 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture-Aware Generalization Bounds for Temporal Networks: Theory and Fair Comparison Methodology
Aug 08, 2025Deep temporal architectures such as Temporal Convolutional Networks (TCNs) achieve strong predictive performance on sequential data, yet theoretical understanding of their generalization remains limited. We address this gap by providing both the first non-vacuous, architecture-aware generalization bounds for deep temporal models and a principled evaluation methodology. For exponentially $\beta$-mixing sequences, we derive bounds scaling as $ O\!\Bigl(R\,\sqrt{\tfrac{D\,p\,n\,\log N}{N}}\Bigr), $ where $D$ is network depth, $p$ kernel size, $n$ input dimension, and $R$ weight norm. Our delayed-feedback blocking mechanism transforms dependent samples into effectively independent ones while discarding only $O(1/\log N)$ of the data, yielding $\sqrt{D}$ scaling instead of exponential, implying that doubling depth requires approximately quadrupling the training data. We also introduce a fair-comparison methodology that fixes the effective sample size to isolate the effect of temporal structure from information content. Under $N_{\text{eff}}=2{,}000$, strongly dependent sequences ($\rho=0.8$) exhibit $\approx76\%$ smaller generalization gaps than weakly dependent ones ($\rho=0.2$), challenging the intuition that dependence is purely detrimental. Yet convergence rates diverge from theory: weak dependencies follow $N_{\text{eff}}^{-1.21}$ scaling and strong dependencies follow $N_{\text{eff}}^{-0.89}$, both steeper than the predicted $N^{-0.5}$. These findings reveal that temporal dependence can enhance learning under fixed information budgets, while highlighting gaps between theory and practice that motivate future research.
Representing local protein environments with atomistic foundation models
May 29, 2025The local structure of a protein strongly impacts its function and interactions with other molecules. Therefore, a concise, informative representation of a local protein environment is essential for modeling and designing proteins and biomolecular interactions. However, these environments' extensive structural and chemical variability makes them challenging to model, and such representations remain under-explored. In this work, we propose a novel representation for a local protein environment derived from the intermediate features of atomistic foundation models (AFMs). We demonstrate that this embedding effectively captures both local structure (e.g., secondary motifs), and chemical features (e.g., amino-acid identity and protonation state). We further show that the AFM-derived representation space exhibits meaningful structure, enabling the construction of data-driven priors over the distribution of biomolecular environments. Finally, in the context of biomolecular NMR spectroscopy, we demonstrate that the proposed representations enable a first-of-its-kind physics-informed chemical shift predictor that achieves state-of-the-art accuracy. Our results demonstrate the surprising effectiveness of atomistic foundation models and their emergent representations for protein modeling beyond traditional molecular simulations. We believe this will open new lines of work in constructing effective functional representations for protein environments.
From Lab to Wrist: Bridging Metabolic Monitoring and Consumer Wearables for Heart Rate and Oxygen Consumption Modeling
Apr 30, 2025Understanding physiological responses during running is critical for performance optimization, tailored training prescriptions, and athlete health management. We introduce a comprehensive framework -- what we believe to be the first capable of predicting instantaneous oxygen consumption (VO$_{2}$) trajectories exclusively from consumer-grade wearable data. Our approach employs two complementary physiological models: (1) accurate modeling of heart rate (HR) dynamics via a physiologically constrained ordinary differential equation (ODE) and neural Kalman filter, trained on over 3 million HR observations, achieving 1-second interval predictions with mean absolute errors as low as 2.81\,bpm (correlation 0.87); and (2) leveraging the principles of precise HR modeling, a novel VO$_{2}$ prediction architecture requiring only the initial second of VO$_{2}$ data for calibration, enabling robust, sequence-to-sequence metabolic demand estimation. Despite relying solely on smartwatch and chest-strap data, our method achieves mean absolute percentage errors of approximately 13\%, effectively capturing rapid physiological transitions and steady-state conditions across diverse running intensities. Our synchronized dataset, complemented by blood lactate measurements, further lays the foundation for future noninvasive metabolic zone identification. By embedding physiological constraints within modern machine learning, this framework democratizes advanced metabolic monitoring, bridging laboratory-grade accuracy and everyday accessibility, thus empowering both elite athletes and recreational fitness enthusiasts.
Estimating the Number of HTTP/3 Responses in QUIC Using Deep Learning
Oct 08, 2024QUIC, a new and increasingly used transport protocol, enhances TCP by providing better security, performance, and features like stream multiplexing. These features, however, also impose challenges for network middle-boxes that need to monitor and analyze web traffic. This paper proposes a novel solution for estimating the number of HTTP/3 responses in a given QUIC connection by an observer. This estimation reveals server behavior, client-server interactions, and data transmission efficiency, which is crucial for various applications such as designing a load balancing solution and detecting HTTP/3 flood attacks. The proposed scheme transforms QUIC connection traces into a sequence of images and trains machine learning (ML) models to predict the number of responses. Then, by aggregating images of a QUIC connection, an observer can estimate the total number of responses. As the problem is formulated as a discrete regression problem, we introduce a dedicated loss function. The proposed scheme is evaluated on a dataset of over seven million images, generated from $100,000$ traces collected from over $44,000$ websites over a four-month period, from various vantage points. The scheme achieves up to 97\% cumulative accuracy in both known and unknown web server settings and 92\% accuracy in estimating the total number of responses in unseen QUIC traces.
Beyond the Alphabet: Deep Signal Embedding for Enhanced DNA Clustering
Oct 08, 2024



The emerging field of DNA storage employs strands of DNA bases (A/T/C/G) as a storage medium for digital information to enable massive density and durability. The DNA storage pipeline includes: (1) encoding the raw data into sequences of DNA bases; (2) synthesizing the sequences as DNA \textit{strands} that are stored over time as an unordered set; (3) sequencing the DNA strands to generate DNA \textit{reads}; and (4) deducing the original data. The DNA synthesis and sequencing stages each generate several independent error-prone duplicates of each strand which are then utilized in the final stage to reconstruct the best estimate for the original strand. Specifically, the reads are first \textit{clustered} into groups likely originating from the same strand (based on their similarity to each other), and then each group approximates the strand that led to the reads of that group. This work improves the DNA clustering stage by embedding it as part of the DNA sequencing. Traditional DNA storage solutions begin after the DNA sequencing process generates discrete DNA reads (A/T/C/G), yet we identify that there is untapped potential in using the raw signals generated by the Nanopore DNA sequencing machine before they are discretized into bases, a process known as \textit{basecalling}, which is done using a deep neural network. We propose a deep neural network that clusters these signals directly, demonstrating superior accuracy, and reduced computation times compared to current approaches that cluster after basecalling.
Automatic Identification and Visualization of Group Training Activities Using Wearable Data
Oct 07, 2024Human Activity Recognition (HAR) identifies daily activities from time-series data collected by wearable devices like smartwatches. Recent advancements in Internet of Things (IoT), cloud computing, and low-cost sensors have broadened HAR applications across fields like healthcare, biometrics, sports, and personal fitness. However, challenges remain in efficiently processing the vast amounts of data generated by these devices and developing models that can accurately recognize a wide range of activities from continuous recordings, without relying on predefined activity training sessions. This paper presents a comprehensive framework for imputing, analyzing, and identifying activities from wearable data, specifically targeting group training scenarios without explicit activity sessions. Our approach is based on data collected from 135 soldiers wearing Garmin 55 smartwatches over six months. The framework integrates multiple data streams, handles missing data through cross-domain statistical methods, and identifies activities with high accuracy using machine learning (ML). Additionally, we utilized statistical analysis techniques to evaluate the performance of each individual within the group, providing valuable insights into their respective positions in the group in an easy-to-understand visualization. These visualizations facilitate easy understanding of performance metrics, enhancing group interactions and informing individualized training programs. We evaluate our framework through traditional train-test splits and out-of-sample scenarios, focusing on the model's generalization capabilities. Additionally, we address sleep data imputation without relying on ML, improving recovery analysis. Our findings demonstrate the potential of wearable data for accurately identifying group activities, paving the way for intelligent, data-driven training solutions.
Vector Quantile Regression on Manifolds
Jul 03, 2023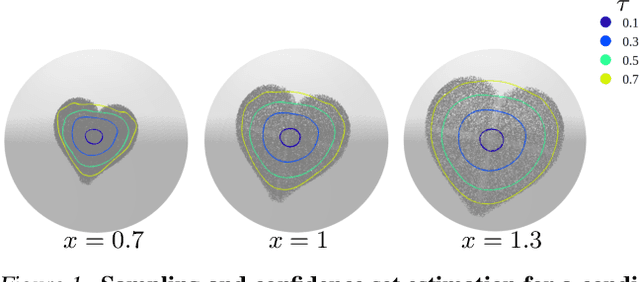
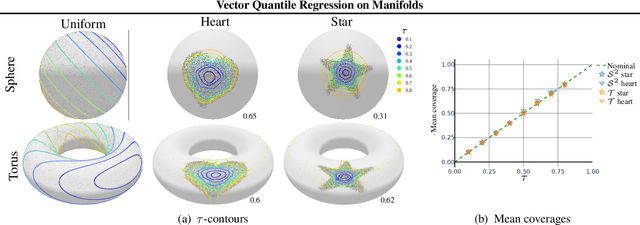
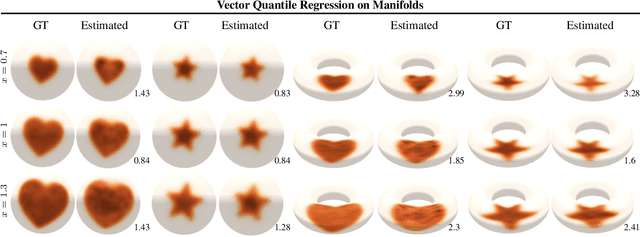
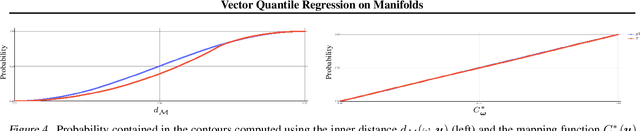
Quantile regression (QR) is a statistical tool for distribution-free estimation of conditional quantiles of a target variable given explanatory features. QR is limited by the assumption that the target distribution is univariate and defined on an Euclidean domain. Although the notion of quantiles was recently extended to multi-variate distributions, QR for multi-variate distributions on manifolds remains underexplored, even though many important applications inherently involve data distributed on, e.g., spheres (climate measurements), tori (dihedral angles in proteins), or Lie groups (attitude in navigation). By leveraging optimal transport theory and the notion of $c$-concave functions, we meaningfully define conditional vector quantile functions of high-dimensional variables on manifolds (M-CVQFs). Our approach allows for quantile estimation, regression, and computation of conditional confidence sets. We demonstrate the approach's efficacy and provide insights regarding the meaning of non-Euclidean quantiles through preliminary synthetic data experiments.
Designing Nonlinear Photonic Crystals for High-Dimensional Quantum State Engineering
Apr 13, 2023



We propose a novel, physically-constrained and differentiable approach for the generation of D-dimensional qudit states via spontaneous parametric down-conversion (SPDC) in quantum optics. We circumvent any limitations imposed by the inherently stochastic nature of the physical process and incorporate a set of stochastic dynamical equations governing its evolution under the SPDC Hamiltonian. We demonstrate the effectiveness of our model through the design of structured nonlinear photonic crystals (NLPCs) and shaped pump beams; and show, theoretically and experimentally, how to generate maximally entangled states in the spatial degree of freedom. The learning of NLPC structures offers a promising new avenue for shaping and controlling arbitrary quantum states and enables all-optical coherent control of the generated states. We believe that this approach can readily be extended from bulky crystals to thin Metasurfaces and potentially applied to other quantum systems sharing a similar Hamiltonian structures, such as superfluids and superconductors.
Deep Reinforcement Learning for Scheduling and Power Allocation in a 5G Urban Mesh
Oct 04, 2022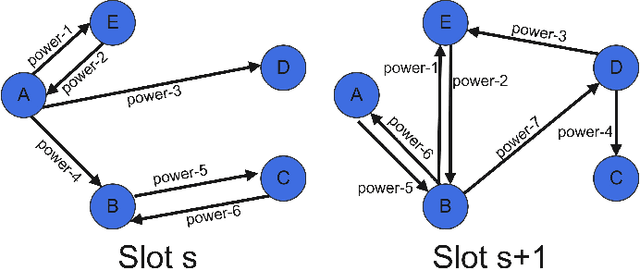
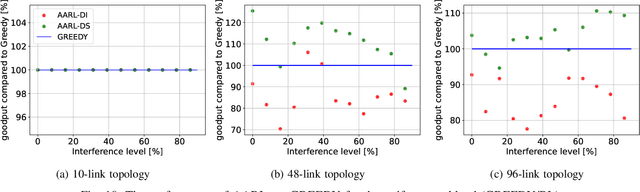
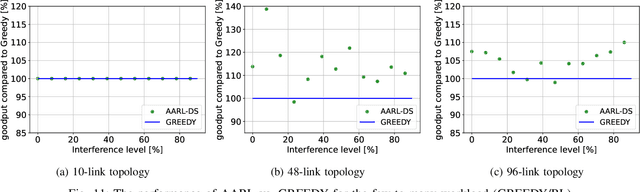
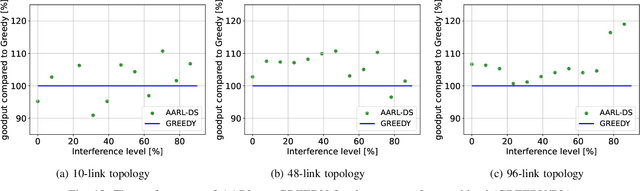
We study the problem of routing and scheduling of real-time flows over a multi-hop millimeter wave (mmWave) mesh. We develop a model-free deep reinforcement learning algorithm that determines which subset of the mmWave links should be activated during each time slot and using what power level. The proposed algorithm, called Adaptive Activator RL (AARL), can handle a variety of network topologies, network loads, and interference models, as well as adapt to different workloads. We demonstrate the operation of AARL on several topologies: a small topology with 10 links, a moderately-sized mesh with 48 links, and a large topology with 96 links. For each topology, the results of AARL are compared to those of a greedy scheduling algorithm. AARL is shown to outperform the greedy algorithm in two aspects. First, its schedule obtains higher goodput. Second, and even more importantly, while the run time of the greedy algorithm renders it impractical for real-time scheduling, the run time of AARL is suitable for meeting the time constraints of typical 5G networks.
Transformer Vs. MLP-Mixer Exponential Expressive Gap For NLP Problems
Aug 17, 2022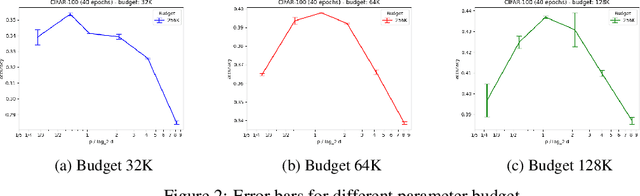
Vision-Transformers are widely used in various vision tasks. Meanwhile, there is another line of works starting with the MLP-mixer trying to achieve similar performance using mlp-based architectures. Interestingly, until now none reported using them for NLP tasks, additionally until now non of those mlp-based architectures claimed to achieve state-of-the-art in vision tasks. In this paper, we analyze the expressive power of mlp-based architectures in modeling dependencies between multiple different inputs simultaneously, and show an exponential gap between the attention and the mlp-based mechanisms. Our results suggest a theoretical explanation for the mlp inability to compete with attention-based mechanisms in NLP problems, they also suggest that the performance gap in vision tasks may be due to the mlp relative weakness in modeling dependencies between multiple different locations, and that combining smart input permutations to the mlp architectures may not suffice alone to close the performance gap.