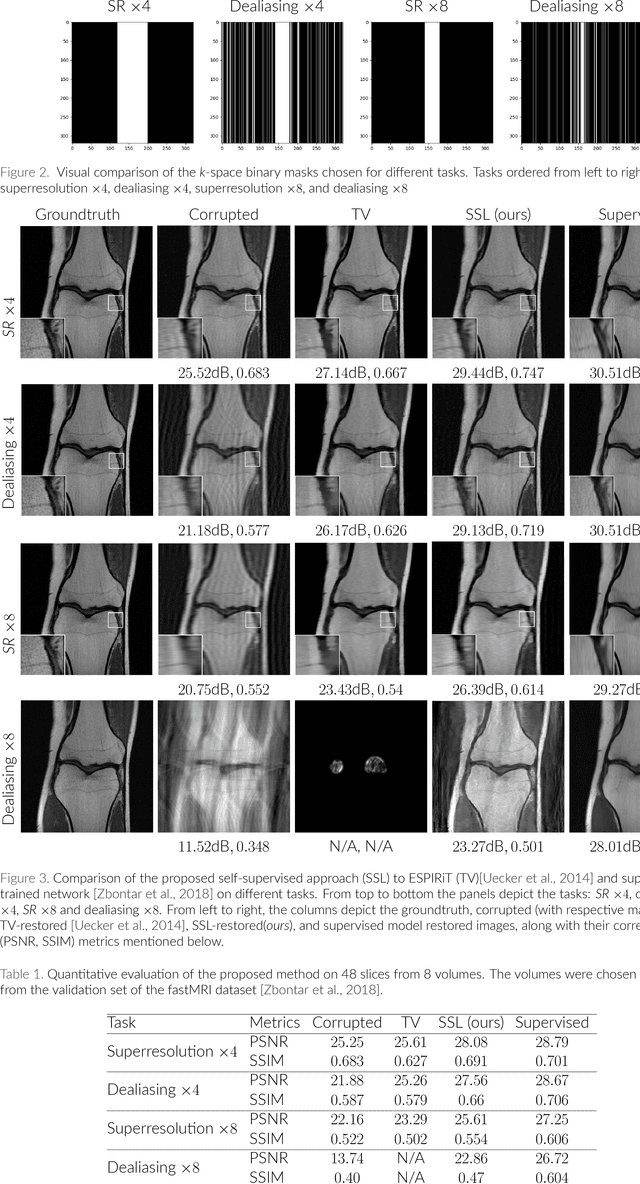
In the past few years, deep learning-based methods have demonstrated enormous success for solving inverse problems in medical imaging. In this work, we address the following question:\textit{Given a set of measurements obtained from real imaging experiments, what is the best way to use a learnable model and the physics of the modality to solve the inverse problem and reconstruct the latent image?} Standard supervised learning based methods approach this problem by collecting data sets of known latent images and their corresponding measurements. However, these methods are often impractical due to the lack of availability of appropriately sized training sets, and, more generally, due to the inherent difficulty in measuring the "groundtruth" latent image. In light of this, we propose a self-supervised approach to training inverse models in medical imaging in the absence of aligned data. Our method only requiring access to the measurements and the forward model at training. We showcase its effectiveness on inverse problems arising in accelerated magnetic resonance imaging (MRI).
Learning Fast Magnetic Resonance Imaging
May 22, 2019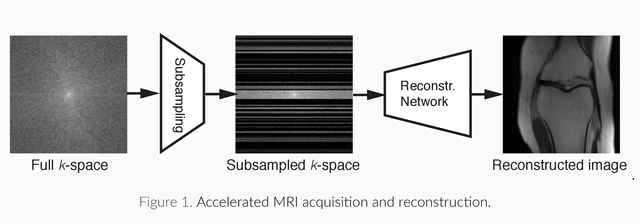

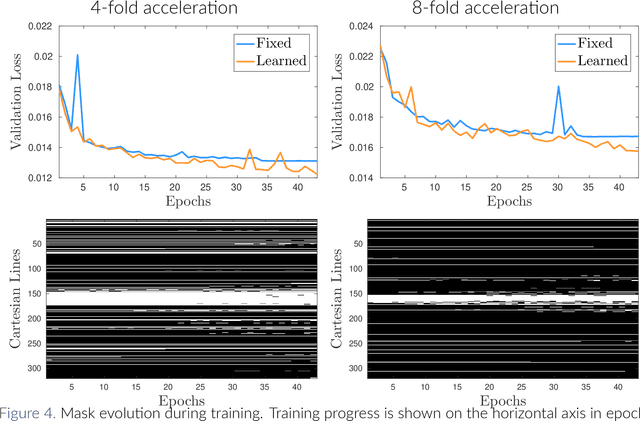
Magnetic Resonance Imaging (MRI) is considered today the golden-standard modality for soft tissues. The long acquisition times, however, make it more prone to motion artifacts as well as contribute to the relatively high costs of this examination. Over the years, multiple studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MRI, however, these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of the simultaneous learning-based design of the acquisition and reconstruction schemes manifesting significant improvement in the reconstruction quality with a constrained time budget. Inspired by these successes, in this work, we propose to learn accelerated MR acquisition schemes (in the form of Cartesian trajectories) jointly with the image reconstruction operator. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using the learned Cartesian trajectories at different speed up rates.
Learning beamforming in ultrasound imaging
Dec 19, 2018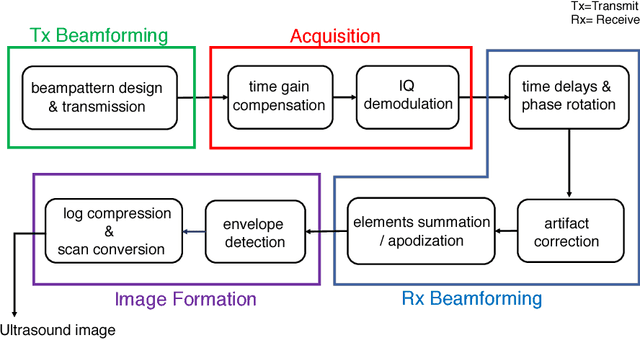



Medical ultrasound (US) is a widespread imaging modality owing its popularity to cost efficiency, portability, speed, and lack of harmful ionizing radiation. In this paper, we demonstrate that replacing the traditional ultrasound processing pipeline with a data-driven, learnable counterpart leads to significant improvement in image quality. Moreover, we demonstrate that greater improvement can be achieved through a learning-based design of the transmitted beam patterns simultaneously with learning an image reconstruction pipeline. We evaluate our method on an in-vivo first-harmonic cardiac ultrasound dataset acquired from volunteers and demonstrate the significance of the learned pipeline and transmit beam patterns on the image quality when compared to standard transmit and receive beamformers used in high frame-rate US imaging. We believe that the presented methodology provides a fundamentally different perspective on the classical problem of ultrasound beam pattern design.
High frame-rate cardiac ultrasound imaging with deep learning
Aug 23, 2018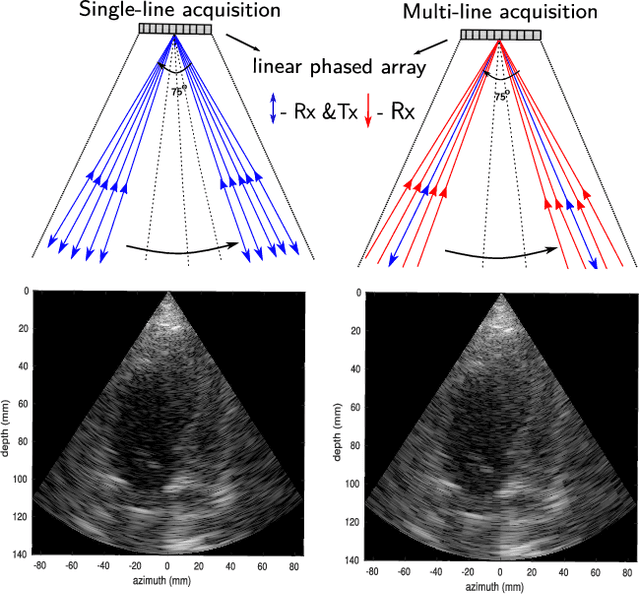

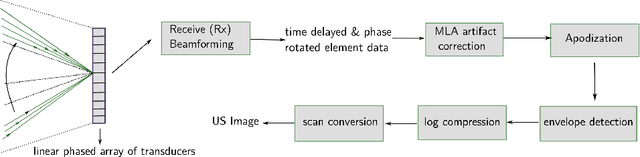

Cardiac ultrasound imaging requires a high frame rate in order to capture rapid motion. This can be achieved by multi-line acquisition (MLA), where several narrow-focused received lines are obtained from each wide-focused transmitted line. This shortens the acquisition time at the expense of introducing block artifacts. In this paper, we propose a data-driven learning-based approach to improve the MLA image quality. We train an end-to-end convolutional neural network on pairs of real ultrasound cardiac data, acquired through MLA and the corresponding single-line acquisition (SLA). The network achieves a significant improvement in image quality for both $5-$ and $7-$line MLA resulting in a decorrelation measure similar to that of SLA while having the frame rate of MLA.
High quality ultrasonic multi-line transmission through deep learning
Aug 23, 2018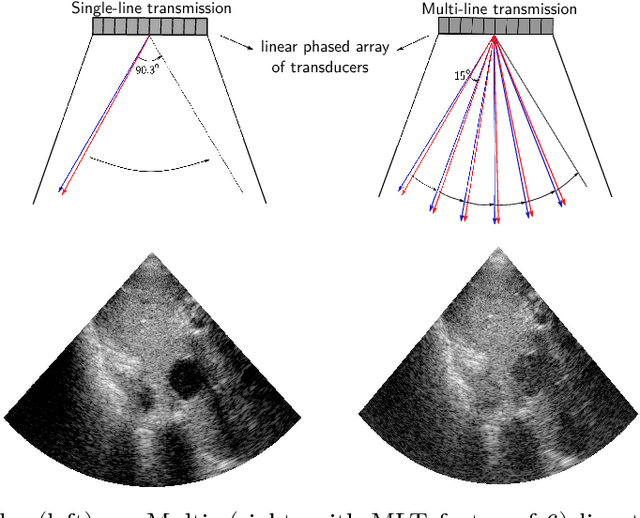
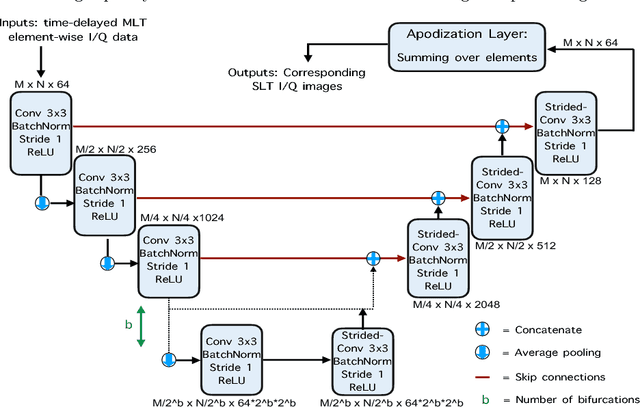
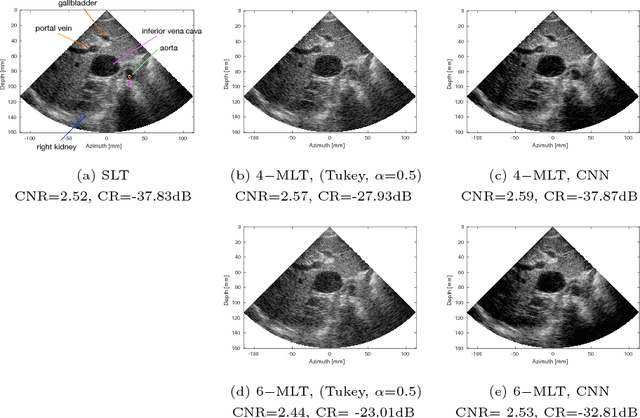
Frame rate is a crucial consideration in cardiac ultrasound imaging and 3D sonography. Several methods have been proposed in the medical ultrasound literature aiming at accelerating the image acquisition. In this paper, we consider one such method called \textit{multi-line transmission} (MLT), in which several evenly separated focused beams are transmitted simultaneously. While MLT reduces the acquisition time, it comes at the expense of a heavy loss of contrast due to the interactions between the beams (cross-talk artifact). In this paper, we introduce a data-driven method to reduce the artifacts arising in MLT. To this end, we propose to train an end-to-end convolutional neural network consisting of correction layers followed by a constant apodization layer. The network is trained on pairs of raw data obtained through MLT and the corresponding \textit{single-line transmission} (SLT) data. Experimental evaluation demonstrates significant improvement both in the visual image quality and in objective measures such as contrast ratio and contrast-to-noise ratio, while preserving resolution unlike traditional apodization-based methods. We show that the proposed method is able to generalize well across different patients and anatomies on real and phantom data.
Image Segmentation Using Weak Shape Priors
Jun 14, 2010



The problem of image segmentation is known to become particularly challenging in the case of partial occlusion of the object(s) of interest, background clutter, and the presence of strong noise. To overcome this problem, the present paper introduces a novel approach segmentation through the use of "weak" shape priors. Specifically, in the proposed method, an segmenting active contour is constrained to converge to a configuration at which its geometric parameters attain their empirical probability densities closely matching the corresponding model densities that are learned based on training samples. It is shown through numerical experiments that the proposed shape modeling can be regarded as "weak" in the sense that it minimally influences the segmentation, which is allowed to be dominated by data-related forces. On the other hand, the priors provide sufficient constraints to regularize the convergence of segmentation, while requiring substantially smaller training sets to yield less biased results as compared to the case of PCA-based regularization methods. The main advantages of the proposed technique over some existing alternatives is demonstrated in a series of experiments.
Regularized Richardson-Lucy Algorithm for Sparse Reconstruction of Poissonian Images
Apr 08, 2010



Restoration of digital images from their degraded measurements has always been a problem of great theoretical and practical importance in numerous applications of imaging sciences. A specific solution to the problem of image restoration is generally determined by the nature of degradation phenomenon as well as by the statistical properties of measurement noises. The present study is concerned with the case in which the images of interest are corrupted by convolutional blurs and Poisson noises. To deal with such problems, there exists a range of solution methods which are based on the principles originating from the fixed-point algorithm of Richardson and Lucy (RL). In this paper, we provide conceptual and experimental proof that such methods tend to converge to sparse solutions, which makes them applicable only to those images which can be represented by a relatively small number of non-zero samples in the spatial domain. Unfortunately, the set of such images is relatively small, which restricts the applicability of RL-type methods. On the other hand, virtually all practical images admit sparse representations in the domain of a properly designed linear transform. To take advantage of this fact, it is therefore tempting to modify the RL algorithm so as to make it recover representation coefficients, rather than the values of their associated image. Such modification is introduced in this paper. Apart from the generality of its assumptions, the proposed method is also superior to many established reconstruction approaches in terms of estimation accuracy and computational complexity. This and other conclusions of this study are validated through a series of numerical experiments.