 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized and Asymmetric Multi-Agent Learning in Construction Sites
Sep 16, 2024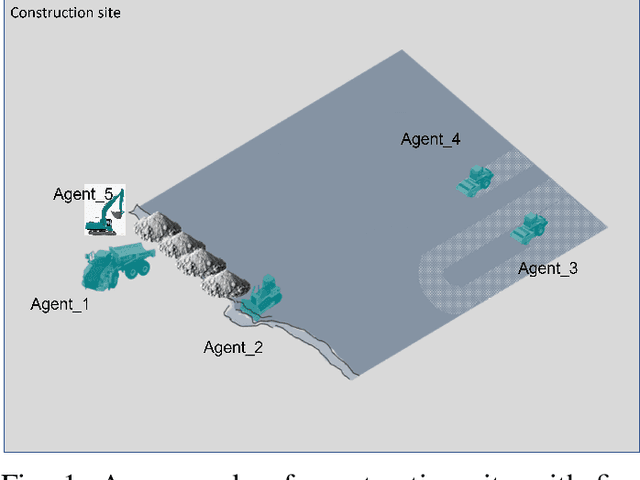
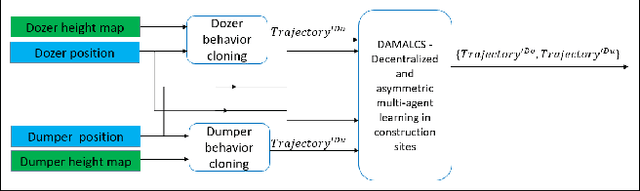
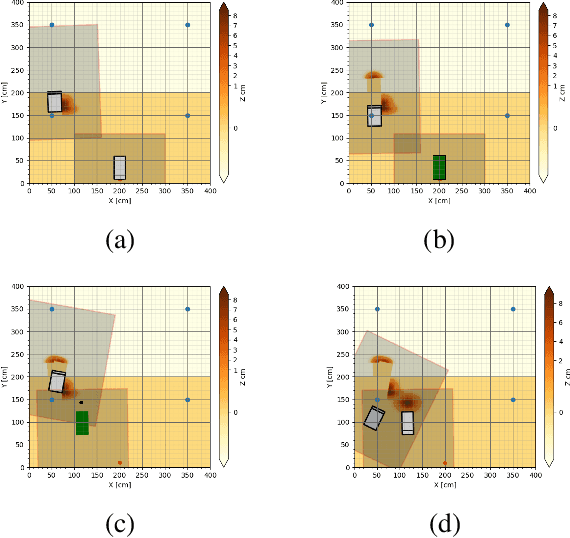
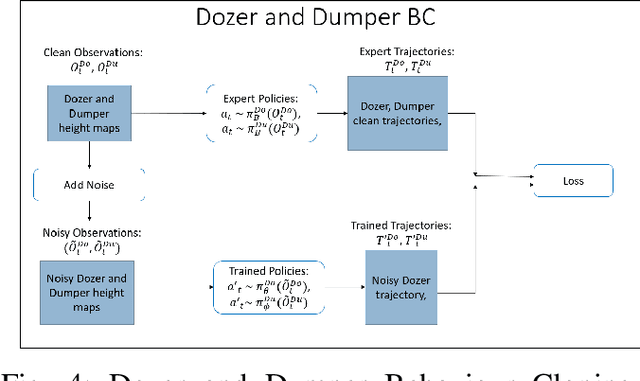
Multi-agent collaboration involves multiple participants working together in a shared environment to achieve a common goal. These agents share information, divide tasks, and synchronize their actions. Key aspects of multi agent collaboration include coordination, communication, task allocation, cooperation, adaptation, and decentralization. On construction sites, surface grading is the process of leveling sand piles to increase a specific area's height. In this scenario, a bulldozer grades while a dumper allocates sand piles. Our work aims to utilize a multi-agent approach to enable these vehicles to collaborate effectively. To this end, we propose a decentralized and asymmetric multi-agent learning approach for construction sites (DAMALCS). We formulate DAMALCS to reduce expected collisions for operating vehicles. Therefore, we develop two heuristic experts capable of achieving their joint goal optimally by applying an innovative prioritization method. In this approach, the bulldozer's movements take precedence over the dumper's operations, enabling the bulldozer to clear the path for the dumper and ensure continuous operation of both vehicles. Since heuristics alone are insufficient in real-world scenarios, we utilize them to train AI agents, which proves to be highly effective. We simultaneously train the bulldozer and dumper agents to operate within the same environment, aiming to avoid collisions and optimize performance in terms of time efficiency and sand volume handling. Our trained agents and heuristics are evaluated in both simulation and real-world lab experiments, testing them under various conditions, such as visual noise and localization errors. The results demonstrate that our approach significantly reduces collision rates for these vehicles.
Transformer Vs. MLP-Mixer Exponential Expressive Gap For NLP Problems
Aug 17, 2022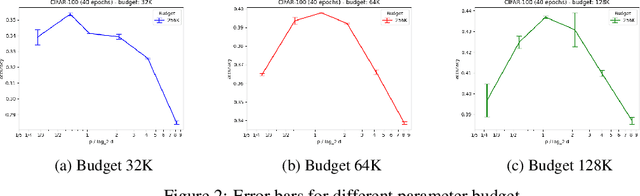
Vision-Transformers are widely used in various vision tasks. Meanwhile, there is another line of works starting with the MLP-mixer trying to achieve similar performance using mlp-based architectures. Interestingly, until now none reported using them for NLP tasks, additionally until now non of those mlp-based architectures claimed to achieve state-of-the-art in vision tasks. In this paper, we analyze the expressive power of mlp-based architectures in modeling dependencies between multiple different inputs simultaneously, and show an exponential gap between the attention and the mlp-based mechanisms. Our results suggest a theoretical explanation for the mlp inability to compete with attention-based mechanisms in NLP problems, they also suggest that the performance gap in vision tasks may be due to the mlp relative weakness in modeling dependencies between multiple different locations, and that combining smart input permutations to the mlp architectures may not suffice alone to close the performance gap.
Random Search Hyper-Parameter Tuning: Expected Improvement Estimation and the Corresponding Lower Bound
Aug 17, 2022Hyperparameter tuning is a common technique for improving the performance of neural networks. Most techniques for hyperparameter search involve an iterated process where the model is retrained at every iteration. However, the expected accuracy improvement from every additional search iteration, is still unknown. Calculating the expected improvement can help create stopping rules for hyperparameter tuning and allow for a wiser allocation of a project's computational budget. In this paper, we establish an empirical estimate for the expected accuracy improvement from an additional iteration of hyperparameter search. Our results hold for any hyperparameter tuning method which is based on random search \cite{bergstra2012random} and samples hyperparameters from a fixed distribution. We bound our estimate with an error of $O\left(\sqrt{\frac{\log k}{k}}\right)$ w.h.p. where $k$ is the current number of iterations. To the best of our knowledge this is the first bound on the expected gain from an additional iteration of hyperparameter search. Finally, we demonstrate that the optimal estimate for the expected accuracy will still have an error of $\frac{1}{k}$.
The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design
Oct 25, 2021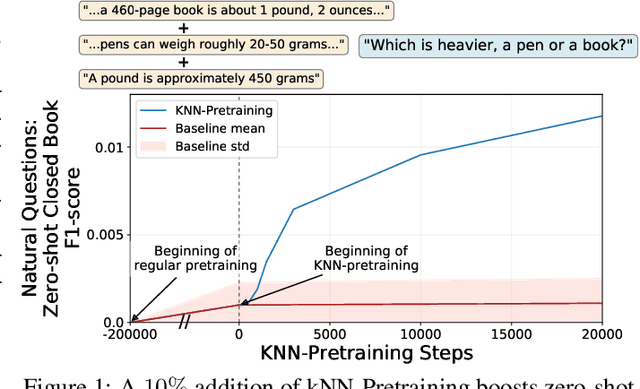

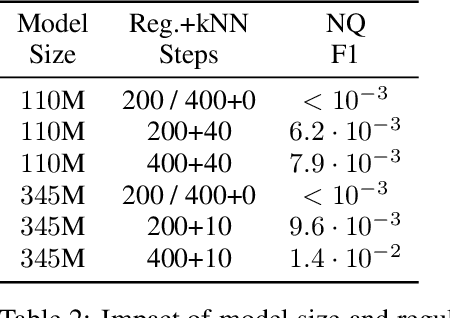
Pretraining Neural Language Models (NLMs) over a large corpus involves chunking the text into training examples, which are contiguous text segments of sizes processable by the neural architecture. We highlight a bias introduced by this common practice: we prove that the pretrained NLM can model much stronger dependencies between text segments that appeared in the same training example, than it can between text segments that appeared in different training examples. This intuitive result has a twofold role. First, it formalizes the motivation behind a broad line of recent successful NLM training heuristics, proposed for the pretraining and fine-tuning stages, which do not necessarily appear related at first glance. Second, our result clearly indicates further improvements to be made in NLM pretraining for the benefit of Natural Language Understanding tasks. As an example, we propose "kNN-Pretraining": we show that including semantically related non-neighboring sentences in the same pretraining example yields improved sentence representations and open domain question answering abilities. This theoretically motivated degree of freedom for "pretraining example design" indicates new training schemes for self-improving representations.