 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Vs. MLP-Mixer Exponential Expressive Gap For NLP Problems
Paper and Code
Aug 17, 2022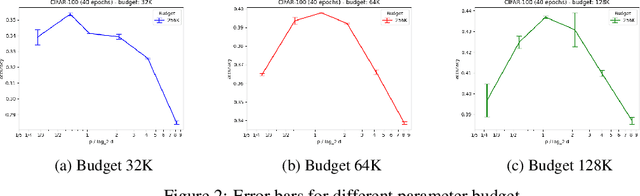
Vision-Transformers are widely used in various vision tasks. Meanwhile, there is another line of works starting with the MLP-mixer trying to achieve similar performance using mlp-based architectures. Interestingly, until now none reported using them for NLP tasks, additionally until now non of those mlp-based architectures claimed to achieve state-of-the-art in vision tasks. In this paper, we analyze the expressive power of mlp-based architectures in modeling dependencies between multiple different inputs simultaneously, and show an exponential gap between the attention and the mlp-based mechanisms. Our results suggest a theoretical explanation for the mlp inability to compete with attention-based mechanisms in NLP problems, they also suggest that the performance gap in vision tasks may be due to the mlp relative weakness in modeling dependencies between multiple different locations, and that combining smart input permutations to the mlp architectures may not suffice alone to close the performance gap.